| Назад | Сжатие изображений при помощи вейвлетных преобразований. |
Автор статьи: А.В.Симаков |
|
Исходный URL: http://entropyware.info/articles.html |
|
Введение
В данной статье приведено описание и сравнение эффективности двух вейвлетных преобразований: вейвлетного преобразования Баттерворта [1, 2] и вейвлетного преобразования Добеши 9/7 [3-5]. Последнее получило всемирную известность после того, как было взято за основу в новейшем стандарте сжатия изображений JPEG2000. Безусловно, такой выбор разработчиков стандарта говорит о его эффективности. Другими словами, преобразование Добеши 9/7 является более чем серьезным соперником для преобразования Баттерворта.
Вообще говоря, процесс «вейвлетного» сжатия можно условно разбить на два шага: дискретное вейвлетное преобразование и кодирование. Чтобы оба преобразования были в равных условиях, необходимо использовать для них одинаковый алгоритм кодирования. В этой работе был использован алгоритм кодирования SPIHT [6, 7].
Результаты численных экспериментов приводятся в заключительной части статьи. Они показывают, что, как правило, преобразование Баттерворта не сильно уступает по эффективности преобразованию Добеши 9/7, а в ряде случаев даже превосходит его.
1.Преобразование Баттерворта
1.1 Фильтр Баттерворта
Фильтр Баттерворта
![]() сигналу
сигналу
![]() ставит в соответствие сигнал
ставит в соответствие сигнал
![]() .
Действие оператора
.
Действие оператора
![]() описывается с помощью z-преобразований
описывается с помощью z-преобразований
Считаем, что z
пробегает единичную окружность
![]() ,
это обычно обеспечивает сходимость рядов. Связь между Xи Y устанавливается равенством
,
это обычно обеспечивает сходимость рядов. Связь между Xи Y устанавливается равенством
Общий вид функций
![]() приведен в [1], например, при четном значении rбудем иметь
приведен в [1], например, при четном значении rбудем иметь
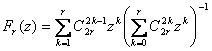 .
.
Нами использовался простейший случай
![]() .
Тогда получаем следующую формулу
.
Тогда получаем следующую формулу
Для реализации при помощи элементарных рекурсивных фильтров разложим
![]() в сумму простейших дробей
в сумму простейших дробей
Для сигналов
![]() и
и
![]() сz-преобразованиями
сz-преобразованиями
справедливы равенства
Отсюда получаем
![]()
![]() ,(1.1)
,(1.1)
![]()
![]() .(1.2)
.(1.2)
Окончательно получаем отфильтрованный сигнал
![]() по формуле
по формуле
![]() .
(1.3)
.
(1.3)
Стоит отметить, что оператор
![]() нужно адаптировать для применения к сигналам конечной длины. Эта
адаптация не носит строго математического характера, а является
набором практических рецептов.
нужно адаптировать для применения к сигналам конечной длины. Эта
адаптация не носит строго математического характера, а является
набором практических рецептов.
1.2 Фильтр Баттерворта для конечных сигналов
Во всех наших предыдущих рассуждениях мы полагали бесконечность сигнала. На практике же приходится иметь дело лишь с сигналами конечной длины. Ясно, что конечные сигналы представляют собой обыкновенные массивы чисел. В дальнейшем, там, где это уместно, вместо термина «сигнал» мы будем употреблять термин «массив».
Итак, далее будем рассматривать
только конечные сигналы. Пусть![]() исходный сигнал длины N,
исходный сигнал длины N,
![]() его отфильтрованная версия, а
его отфильтрованная версия, а
![]() и
и
![]() некоторые промежуточные сигналы. При работе с конечным сигналом
возникает одна проблема: необходимо корректно оценить его крайние
элементы. Рассмотрим, к примеру, формулу (1.1). Видно, что если
некоторые промежуточные сигналы. При работе с конечным сигналом
возникает одна проблема: необходимо корректно оценить его крайние
элементы. Рассмотрим, к примеру, формулу (1.1). Видно, что если
![]() ,
то формула не имеет смысла, так как элемент
,
то формула не имеет смысла, так как элемент
![]() не определен. Рассмотрим теперь формулу (1.2). Если
не определен. Рассмотрим теперь формулу (1.2). Если
![]() ,
то эта формула также теряет смысл, так как элементы
,
то эта формула также теряет смысл, так как элементы
![]() и
и
![]() не определены.
