И. А. Большаков
Описываются методы автоматического выявления видовых глагольных пар русского языка. Основная программа получает на вход обширный корпус сочетаний существительных-дополнений с управляющими глаголами. Очередная пара выделяется, когда два глагола при едином существительном удовлетворяют одному из заданных соотношений суффиксов или префиксов и участвуют в одинаковой предложно-падежной конструкции. В другой программе на вход дан корпус сочетаний глаголов-сказуемых с подлежащими, и при едином существительном у глаголов проверяются лишь морфологические соотношения. Третья программа выделяет пары из глагольных секций гнезд, объединяющих семантические дериваты. Предложены методы отсева ложных пар. Получены списки из 2434, 582 и 1610 видовых пар, соответственно, в общей сложности – 2847 разных пар. Изучена частота использования различных морфологических средств при формировании одного вида из другого.
ВВЕДЕНИЕ
Проблема выявления видовых глагольных пар в русском языке считается в лексикографии непростой, поскольку только сравнительно недавно удалось достаточно четко сформулировать смысловые различия между двумя видами глагола [1], да и их непосвященному до конца понять трудно.
Данная работа не имеет целью добавить что-либо новое в чисто лексикографическую сторону вопроса. В академические споры мы не вступаем, и там, где нужно проверить себя или созданную нами программу относительно конкретной видовой пары, прибегаем к авторитетным словарям – Ожегова [2] или четырехтомного академического [3].
Задачей данной работы является выделение видовых пар чисто формальными методами, по исходным данным некой автоматизированной справочной системы по русскому языку. Речь идет о словаре-тезаурусе КроссЛексика [4] с обширным корпусом различных слов и словосочетаний. По состоянию на январь 1998 г., в их числе имеется обший словарь примерно из 110 тыс. статей, корпус примерно из 260 тыс. сочетаний глаголов с разными именными дополнениями, корпус из 169 тыс. сочетаний глаголов-сказуемых с существительными-подлежащими, словарь семантических дериватов, в глагольных секциях гнезд которого в общей сложности находится около 9 тыс. глаголов, и многое другое. Из-за различий в их сочетаемости с другими словами, глаголы разных видов представлены во всех частях системы по отдельности, что и дает фактический материал для поиска видовых пар.
Специфической чертой системы КроссЛексика является то, что для получения морфологических характеристик всех элементов ее словаря используются чисто алгоритмические методы, причем получаются эти характеристики непосредственно в процессе автоматической подготовки рабочего варианта системы. Это включает компиляцию общего морфологического словаря по исходным текстовым массивам [5]. Если данное слово имеет какие-либо морфологические особенности или представляет исключение, сведения об этом непосредственно заносятся в программу компиляции рабочей лингвистической базы. В ином случае действуют общие законы грамматики и соображения аналогии. При условии устранения всех ошибок, отмечаемых сообщениями при компиляции, последняя всегда обеспечивает точное соответствие "вычисленных" характеристик материалам исходной лингвистической базы.
В рамках КроссЛексики не хотелось упускать возможности автоматизации и процесса определения вида глагола и видовых пар, там где таковые имеются. Ниже идет речь только о выделении видовых пар и соответствующих значений вида для каждого глагола в паре. Более сложная проблема определения вида непарных глаголов отложена на дальнейшее.
Выделение видовых пар на этапе компиляции рабочей лингвистической базы позволяет решить для системы, по крайней мере, три крупных задачи.
Во-первых, это подготовка к выдаче в рабочем режиме полной парадигмы глагола, т. е. личных форм обоих его видов при всех существующих значениях грамматического времени. Если вид данного глагола не известен, то остается выдавать его формы только в прошедшем и непрошедшем временах, где под последним понимается настоящее время несовершенного вида или будущее совершенного вида. Будущее же несовершенного вида (формируется аналитически – буду писать, будешь писать,...) из-за предосторожности приходится опускать.
