Author's abstract of masters' work
on a theme "The Analysis and Estimation of Efficiency of Parallel Difference Methods of Solution the ODE on a Cluster"
Author: Dmitriy Zavalkin, undergraduate
Donetsk National Technical University
e-mail: dimzav@gmail.com [dimzav at gmail dot com]
Scientific adviser: Ph.D. Lev Feldman, professor
Donetsk National Technical University
Ukraine, 83001, Donetsk, Artema street, 66.
тел. (062)3010856, e-mail: feldman@r5.dgtu.donetsk.ua
The Analysis and Estimation of Efficiency of Parallel Difference Methods of Solution the ODE on a Cluster
The problems generating the ODE, currency of parallel methods of their solution
Modelling of the real economic, engineering and other processes described by systems of the ordinary differential equations (SODA) of the big dimension, represents an extensive class of problems for which solution application of high-efficiency computer facilities not only is justified, but also it is necessary. The well-known list of problems testifies to it "Grand Challenge" in which such problems occupy one of leading places. As outcome, there was a problem of creation new, high-precision (10-15 – 10-20) methods of numerical integration of such systems.As outcome, there was a problem of creation new, high-precision (10-15 - 10-20) methods of numerical integration of such systems. The traditional approach to a solution of this problem, namely application of explicit methods of Runge-Kutty of high usages is ineffective because of a multiple evaluation of right halfs of the differential equations [1,2]. The methods of numerical integration using the "higher" derivatives, also call difficulties as in real problems not always it is possible to calculate derivatives analytically. Thanks to computer facilities rapid development last years there was a possibility to use more then one computers simultaneously for a solution of one problem, it has generated a problem of construction of parallel analogues for known consecutive algorithms. Particularly, many algorithms successfully used in consecutive evaluations, appear not applicable at carrying out of parallel evaluations. From here necessity of construction of the special methods adapted for computing systems with parallel architecture implies, the parallelizing of evaluations in existing consecutive methods does not give the big prize from use instead of one computer of several. Thus it is necessary to consider, that the method should possess a numerical stability and have optimum for preservation of efficiency structure. To the given requirements satisfy block methods [3].
In block methods for the block from k points new k values of function are calculated simultaneously, that will quite agree with architecture of parallel computing systems. Such principle allows to calculate factors of difference formulas not in the course of integration, and at a method development cycle, that considerably increases efficiency of the account. At the same time for block methods there are no estimations of errors and a convergence condition.
Consecutive method
In general, methods Runge-Kutta record in the form
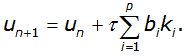
Here:
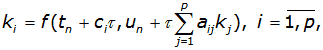
![]() – константы
– константы
The number p, indicating the number of subsidiary points kj, used for calculating the main point of ki, called the method order.

Figure 1 – The solution scheme for the classical formula Runge-Kutty of 4th order of accuracy
(Animation, 7 frames, 10.7 Kb. If you want to repeat animation you must reload page)
Parallel one-step methods
Let's consider a Cauchy problem solution
![]() f(t,x), x(t0) = x0 (1)
f(t,x), x(t0) = x0 (1)
by a k-pointwise block difference method. Set M of points of a uniform grid tm, m=1,2,…,M andtM=T with step
 divide on N the blocks containing on k of points, thus kN ≥ M. In each block we work in point number i =0,1,…,k and denote by tn,i a point of n block with number i. A point tn,0 call starting block n, andtn,k – the end of the block. Obviously, there is tn,k = tn+1,0 . Terms of the start point in the block does not include [2].
divide on N the blocks containing on k of points, thus kN ≥ M. In each block we work in point number i =0,1,…,k and denote by tn,i a point of n block with number i. A point tn,0 call starting block n, andtn,k – the end of the block. Obviously, there is tn,k = tn+1,0 . Terms of the start point in the block does not include [2].

![]()
Figure 2 – The scheme of splitting into blocks M points set a uniform grid tm
If for calculating values in the new block is used only last point of preceding block – the block method is considered one-step, and if all points of the previous block – multistep.