не определены.
Эта проблема решается путем продолжения обрабатываемого сигнала влево и вправо зеркальным образом. Будем считать, что

Вправо сигнал продолжается аналогичным образом

Вернемся теперь к формуле (1.1) и попробуем
оценить значение
![]() .
.
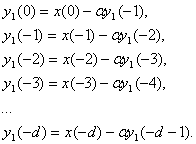
Выберем некоторое
![]() ,
положим
,
положим
![]() и подставим все полученные формулы в выражение для
и подставим все полученные формулы в выражение для
![]() :
:
Учитывая выражение для
![]() ,
получаем следующее выражение для
,
получаем следующее выражение для
![]()
что равносильно
![]() .
(1.4)
.
(1.4)
Величина d
называется глубиной инициализации и определяется экспериментально.
Видно, что с ростом d величина
![]() будет очень быстро убывать, например, если
будет очень быстро убывать, например, если
![]() ,
то
,
то
![]() .
Исходя из этих соображений, в программной реализации была
использована глубина инициализации
.
Исходя из этих соображений, в программной реализации была
использована глубина инициализации
![]() .
.
Пользуясь аналогичными
соображениями, получим оценку значения
![]() в формуле (1.2).
в формуле (1.2).
![]() .
(1.5)
.
(1.5)
Итак, подведем итоги. Действие
оператора
![]() для конечного сигнала сводится к следующим пяти шагам:
для конечного сигнала сводится к следующим пяти шагам:
Вычисляем значение
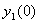 по формуле (1.4).
по формуле (1.4).Для всех
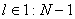 вычисляем
вычисляем
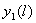 по формуле (1.1).
по формуле (1.1).Вычисляем значение
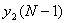 по формуле (1.5).
по формуле (1.5).Для всех
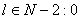 вычисляем
вычисляем
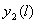 по формуле (1.2).
по формуле (1.2).Для всех
 вычисляем
вычисляем
 по формуле (1.3).
по формуле (1.3).
1.3 Вейвлетное преобразование Баттерворта
Опишем теперь вейвлетное
преобразование Баттерворта для конечного дискретного сигнала
![]() ,
где N – четное число. Наиболее
эффективным способом реализации вейвлетных преобразований вообще
является, так называемый, лифтинговый алгоритм (Lifting
algorithm). Принцип его работы достаточно
прост и укладывается всего в четыре шага.
,
где N – четное число. Наиболее
эффективным способом реализации вейвлетных преобразований вообще
является, так называемый, лифтинговый алгоритм (Lifting
algorithm). Принцип его работы достаточно
прост и укладывается всего в четыре шага.
Мы начнем с алгоритма декомпозиции сигнала. Иногда его называют анализом или просто вейвлетным преобразованием. Затем дадим алгоритм реконструкции сигнала. Его также называют синтезом, восстановлением или обратным вейвлетным преобразованием.
Декомпозиция сигнала
Шаг1: Расщепление
Расщепим массив
![]() на четную (even)
и нечетную (odd)
части следующим образом
на четную (even)
и нечетную (odd)
части следующим образом
Шаг2: Предсказание
Четный массив
![]() будет использован для предсказания элементов нечетного массива
будет использован для предсказания элементов нечетного массива
![]() .
Чем точнее будет предсказание, тем эффективнее будет работать
преобразование. Введем теперь массив
.
Чем точнее будет предсказание, тем эффективнее будет работать
преобразование. Введем теперь массив
![]() и определим его как разность между
и определим его как разность между
![]() и предсказанием
и предсказанием
Если предиктор работает хорошо, то
элементы
![]() должны быть близки к нулю.
должны быть близки к нулю.
Шаг3: Обновление
Введем теперь массив
![]() и определим его следующим образом
и определим его следующим образом
где действие оператора
![]() объясним ниже. По существу,
объясним ниже. По существу,
![]() - это сглаженная версия сигнала
- это сглаженная версия сигнала
![]() .
.
Шаг 4: Нормализация
Набор из двух массивов
![]() называется одноуровневым вейвлетным преобразованием Баттерворта
сигнала
называется одноуровневым вейвлетным преобразованием Баттерворта
сигнала
![]() .
Реконструкция сигнала
.
Реконструкция сигнала
![]() из
из
![]() осуществляется в обратном порядке.