Во-вторых, в системе планируется автоматический перевод всех словосочетаний "глагол – дополнение" в словосочетания "активное причастие – дополнение". Это обещает существенно расширить покрытие текстов имеющимися в системе словосочетаниями. В отношении причастий прошедшего времени такое преобразование возможно во всех случаях, но у глаголов несовершенного вида в текстах чаще используются причастия настоящего времени, которые нельзя формировать, не зная, каков вид данного глагола.
В-третьих, знание некоторого класса словосочетаний для одного вида данного глагола при незнании их для другого вида позволяет переносить (пусть изредка неверно) эти словосочетания на этот другой вид. Например, если системе знакома видовая пара освистать/освистывать и у освистать известны такие атрибуты, как дружно/нагло/нахально/немедленно/..., а у освистывать никаких атрибутов не известно, то указанный перенос дает лишь небольшое число неправильных результатов.
К проблеме автоматизации легче подойти по аналогии с работой лексикографа. Когда он мысленно сравнивает два глагола на предмет их вхождения в видовую пару, то при необходимости придумывает контексты, равно применимые к обеим формам, чтобы точнее заметить разницу в смысле и убедиться в ее соответствии межвидовым различиям.
В нашем распоряжении были грамматики с правилами формирования совершенного вида из несовершенного, и наоборот, а также корпус сочетаний глаголов с существительными, к глаголам в которых можно было применить чисто формально следующие два критерия:
семантический – сочетаемость с одним и тем же существительным, морфологический – межвидовое соответствие суффикса и/или префикса одного из них суффиксу и/или префиксу другого.
К сочетаниям глагола с его прямым, косвенным или предложным дополнением можно применить и еще один, синтаксический, критерий – вхождение в одну и ту же предложно-падежную конструкцию.
Наши критерии удобно пояснить примерами. Так, пара выражений просить одолжения – попросить одолжения с учетом знания, что префикс по- иногда образует совершенный вид, является весомым (хотя и не гарантированным!) свидетельством того, что просить/попросить являются видовой парой. В качестве других примеров, пары установить отношение – устанавливать отношение и войти в дверь – входить в дверь, с учетом соответствия суффиксов (они рассматриваются совместно с релевантными отрезками чередуемых и/или суплетивных основ, в данных примерах – авлива/ови, ойти/ходить), являются хорошим (но опять не гарантированным) свидетельством наличия видовых пар установить/устанавливать и войти/входить. Однако в случае жарить картошки – нажарить картошки конструкции не одинаковы, поэтому пара жарить/нажарить, по нашим критериям, видовой признана не будет. Все перечисленные критерии, однако, еще не исключают массы ложных гипотез, о которых пойдет речь ниже.
Применительно к семантическим дериватам процесс выделения пар имеет несколько иной характер. Речь идет об обработке около 4000 гнезд, посвященных каждая своему понятию. Каждое гнездо поделено на четыре секции – существительные, глаголы, прилагательные и наречия. Например, в гнезде ВХОЖДЕНИЕ в глагольной секции имеются входить, войти, в гнезде ПРОВОДЫ – провожать, проводить!, быть на проводах, в гнезде ПРОВЕДЕНИЕ – проводить2, провести, обеспечить проведение, обеспечивать проведение. Семантический критерий близости обеспечен уже самим фактом попадания некоторой пары глаголов в единую секцию. Морфологический же критерий здесь тот же, что и в случае словосочетаний.
Все сказанное и явилось методической основой автоматизированного выделения видовых пар на основе трех крупных частей исходной лингвистической базы данных. В число средств формирования рабочей базы данных включены три вспомогательные программы (утилиты), опирающиеся каждая на свои массивы исходных данных. Результаты (т. е. списки видовых пар) оказались пересекающимися. Это естественно, поскольку одни и те же пары могут использоваться в качестве управляющих для некоторого дополнения и такого же подлежащего и многие из этих глаголов даны среди семантических дериватов.
Указанные утилиты вместе с получаемыми с их помощью результатами ниже описываются подробнее.