Figure 3 – Template of the difference scheme of an one-step block method
В общем случае уравнения одношаговых разностных методов для блока из k точек с учетом введенных обозначений можно записать в виде
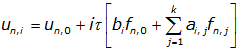 (2)
(2)
![]()
![]() – point number
– point number
![]()
![]() – step number
– step number
For a solution of the received nonlinear set of equations it is possible to use:
- an iterative method;
- Newton's method.
To draw a conclusion on appropriateness of realisation and the advantage received at application of a parallel method it is necessary to know its acceleration and parallelism factor.
Introduce the symbols::
tf – time to calculate value of function f(t,x);
tсл – time to perform addition operation;
tум – time to perform multiplication operation;
tоб – time of transmission one number to the next processor.
Evaluation time for one processor with accuracy O(τk+1) in all k nodes of block by Runge-Kutta formulas k+1 an accuracy order is equal
![]() (3)
(3)
Time of a parallel evaluation on k processors of the approached values of a solution in all k nodes of block equals
![]() (4)
(4)
Then acceleration of parallel one-step k-point algorithm equals
![]() (5)
(5)
The effectiveness ratio of parallel algorithm is calculated by the formula
![]() (6)
(6)
Here Nпроц – an amount of used processor elements. In our case
![]() (7)
(7)
Therefore
![]() (8)
(8)
The implementation of parallel methods in gridMathematica (Parallel Computing Toolkit)
The implementation of algorithms for parallel programming language – laborious task, and more complex algorithm, the more difficult to realize optimal way. Therefore, in order to simplify the implementation of parallel algorithms have been developed special library containing the optimal implementation of many routine operations, for example, a parallel set of addition and subtraction of numbers. The most famous library of parallel programming - MPI, supports many programming languages, provides high speed received at the end of the development program, but time to implement a complex algorithm can reach a several month. However, there is a library Parallel Computing Toolkit, developed by Wolfram Research, which allows implementing parallel algorithms in the language of Mathematica, which focuses on character and numerical computations and for that reason is more attractive to the realization of numerical mathematical algorithms, languages than C++ and Fortran, which more often all realize numerical algorithms using the library MPI.
Let's give an example a parallel solution of a simple problem in language Mathematica with library Parallel Computing Toolkit use. For this purpose we take an one-step four-point block method and parallelize an evaluation of right halfs the ODE (fig. 4). We will construct the graph of association of time of performance of algorithm from an amount of used processors (fig. 5). As a test problem we will consider a solution of moderately stiffly problem x' = - 10(t-1)x, x(0)=1.
Einschrit[k_,A_,B_,a_,b_]:=Block[{ai,v,q,V,Q,QI},
Array[b,k];
Array[v,k];
Array[q,{k,k}];
Array[a,{k,k}];
Do[Do[q[l-1,j]=j^(l-1),{j,1,k}],{l,2,k+1}];
Q=Array[q,{k,k}];
QI=Inverse[Q];
Do[Do[v[l-1]=i^(l-1)/l,{l,2,k+1}];
V=Array[v,k];
ai=QI.V;
Do[a[i,j]=ai[[j]],{j,1,k}],{i,1,k}];
Do[b[i]=1;Do[b[i]=b[i]-a[i,j],{j,1,k}],{i,1,k}];
B=Array[b,k];
A=Array[a,{k,k}]
];
f[t_,x_]:=-10*(t-1)*x;
Clear[a,b,A,B]
Einschrit[4,A,B,a,b];
Needs["Parallel`"];
maxSlaves=4;
timespent=Table[0,{maxSlaves}];
For[ii=1,ii≤maxSlaves,ii++,LaunchSlave["localhost",$mathkernel];
starttime=AbsoluteTime[];
k=4;q=30;n=(q+l)*k;t0=0;u0=1;tau=0.0174;l=6;
Array[w,{n,2},0];
fn=f[t0,u0];
un=u0;
tn=t0;
w[0,0]=t0;
w[0,1]=u0;
ie=ParallelTable[1,{i,k}];
Array[g, {k, k + 1}];
Do[Do[g[i, j +1] = i*a[i, j], {j, 1, k}], {i, k}];
Do[g[i, 1] =i*B[[i]], {i, k}];
G =Array[g, {k, k+ 1}];
Do[U = ParallelTable[un + i*tau*fn, {i, 0, k}];
Do[F = ParallelTable[f[tn + i*tau,un + i*tau*fn], {i, 0, k}];
V = un*ie + tau*G. F; U = Prepend [V, un], {j , l}];
r=s*k;
Do[w[r + i, 0] = tn + i*tau;w[r+i,1] =V[[i]], {i, k}];
un = V [[k]] ; tn = tn + k*tau; fn = f[tn, un] , {s , 0, q}] ;
timespent[[ii]]=AbsoluteTime[]-starttime;
];
CloseSlaves[];
Figure 4 – Example of parallel implementation of one-step four-point method

Figure 5 – Diagram of run-time algorithm depending on the number of processors
For this simple task and of the parallel algorithm, we see that use multiple processors does not win over time, the time solving the problem increasing only by the time spent on the transfer of data between processors. It is necessary to carry out further research for other ODEs and other parallel one-step methods of solution of a Cauchy problem.
References
- Хайрер Э., Нёрсетт С., Ваннер Г. Решение обыкновенных дифференциальных уравнений. Нежесткие задачи: Пер. с англ. – М.: Мир, 1990. – 512с.
- Арушанян О.Б., Залеткин С.Ф. Численное решение обыкновенных дифференциальных уравнений на Фортране.– М.: МГУ,1990.–336с.
- Системы параллельной обработки: Пер. с англ./ Под. ред. Ивенса Д.- М.: Мир,1985-416с.
- Фельдман Л.П. Сходимость и оценка погрешности параллельных одношаговых блочных методов моделирования динамических систем с сосредоточенными параметрами // Научные труды ДонНТУ. Серия: Информатика, моделирование и вычислительные методы, (ИКВТ-2000), выпуск 15: Донецк: ДонНТУ, 2000, с. 34-39.