осуществляется в обратном порядке.
Реконструкция сигнала
Шаг1:
Шаг2:
Шаг3:
Шаг4:
Таким образом, мы полностью
реконструировали (восстановили) исходный сигнал
![]() .
.
Как можно было заметить, в
лифтинговом алгоритме появился новый оператор
![]() .
Он отличается от
.
Он отличается от
![]() лишь отставанием на один отсчет, т.е.
лишь отставанием на один отсчет, т.е.
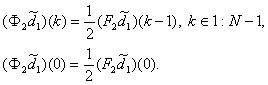
По сути, программная реализация
![]() сводится к вычислению
сводится к вычислению
![]() и сдвигу получившегося сигнала (массива) на один отсчет вправо, а
и сдвигу получившегося сигнала (массива) на один отсчет вправо, а
![]() полагается равным
полагается равным
![]() .
.
Как уже было упомянуто выше, набор
![]() называется одноуровневым вейвлетным преобразованием. Применив
лифтинговый алгоритм к сигналу
называется одноуровневым вейвлетным преобразованием. Применив
лифтинговый алгоритм к сигналу
![]() ,
мы получим набор
,
мы получим набор
![]() ,
где
,
где
![]() и
и
![]() суть вейвлетное разложение сигнала
суть вейвлетное разложение сигнала
![]() .
Набор
.
Набор
![]() называется двухуровневым вейвлетным преобразованием Баттерворта
сигнала
называется двухуровневым вейвлетным преобразованием Баттерворта
сигнала
![]() .
Ясно, что, продолжая в таком же духе, мы можем получить практически
любое количество уровней разложения сигнала. Единственным
ограничением является длина исходного сигнала
.
Ясно, что, продолжая в таком же духе, мы можем получить практически
любое количество уровней разложения сигнала. Единственным
ограничением является длина исходного сигнала
![]() .
Если требуется выполнить t-уровневое
вейвлетное преобразование, необходимо чтобы N
делилось нацело на
.
Если требуется выполнить t-уровневое
вейвлетное преобразование, необходимо чтобы N
делилось нацело на
![]() .
.
1.4 Вейвлетное преобразование Баттерворта для изображений
Изображение является конечным
двумерным дискретным сигналом. Такой сигнал представляет собой просто
двумерный массив чисел (т.е. матрицу). Итак, будем рассматривать
изображение
![]() размера
размера
![]() точек, где
точек, где
![]() ,
,
![]() ,
N – ширина изображения
(количество столбцов), M –
высота изображения (количество строк). На числа N
и M, как и в предыдущем случае,
наложим условие четности. В этом разделе мы покажем, каким образом
можно применить вейвлетное преобразование Баттерворта к двумерному
сигналу
,
N – ширина изображения
(количество столбцов), M –
высота изображения (количество строк). На числа N
и M, как и в предыдущем случае,
наложим условие четности. В этом разделе мы покажем, каким образом
можно применить вейвлетное преобразование Баттерворта к двумерному
сигналу
![]() .
.
Двумерное вейвлетное преобразование
сводится к применению одномерного, сначала ко всем строкам, а затем
ко всем столбцам изображения
![]() .
Полученная в результате матрица
.
Полученная в результате матрица
![]() ,
где
,
где
![]() ,
а
,
а
![]() называется двумерным вейвлетным преобразованием сигнала
называется двумерным вейвлетным преобразованием сигнала
![]() .
Реконструкция (восстановление) изображения производится в обратном
порядке. Сначала одномерный алгоритм реконструкции применяется ко
всем столбцам, а затем ко всем строкам матрицы
.
Реконструкция (восстановление) изображения производится в обратном
порядке. Сначала одномерный алгоритм реконструкции применяется ко
всем столбцам, а затем ко всем строкам матрицы
![]() .
.
Введем несколько обозначений. Пусть
![]() - i-я строка матрицы
- i-я строка матрицы
![]() ,
,
![]() - j-й столбец матрицы
- j-й столбец матрицы
![]() .
Символом
.
Символом
![]() будем обозначать слияние двух массивов.
будем обозначать слияние двух массивов.
Алгоритм двумерной декомпозиции сигнала
Для каждой строки
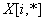 изображения
изображения
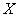 ,
где
,
где
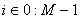 .
.