СРЕДСТВА ВЫДЕЛЕНИЯ ВИДОВЫХ ПАР
Необходимые сведения по суффиксальному и префиксальному формированию глагольных видов были прямо взяты из академической грамматики [6] и ряда иных источников [7]. Отдельные правила и все имеющиеся в грамматиках примеры были преобразованы в форму машинных таблиц. Таблицы соответствия буквенных отрезков при суффиксальном видообразовании оказались на удивление обширными. Действительно, в них нужно было отразить (в обратном порядке вдоль слова) всевозможные сочетания следующих морфонологических явлений:
cмена тематических суффиксов;
различные видообразующие суффиксы;
выпадение и/или чередование завершающих корневых согласных;
чередование о/а корневой гласной;
супплетивные мены корня (ловить/поймать, говорить/сказать);
чисто графические замены и/ы при префиксальном по существу образовании вида {играть/сыграть, искать/отыскать);
появление беглого о между приставкой и корнем (разрывать/разорвать);
случаи, когда изменение вида сопровождается появлением/исчезновением частицы -ся (ложиться/лечь, лопаться/лопнуть, становиться/стать).
Таблиц суффиксальных преобразований получилось две.
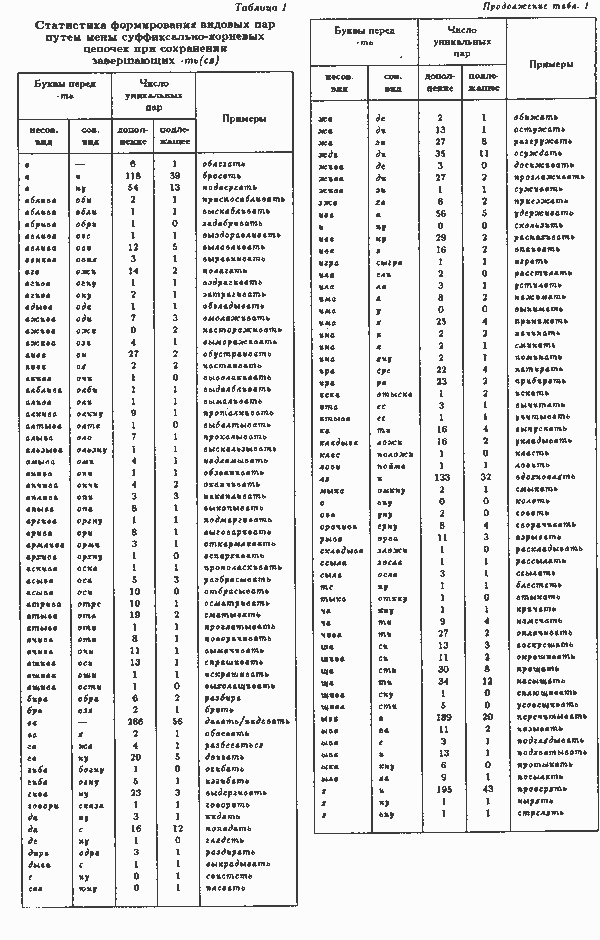
В одной из них (табл. 1, два правых столбца) рассмотрены все выявленные случаи, когда суффиксальное завершение на -ть или -ться у глагола при смене вида сохраняется неизменным. Будем называть это первым суффиксальным способом. Пустая цепочка обозначена здесь знаком подчеркивания. В табл. 1 помещен 121 вариант всевозможных видовых соответствий буквенных цепочек, предшествующих-ть. Варианты буквенных цепочек даны в смежных столбцах в порядке несов.–сов. вид и лексикографически упорядочены.