Считываем строчку
из изображения
.Применяем к
одномерное вейвлетное преобразование Баттерворта, описанное в п.
1.3. В результате этого преобразования получаем два массива:
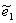 и
и
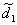 - вейвлетное разложение одномерного сигнала
.
- вейвлетное разложение одномерного сигнала
.Вместо строчки
изображения
записываем массив
 .
.
Для каждого столбца
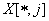 изображения
,
где
изображения
,
где
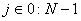 .
.
Считываем столбец
из изображения
.Применяем к
одномерное вейвлетное преобразование Баттерворта. В результате
получаем два массива
и
.Вместо столбца
записываем массив
.
Алгоритм двумерной реконструкции сигнала
Алгоритм двумерной реконструкции аналогичен алгоритму декомпозиции за одним исключением. Алгоритм реконструкции сначала применяется к столбцам, а затем уже к строкам.
Итак, теперь мы знаем как организовано одноуровневое двумерное вейвлетное преобразование Баттерворта. Покажем как работает его многоуровневая версия. Для этого рассмотрим процесс преобразования строк и столбцов исходного изображения более подробно.
|
|
|
|
| Рисунок 1 | Рисунок 2 |
Рисунок 3 |



На рисунке 1
заштриховано оригинальное изображение
![]() .
Обратите внимание, что на первом шаге лифтинг-алгоритма (см. п. 1.3)
происходит прореживание исходного сигнала (в массив
.
Обратите внимание, что на первом шаге лифтинг-алгоритма (см. п. 1.3)
происходит прореживание исходного сигнала (в массив
![]() записывается каждый второй элемент). Применим одномерный алгоритм
декомпозиции ко всем строкам. Результат изображен на рисунке 2.
Заштрихованная область рисунка 2 – это сплюснутое в 2 раза
по горизонтали исходное изображение. Применим теперь одномерный
алгоритм декомпозиции ко всем столбцам. Результат изображен на
рисунке 3. Заштрихованная область на рисунке 3 – это
сплюснутая в два раза по вертикали заштрихованная область рисунка 2.
Выходит, что после применения одноуровневого двумерного вейвлетного
преобразования к исходному изображению
записывается каждый второй элемент). Применим одномерный алгоритм
декомпозиции ко всем строкам. Результат изображен на рисунке 2.
Заштрихованная область рисунка 2 – это сплюснутое в 2 раза
по горизонтали исходное изображение. Применим теперь одномерный
алгоритм декомпозиции ко всем столбцам. Результат изображен на
рисунке 3. Заштрихованная область на рисунке 3 – это
сплюснутая в два раза по вертикали заштрихованная область рисунка 2.
Выходит, что после применения одноуровневого двумерного вейвлетного
преобразования к исходному изображению
![]() мы получаем четыре области (sub-bands).
При этом заштрихованная на рисунке 3 область практически (нужно
конечно учитывать нормализацию и действие оператора
мы получаем четыре области (sub-bands).
При этом заштрихованная на рисунке 3 область практически (нужно
конечно учитывать нормализацию и действие оператора
![]() )
совпадает с исходным изображением, уменьшенным в 2 раза.
)
совпадает с исходным изображением, уменьшенным в 2 раза.
Заштрихованную область рисунка 3
можно рассматривать как изображение размера
![]() точек. Следовательно, к нему так же можно применить одноуровневое
двумерное вейвлетное преобразование, описанное в этом разделе. В
результате мы получаем двухуровневое двумерное вейвлетное
преобразование исходного изображения
точек. Следовательно, к нему так же можно применить одноуровневое
двумерное вейвлетное преобразование, описанное в этом разделе. В
результате мы получаем двухуровневое двумерное вейвлетное
преобразование исходного изображения
![]() .
Оно схематично изображено на рисунке 4.
.
Оно схематично изображено на рисунке 4.

|
| Рисунок 4 |
Ясно, что мы можем применять данный
алгоритм рекурсивно столько раз, сколько нам нужно. Единственным
ограничением является размер исходного изображения. Если требуется
применить t-уровневое двумерное
вейвлетное преобразование Баттерворта, необходимо чтобы N
и M делились нацело на
![]() .
.