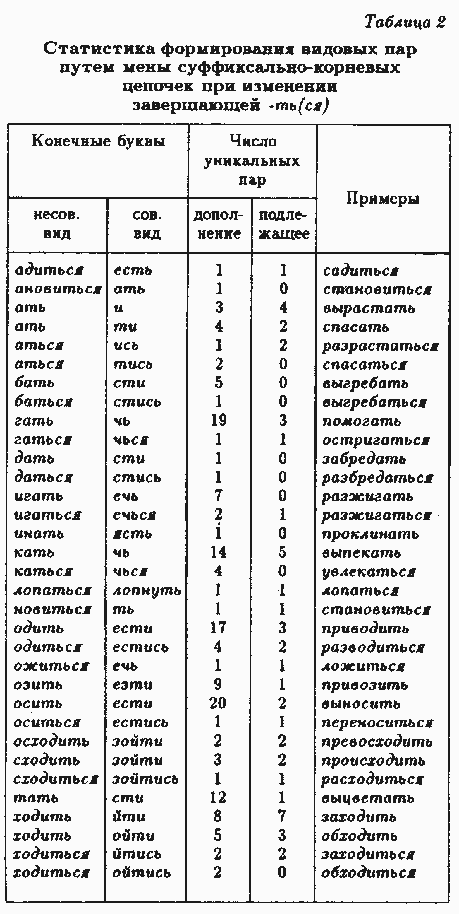
В другой таблице (табл. 2, два первых столбца) рассмотрены все случаи, когда суффиксальное завершение не сохраняется из-за появления суффикса -ти (-тись), -чь (-чье*) или появления/исчезновения частицы -ся. Таких случаев отмечено 33, причем варианты -ть/-ться, -тк/ -тись, -чь/-чьсж включены сюда по отдельности. Назовем это вторым суффиксальным методом.
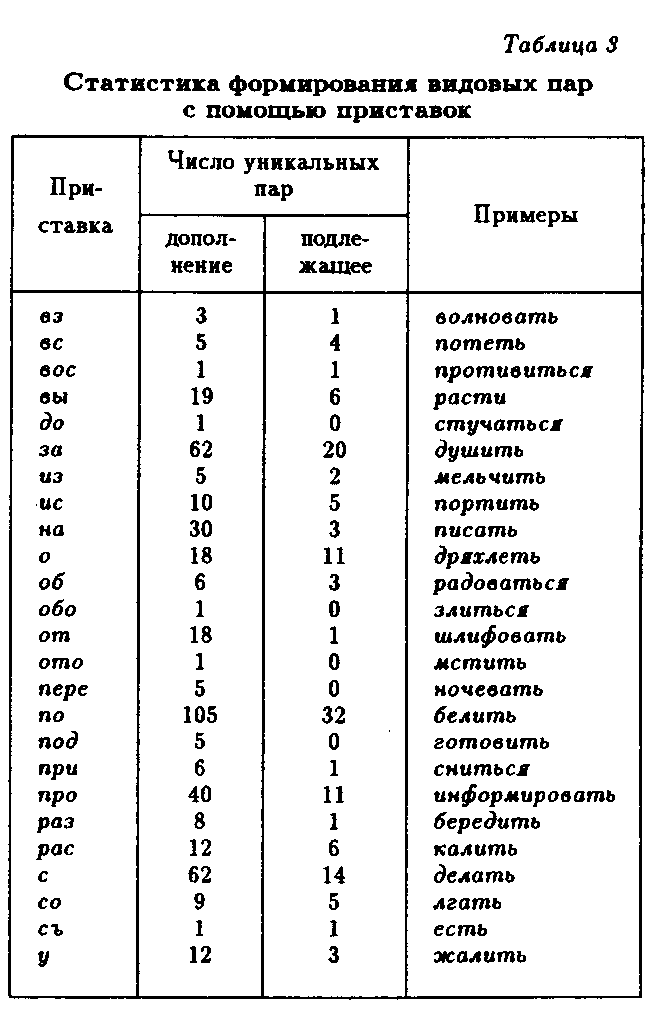
Релевантных для формирования пар перфективирующих приставок оказалось всего 25 (одним из вариантов сюда включен съ-). Важно подчеркнуть, что в широком смысле перфективирующих приставок в русском языке почти вдвое больше, но неучтенные нами несколько меняют лексическое значение глагола и строгой видовой пары из-за этого не образуют. Все взятые нами варианты представлены первым столбцом табл. 3.