2. Преобразование Добеши 9/7
Вейвлетное преобразование Добеши 9/7 [3-5] является, пожалуй, самым известным из существующих на сегодняшний день вейвлетных преобразований. Более того, оно считается одним из наиболее эффективных. Лишним тому доказательством может являться то, что преобразование Добеши 9/7 было выбрано за основу в новом стандарте для сжатия изображений JPEG2000.
Так как преобразование Добеши 9/7 не
является центральной темой этой статьи, приведем лишь итоговые
формулы и алгоритмы. Итак, пусть дан исходный сигнал
![]() ,
где N – четное число. Положим
,
где N – четное число. Положим

Декомпозиция сигнала
Набор
![]() называется одноуровневым вейвлетным преобразованием Добеши 9/7
сигнала
называется одноуровневым вейвлетным преобразованием Добеши 9/7
сигнала
![]() .
Реконструкция сигнала
.
Реконструкция сигнала
![]() из
из
![]() осуществляется в обратном порядке.
осуществляется в обратном порядке.
Реконструкция сигнала
Значения крайних элементов сигнала, в отличие от преобразования Баттерворта, оцениваются намного проще. А именно,

Все, что было сказано в п. 1.3 и 1.4 про многоуровневое и двумерное вейвлетное преобразование, справедливо для любого вейвлетного преобразования, в том числе и для преобразования Добеши 9/7.
Ко многим «плюсам» преобразования Добеши 9/7 можно отнести еще одно: в отличие от преобразования Баттерворта, условие четности сигнала не является обязательным. Преобразование Добеши, при необходимости, можно применять и к сигналам нечетной длины.
3.Алгоритм кодирования SPIHT
3.1 Введение
Алгоритм SPIHT (Set Partitioning in Hierarchical Trees) [6, 7] применяется на заключительной стадии для кодирования коэффициентов вейвлетного разложения изображения. Для большей эффективности SPIHT комбинируют с арифметическим кодированием [8]. К моменту кодирования коэффициенты должны быть округлены до ближайших целых. Как правило, коэффициенты вейвлетного разложения умещаются в 16 бит.
Как ни странно это звучит, но основная идея SPIHT заключается не в том, чтобы непосредственно сжимать изображение, а в том, чтобы переупорядочить биты вейвлетного разложения специальным образом. Уже давно установлено, что для человеческого восприятия низкочастотные компоненты изображения (т.е. плавные переходы яркости и цвета) несут гораздо больше информации, чем высокочастотные (резкие границы, углы, прямые линии). По сути, на принципе выделения низко- и высокочастотной информации, с последующим подавлением последней, и построены практически все технологии сжатия изображений с потерями. Не исключение и SPIHT.
Используя особенности структуры вейвлетных коэффициентов, SPIHT переупорядочивает их биты. При этом, первые биты будут нести наиболее важную информацию, в то время как последние – лишь незначительные, уточняющие детали. Такое упорядочение данных часто называют прогрессивным. При прогрессивной передаче изображения, декодер, получая очередные порции закодированных данных, может последовательно улучшать и уточнять полученное им изображение. При этом вначале декодером будут прорисованы основные цветовые и яркостные переходы, а уж затем второстепенные контуры и малозаметные детали.
Прогрессивное упорядочение, помимо всего прочего, позволяет точно задавать требуемую степень сжатия. Действительно, мы можем сохранить лишь требуемое количество первых битов закодированного изображения, а оставшийся «хвост» просто отбросить, так как он несет сравнительно не много информации.
3.2 Прогрессивная передача изображений
Пусть
![]() исходное изображение размера
исходное изображение размера
![]() точек, где N и M
– ширина и высота изображения соответственно. Пусть далее
точек, где N и M
– ширина и высота изображения соответственно. Пусть далее
![]() вейвлетные коэффициенты исходного изображения. Символом
вейвлетные коэффициенты исходного изображения. Символом
![]() будем обозначать прямое, а символом
будем обозначать прямое, а символом
![]() - обратное вейвлетное преобразование, т.е.
- обратное вейвлетное преобразование, т.е.
![]() и
и
![]() .
Кодированию подвергаются элементы массива
.
Кодированию подвергаются элементы массива
![]() ,
округленные до ближайших целых.
,
округленные до ближайших целых.