После первых же экспериментов с создаваемыми программами было замечено, что применяемые "селективные" фильтры морфологического, синтаксического и семантического характера оказываются недостаточными. Появилось довольно большое число ложных видовых пар. Поэтому пришлось ввести "режекторные" фильтры, отсеивающие ложные варианты. Это потребовало включения в программу нескольких запретительных списков. Одни из глаголов не допускают некоторый конкретный способ видообразования, другие допускают его лишь при дополнительном индивидуальном условии. Охарактеризуем эти списки по отдельности.
Первый список содержит те глаголы, для которых ложную пару дают суффиксальные замены по первому способу. Этот список невелик (26 пар) и приводится ниже целиком:
бывать/быть,
бегать/бежать,
верить/вернуть,
висеть/виснуть,
выдать/вынуть,
делать/делить,
доставать/доставить,
заметать/заметить,
копать/копнуть,
купать/купить,
ласкаться/ластиться,
налаживать/наложить,
ломать/ломить,
плевать/плюнуть,
прорываться/прорыться,
развесить/развешать,
раскатать/раскатить,
родить/рождать,
сжигать/сжижать,
сжигатъся/сжижатъсм,
слабет ь/сл а бнуть,
сломать/сломить,
сменить/сменять,
стоить/стоять,
счесть/считать,
съедать/съесть.
Одни из приведенных глаголов сходны только буквенно {делать/делить, сжигать/сжижать, стоить/стоять и под.), другие имеют общий корень, но вид у глаголов совпадает (ломать/ломить, слабеть/слабнуть и под.), для третьих мена суффикса действительно переводит один вид глагола в другой того же корня, но это не строгая видовая пара (например, плевать/плюнуть, съедать/съесть не признаются видовыми парами в словарях, у плевать и съесть есть другие соотносительные глаголы).
Подобных псевдовидовых пар в русском языке, вообще говоря, много больше, но этот список оказался для наших утилит достаточным. Остальные на нашем материале не возникли из-за наличия указывавшихся фильтров семантического и/или синтаксического характера.
Второй ограничительный список, необходимый для суффиксальных замен согласно второму способу, совсем мал: среди пар не должно быть глаголов, начинающихся с водить, возить, носить (пары водить/вести, возить/везти, носить/нести, носиться/нестись видовыми не являются, по контрасту с приводить/привести, привозить/привезти, приносить/принести и аналогичными приставочными парами).
Остальные ограничительные списки действенны для префиксального видообразования. Третий из них дает глаголы, которые и без присоединения какой-либо приставки принадлежат совершенному виду. Этот список заметно обширнее предыдущих (98 глаголов), и мы приводим только его начальный фрагмент: броситься, быть, вернуть, внести, встать, вооружить, выбрать, выполнить, двинуть, двинуться, дернуть, глотнуть, ... . Данный фильтр отсеивает такие пары, как броситься/наброситься, внести/привнести, вооружить/перевооружить и многие другие.
Четвертый список дает глаголы несовершенного вида, для которых префиксальная перфективация никогда не дает строгой видовой пары. Здесь отмечено 222 глагола. Опять приводим начало списка: аплодировать, баловать, баловаться, барабанить, блестеть, бояться, брать, бренчать, бродить, бегать, .... Данный фильтр отсеивает такие пары, как аплодировать/зааплодировать, баловаться/побаловаться, барабанить/отбарабанить, брать/забрать и обширное множество других.
Последний список дает те глаголы несовершенного вида, для которых суффиксальная перфективация возможна, но только при одной конкретной приставке. Оговоримся, что академические словари знают довольно много глаголов, которые имеют две и даже более равно допустимых приставки, образующих строгие видовые пары. Но в большинстве своем разные приставки соответствуют несколько разным значениям исходного глагола. В КроссЛексике уже начат процесс расщепления таких глаголов на несколько омонимов, каждый из которых в совершенном виде обслуживается отдельной приставкой. На текущем этапе нерасщепленным значениям приписывается пока одна приставка, соответствующая наиболее вероятному варианту смысла. В рассматриваемом списке 249 глаголов, а его начало имеет вид пo-белить, с-беречь, по-беречься, no-благодарить, вы-бранить, no-брить, по-бриться, ....
В общей сложности в режектирующие списки вошло около 600 глаголов, равно пригодных для отсева ложных вариантов из числа управляющих дополнениями и подлежащими. Но разных глаголов, управляющих дополнениями, в системе 9509, а управляющих подлежащими – 4509, так что речь идет о включении в утилиты глаголов, составляющих лишь 6-13% от всего наличного состава. Режекция позволила исключить ложные варианты, которые составляют примерно четверть того, что было бы получено без нее.
РЕЗУЛЬТАТЫ ОБРАБОТКИ ГЛАГОЛЬНО-ИМЕННЫХ СЛОВОСОЧЕТАНИЙ
Утилита обработки словосочетаний с дополнениями дала 2434 разных видовых пары, утилита обработки дополнений – 582 видовых пары. Объединение составило 2691 пару, а пересечение – 325 пар, что составляет 12% от объединения (13% и 56% от объединяемых частей). Итак, две эти утилиты выстроили в видовые пары примерно 5,4 тыс. глаголов, взяв их, в основном, из словосочетаний с дополнениями.
Перейдем к детализации полученных результатов.
Статистика выявления уникальных (т. е. учитываемых без повторов) видовых пар первым суффиксальным способом из массива, дополнений дана в табл. 1 третьим столбцом. Видны существенные различия продуктивности разных вариантов: первые пять наиболее продуктивных из них (ва/, я/и, ыва/а, ля/и, а/и) покрывают ровно половину всех случаев. Те же самые данные для массива подлежащих даны в табл. 1 четвертым столбцом. Здесь лидеры те же, и в совокупности они покрывают около 47%, т. е. опять примерно половину.
Статистика продуктивности различных вариантов второго суффиксального способа дана в табл. 2, соответственно, третьим столбцом для дополнений и четвертым для подлежащих. Эти суффиксальные средства используются заметно реже. Из них лидирующими для дополнений являются осить/ести, гатъ/чъ, одить/ести, кать/чь, тать/сти, в совокупности покрывающие 52%. Для подлежащих лидеры несколько иные – ходить/йти, кать/чь, ать/и, гать/чь, одить/ести, в совокупности покрывающие 49% всех случаев.
Статистика предуктивности префиксального видообразования представлена в табл. 3, соответственно, вторым и третьим столбцами. Здесь особенно заметна продуктивность приставок по-, за-и с-, совместно покрывающих 51% случаев для дополнений и 50% для подлежащих.
Перейдем к укрупненным характеристикам формирования пар разными способами. Будем учитывать не только уникальные сформированные пары, но и то, сколько раз подобные пары формировались в процессе обработки исходных массивов.