При прогрессивной передаче
изображения, декодер вначале работы заполняет массив
![]() нулями и обновляет значения его компонент в соответствии с
поступающими данными. После поучения очередного точного или
приблизительного значения коэффициента, декодер может
реконструировать изображение по формуле
нулями и обновляет значения его компонент в соответствии с
поступающими данными. После поучения очередного точного или
приблизительного значения коэффициента, декодер может
реконструировать изображение по формуле
![]() .
Ясно, что чем ближе
.
Ясно, что чем ближе
![]() будет к
будет к
![]() ,
тем ближе
,
тем ближе
![]() будет к
будет к
![]() .
Другими словами, качество реконструируемого изображения будет расти в
процессе декодирования очередных порций данных. Отсюда и главная
идея: выбрать наиболее важную информацию и передать ее в первую
очередь. Ясно, что большие по абсолютной величине коэффициенты
должны передаваться в первую очередь, т.к. содержат больше
информации. Такой же подход применим и для передачи отдельных битов
самих коэффициентов. Так как старшие биты несут больше информации, их
необходимо передавать первыми. Это, так называемый, метод битовых
плоскостей (bit-plane),
который часто используется для прогрессивной передачи данных.
.
Другими словами, качество реконструируемого изображения будет расти в
процессе декодирования очередных порций данных. Отсюда и главная
идея: выбрать наиболее важную информацию и передать ее в первую
очередь. Ясно, что большие по абсолютной величине коэффициенты
должны передаваться в первую очередь, т.к. содержат больше
информации. Такой же подход применим и для передачи отдельных битов
самих коэффициентов. Так как старшие биты несут больше информации, их
необходимо передавать первыми. Это, так называемый, метод битовых
плоскостей (bit-plane),
который часто используется для прогрессивной передачи данных.
Далее мы представим алгоритм прогрессивной передачи, сочетающий в себе два описанных выше метода: упорядочение коэффициентов по величине и кодирование их битовых плоскостей. Для упрощения изложения будем считать, что координаты коэффициентов передаются явным образом.
3.3 Передача значений коэффициентов
Предположим, что коэффициенты отсортированы по убыванию длины их бинарного представления (при этом ведущий бит не учитывается). Другими словами, задана некоторая перестановка индексов
такая, что
| Знак |
s |
s |
s |
s |
s |
s |
s |
s |
s |
s |
s |
s |
s |
s |
s |
| 5 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 4 | — | > |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 3 | — | — | — | > |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 2 | — | — | — | — | — | — | — | > |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
| 1 | — | — | — | — | — | — | — | — | — | — | — | — | — | — | > |
| 0 | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
> |
Таблица 6: Двоичное представление упорядоченных коэффициентов
На таблице 1 схематично
изображено множество упорядоченных по величине коэффициентов. Каждый
столбец k таблицы 1 содержит
биты коэффициента
![]() .
Биты в самой верхней строке – это знаки соответствующих
коэффициентов. Строки пронумерованы снизу вверх, где в нижней строке
записаны самые младшие биты, а в верхней (под знаком) – самые
старшие.
.
Биты в самой верхней строке – это знаки соответствующих
коэффициентов. Строки пронумерованы снизу вверх, где в нижней строке
записаны самые младшие биты, а в верхней (под знаком) – самые
старшие.
Теперь предположим, что наряду с
информацией об упорядочении коэффициентов (отображение
![]() ),
декодер получает числа
),
декодер получает числа
![]() .
Значение
.
Значение
![]() равно количеству коэффициентов
равно количеству коэффициентов
![]() ,
таких, что
,
таких, что
![]() .
В нашем примере
.
В нашем примере
![]() ,
,
![]() ,
,
![]() и т.д.
и т.д.
Т.к. все биты в строке содержат
одинаковое количество информации, можно определить наиболее
эффективный алгоритм их передачи. Необходимо последовательно
передавать биты каждой строки, в направлении, указанном стрелками.
Начинать нужно с верхней строки. Заметим, что передавать ведущие «0»
и первую «1» не нужно, т.к. эту информацию можно
восстановить, используя
![]() и
и
![]() .
.
Описанный выше метод прогрессивной передачи коэффициентов может быть реализован при помощи следующего алгоритма.
Алгоритм прогрессивной передачи значений коэффициентов
Найти и передать
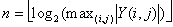 .
.Передать
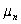 ,
координаты
,
координаты
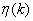 и знаки коэффициентов
и знаки коэффициентов
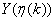 ,
для которых
,
для которых
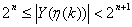 .