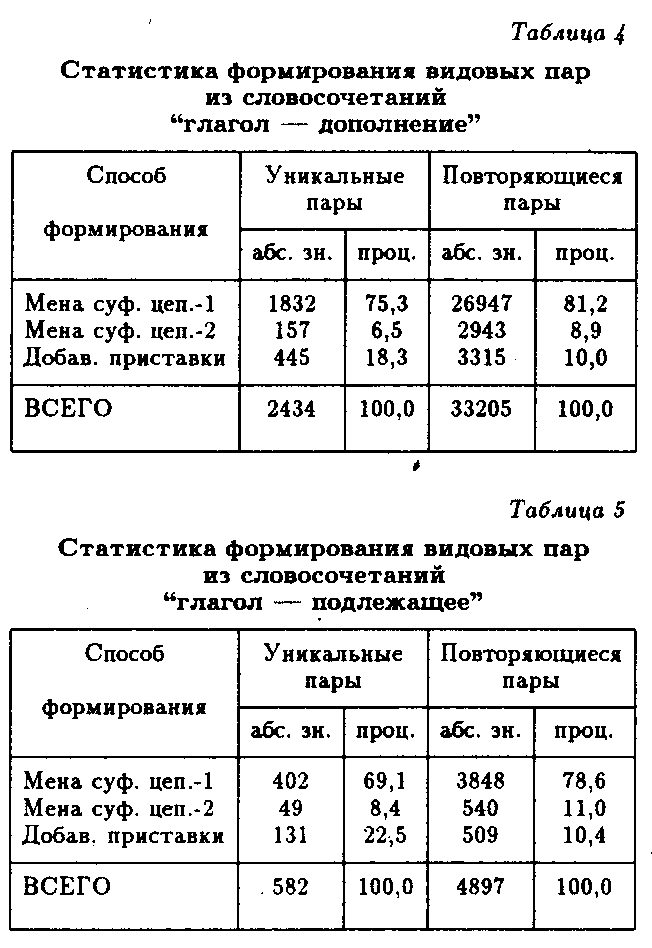
В табл. 4 и 5 даны укрупненные показатели для массива дополнений и прилагательных, соответственно. При подсчете уникальных пар наиболее продуктивен первый суффиксальный способ (75.3-69.1% всех случаев), далее следует префиксальный (18.3-22.5%) и второй суффиксальный (6.5-8.4%).
При подсчете повторов порядок убывания продуктивности тот же, но существенно уменьшается доля префиксального метода (81.2-78.6%, 10.4-10.0%, 8.9-11.0%).
Отдельным нашим исследованием было обнаружено, что ранговые распределения вероятностей появления отдельных слов и конструкций, с одной стороны, в очень большом словаре (каковым является КроссЛексика) и, с другой стороны, в обычных текстах оказываются близкими между собой. С учетом этого обстоятельства можно заключить, что русская речь примерно в 80% случаев пользуется видовыми парами, сформированными первым суффиксальным методом, а на префиксальный и второй суффиксальный способ остается примерно по 10%.
Теперь приведем данные о степени покрытия видовыми парами исходных корпусов словосочетаний и степени повторяемости выделяемых пар по корпусам. Словосочетания с дополнениями в количестве 168852 превращаются в 33501 повторяющуюся пару (степень покрытия 40%), а последние превращаются в 2434 уникальных пар (коэффициент повторения 13.6). Для словосочетаний с подлежащими (исходно их – 90831) соответствующие цифры составляют 4897 повторяющихся пар (степень покрытия 11%) и 582 уникальных пары (коэффициент повторения 8.3).
Хорошо понятна почти четырехкратная разница в степени покрытия для дополнений и подлежащих. Дело в том, что совершенный вид сказуемых очень часто выражается не личной формой глагола, а его страдательным причастием, которое не находит соответствия с глаголом несовершенного вида и видовой пары у нас не образует. Особенно часто это происходит с возвратными глаголами.
Типичный пример для сказуемого при подлежащем продукция: в несовершенном виде она разрабатывается, однако в совершенном – не разработалась, а (была) разработана. К тому же нет видовых пар для глагола быть, входящего в корпус с подлежащими гораздо чаше, чем с дополнениями.
ОБРАБОТКА СЕМАНТИЧЕСКИХ ДЕРИВАТОВ
Обработка семантических дериватов имеет ряд особенностей.
Во-первых, она не нуждается в таких мощных режекторных фильтрах. Их, как правило, заменяет сам факт отнесенности пар глаголов к одному семантическому гнезду. Два последних ограничительных списка (см. выше) сокращены поэтому примерно в 10 раз, без ущерба для результатов.