.Передать n-й значимый бит всех коэффициентов
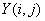 ,
для которых
,
для которых
 (т.е. тех, чьи координаты были переданы на предыдущем проходе).
(т.е. тех, чьи координаты были переданы на предыдущем проходе).Уменьшить n на 1 и идти на шаг 2.
Для наглядности приведем несколько характерных значений, получающихся на шаге 1, для преобразования Баттерворта.
| Изображение | Наибольший коэффициент | Значение n |
|
SIMAKOV |
33767 |
15 |
|
LENA |
12281 |
13 |
|
BARBARA |
13457 |
13 |
|
GOLDHILL |
35173 |
15 |
Таблица 6: Характерные значения коэффициентов
Данный алгоритм можно остановить в любой момент, когда будет достигнута требуемая степень сжатия или возмущение. Обычно, хорошее качество можно получить, передав лишь небольшую часть данных таким способом.
По сути, SPIHT
предлагает лишь одно значимое усовершенствование к этому алгоритму. В
то время как большая часть передаваемых битов тратится на
передачу
![]() в явном виде, SPIHT передает эту информацию
в гораздо более компактном, неявном виде. Подробнее об этой неявной
передаче см. в статьях [6, 7].
в явном виде, SPIHT передает эту информацию
в гораздо более компактном, неявном виде. Подробнее об этой неявной
передаче см. в статьях [6, 7].
4. Численные эксперименты
В качестве тестовых изображений были
выбраны три общепринятых полутоновых изображений LENA,
BARBARA и GOLDHILL
размера
![]() точек. Также было использовано полноцветное изображение SIMAKOV
размера
точек. Также было использовано полноцветное изображение SIMAKOV
размера
![]() точек.
точек.
К изображениям LENA, BARBARA и GOLDHILL было применено 9-ти уровневое вейвлетное преобразование, а к изображению SIMAKOV – 8-ми уровневое.
Для оценки качества восстановленных изображений использовалась значение PSNR (Peak Signal-to-Noise Ratio). Для полутоновых изображений использовалась формула
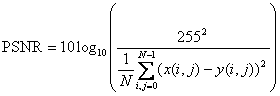 ,
,
а для полноцветных, формула
 ,
,
где N – количество пикселей в изображении, а нижние индексы r,g,b соответствуют красному, зеленому и синему каналам соответственно.
| Степень сжатия | Преобразование Баттерворта | Преобразование Добеши 9/7 |
| 1:2 | 53.475 dB | 53.865 dB |
| 1:4 | 43.604 dB |
43.855 dB |
|
1:8 |
39.703 dB | 39.806 dB |
|
1:16 |
36.714 dB | 36.780 dB |
|
1:32 |
33.589 dB | 33.697 dB |
|
1:64 |
30.605 dB | 30.723 dB |
|
1:128 |
27.879 dB | 27.950 dB |
|
1:256 |
25.568 dB | 25.707 dB |
|
1:512 |
23.629 dB | 23.584 dB |
|
1:1024 |
21.643 dB |
21.817 dB |
Таблица 6: LENA 512x512
| Степень сжатия | Преобразование Баттерворта | Преобразование Добеши 9/7 |
|
1:2 |
50.320 dB | 50.418 dB |
|
1:4 |
42.049 dB |
41.928 dB |
|
1:8 |
35.715 dB | 35.499 dB |
|
1:16 |
30.807 dB | 30.641 dB |
|
1:32 |
26.862 dB | 27.212 dB |
|
1:64 |
24.478 dB | 24.621 dB |
|
1:128 |
23.048 dB | 23.152 dB |
|
1:256 |
22.017 dB | 22.091 dB |
|
1:512 |
20.727 dB | 20.918 dB |
|
1:1024 |
19.411 dB |
19.482 dB |
Таблица 6: BARBARA 512x512
| Степень сжатия | Преобразование Баттерворта | Преобразование Добеши 9/7 |
|
1:2 |
49.564 dB | 50.015 dB |
|
1:4 |
40.515 dB |
40.739 dB |
|
1:8 |
35.809 dB | 35.952 dB |
|
1:16 |
32.581 dB |
32.732 dB |
|
1:32 |
30.226 dB | 30.240 dB |
|
1:64 |
28.072 dB | 28.276 dB |
|
1:128 |
26.451 dB | 26.542 dB |
|
1:256 |
24.997 dB | 25.110 dB |
|
1:512 |
23.659 dB | 23.778 dB |
|
1:1024 |
22.279 dB |
22.406 dB |
Таблица 6: GOLDHILL 512x512
| Степень сжатия | Преобразование Баттерворта | Преобразование Добеши 9/7 |
|
1:2 |
46.870 dB | 46.528 dB |
|
1:4 |
46.087 dB | 45.968 dB |
|
1:8 |
44.604 dB | 44.623 dB |
|
1:16 |
42.606 dB | 42.651 dB |
|
1:32 |
41.213 dB | 41.363 dB |
|
1:64 |
40.438 dB | 40.491 dB |
|
1:128 |
39.815 dB | 39.948 dB |
|
1:256 |
39.385 dB | 39.422 dB |
|
1:512 |
38.441 dB | 38.527 dB |
|
1:1024 |
36.632 dB |
36.790 dB |
Таблица 6: SIMAKOV 1024x1280
Из приведенных таблиц видно, что
преобразование Баттерворта показывает результаты, сравнимые со
всемирно известным преобразованием Добеши 9/7, а в ряде случаев даже
превосходит его. Так же нужно учесть, что мы использовали простейший
случай преобразования Баттерворта, где параметр
![]() (см. п.1.1). С ростом r
эффективность, пусть и не намного, должна увеличиться. Другим
перспективным направлением являются вейвлетные преобразования А.П.
Петухова [9].
(см. п.1.1). С ростом r
эффективность, пусть и не намного, должна увеличиться. Другим
перспективным направлением являются вейвлетные преобразования А.П.
Петухова [9].
6.Библиография
[1] В. А. Желудев, А. Б. Певный. Вейвлетное преобразование Баттерворта и его реализация при помощи рекурсивных фильтров // Ж. вычисл. мат. и матем. физ. 2002. Т. 42. N 4. С. 571-582.
[2] Amir Z. Averbuch, Valery A. Zheludev. A library of spline based biortogonal wavelet transforms for image compression // Preprint. 2002.
[3] M. Antonini, M. Barlaud, P. Mathieu, I. Daubechies. Image Coding Using Wavelet Transform // IEEE Transactions on Image Processing. 1992. V. 1. N 2. P. 205-220.
[4] A. Cohen, I. Daubechies, J. C. Feauveau. Biorthogonal Bases of Compactly Supported Wavelets // Communications on Pure and Applied Mathematics. 1992. V. 45. N 5. P. 485-560.
[5] I. Daubechies, W. Sweldens. Factoring Wavelet Transforms Into Lifting Steps // J. Fourier Anal. Appl. 1998. V. 4. N 3. P. 245-267.
[6] Amir Said, William A. Pearlman. A New Fast and Efficient Image Codec Based on Set Partitioning in Hierarchical Trees // IEEE Trans. on Circuits and Systems for Video Technology. 1996. V. 6. P. 243-250.
[7] Shapiro, J. M. Embedded image coding using zerotrees of wavelet coefficients // IEEE Transactions on Signal Processing. 1993. V. 41. N 12. P. 3445-3462.
[8] I. H. Witten, R. M. Neal, J. H. Cleary. Arithmetic coding for data compression // CACM. 1987. V. 30. N 6. P. 520-540.
[9] А. П. Петухов. Биортогональные базисы всплесков с рациональными масками и их приложения // Труды СПбМО. 1999. Т. 7. С. 168-193.
[10] D. A. Huffman. A method for the construction of minimum-redundancy codes // Proc. Inst. Radio Engineers. 1952. V. 40. N 9. P. 1098-1101.
[11] А. В. Симаков. Код Хаффмана. http://www.entropyware.info/HuffmanCode/huffcode.html
[12] А. В. Симаков. Сайт, посвященный коду Хаффмана. http://www.webcenter.ru/~xander
[13] В. А. Кирушев. Быстрый алгоритм сжатия изображений // Вестник молодых ученых. Прикладная математика и механика. 1997(1). С. 4-10.
[14] Семинар «Всплески и их приложения». http://www.math.spbu.ru/user/dmp
[15] Д. Ватолин. Методы сжатия данных. http://www.compression.graphicon.ru
[16] В. А. Желудев. Домашняя страница. http://www.cs.tau.ac.il/~zhel