Во-вторых, только при обработке дериватов включаются в рассмотрение омонимичные глаголы, снабженные цифровыми пометами. С их помощью, например, удается зафиксировать различия глаголов проводить! (родственников) vs. прово-дить2 (семинар). Из них глаголу проводить! приписывается совершенный вид с видовым антагонистом провожать, а глаголу проводить 2 – несовершенный вид с антагонистом провести. В другом примере, глаголы срезать! vs. срезатьВ (с разным местом ударения) оказываются в одной видовой паре.
В-третьих, при обработке дериватов возможно установить видовое соответствие не только между одиночными глаголами, но и глагольными словосочетаниями, например, обеспечить проведение/обеспечивать проведение.
Опишем теперь полученные результаты. Исходно во всех глагольных зонах 3891 дериватных гнезд находится 8758 глаголов или глагольных выражений. Из них получено 1648 частично повторяющихся пар (степень покрытия 38%). Уникальных пар из них 1610, а коэффициент повторения равен 1.024, т. е. практически повторений нет. По мере совершенствования корпуса дериватов есть надежда еще снизить число повторов.
При сравнении с парами, выделенными из глагольно-именных словосочетаний, здесь оказались 283 новые пары. Среди них в 38 парах хотя бы один глагол омонимичен, а 205 пары соответствуют глагольным выражениям типа совершать акт/совершить акт.
С учетом всех трех источников видовых пар, их общее число без повторов составляет 2847, т. е. они покрывают около 5.7 тыс. глаголов и глагольных выражений.
НЕКОТОРЫЕ ОБЩИЕ ИТОГИ
Судя по известной нам литературе по прикладной лингвистике, в данной работе впервые эксплицитно перечислены все комбинации суффиксальных и префиксальных морфологических средств, позволяющих получать видовые пары русских глаголов. Реально полученные автоматическим путем видовые пары покрывают 5.7 тыс. наиболее употребительных русских глаголов.
Предложенный метод оказался применимым не только к глаголам, давно зафиксированным в словарях, но и тем, которые появились совсем недавно (типа растаможивать/растаможить, инсталлировать/проинсталлировать), но попали в нашу базу данных из газет и речи.
Разработанные средства выявили совершенный вид у некоторых из тех глаголов, которые официально считаются двувидовыми, но впоследние годы все чаще воспринимаются даже грамотными носителями языка как несовершенный вид, с форсированным выдвижением для них в речи соответствующего совершенного вида (реагировать/прореагировать,блокировать/заблокировать,информиро-вать/проинформировать,дезинфицировать/продезинфицировать, игнорировать/проигнорировать, ...).
Предложенные программы хорошо обеспечивают нужды той системы, для которой они были созданы. Но можно надеяться, что они смогут использоваться и в чисто исследовательских целях, а также для обучения русскому языку. В части обучения, видовые категории русского глагола очень плохо даются иностранцам, представленный же материал показывает, какие морфологические средства видообразования нужно запоминать в первую очередь.
СПИСОК ЛИТЕРАТУРЫ
1. Гловинская М. Я. Семантические типы видовых противопоставлений русского глагола.– М.: Наука, 1982.– 155с.
2. Ожегов С. И. Словарь русского языка.– М.: Сов. энциклопедия, 1968.– 920 с.
3. Словарь русского языка: В 4 т.– М.: Русский язык, 1985.
4. Большаков И.А. Многофункциональный словарь-тезаурус для автоматизированной подготовки русских текстов // НТИ. Сер. 2.– 1994.– № 1.–С. 11-23.
5. Большаков И.А. Автоматическое формирование русского морфологического словаря по исходным массивам слов и словосочетаний // НТИ. Сер. 2.– 1993.– № 9.– С. 24-35.
6. Грамматика русского языка. Т. 1. Фонетика и морфология.– М.: АН СССР, 1953.– 720 с.
7. Копецкий Л. В. Лекции по фонетике и морфологии русского языка.– Praha: SPN, 1965.– 301 с.
Материал поступил е редакцию 20.02.98.
ISSH 0548-0027. НТИ .СЕР. 2. ИНФОРМ. ПРОЦЕССЫ И СИСТЕМЫ 1998. № 2