
Чернобай Юрій Олександрович
Факультет комп'ютерних наук і технологій
Спеціальність: Комп'ютерні системи і мережі
Тема магістерської роботи: Дослідження і розробка методів збору і обробки інформації в глобальній мережі
Науковий керівник: Теплінський Сергій Васильович
Дослідження і розробка методів збору і обробки інформації в глобальній мережі
Введення
У наш час в умовах глобалізації бізнесу, що вимагає різкого зниження витрат на виконання виробничих функцій, мобільності персоналу, можливості доступу до необхідної інформації і роботи з нею в будь-якій точці світу, неможливо уявити собі життя без систем збору і обробки інформації, головними показниками яких є підвищення рівнів збереження і доступності інформаційних ресурсів (інформаційних масивів, баз знань і програмних модулів) і ефективне управління ними.
Актуальність
Використання Internet технологій при створенні систем збору і обробки інформації і побудові інформаційних систем різного призначення найближчим часом стане домінуючим в світовому інформаційному просторі по наступних причинах. Ці технології:
- Дозволяють організувати з достатньою простотою для користувача системи пошуку потрібної інформації;
- Пред'являють мінімальні вимоги, як з технічного боку, так і з боку програмного забезпечення до робочого місця клієнта;
- Підтримують розподілені системи зберігання інформації і множинні методи її зберігання;
- Підтримують роботу з практично необмеженим об'ємом різнопланових даних;
- Надають технологічно простою спосіб адміністрування інформаційних систем з одного робочого місця;
- Підтримують видалені методи редагування і поповнення інформації.[7].
У зв'язку з цими тенденціями створення ІС онлайн оплати комунальних послуг є закономірним процесом. Із збільшенням популярності електронних грошей створенням безлічі Інтернет магазинів і аукціонів люди все більше хочуть оплачувати і отримувати послуги і товари, не виходячи з будинку через інтернет. Тому створення ІС онлайн оплати комунальних дозволить не лише заощадити час людей, яким не потрібно буде проводити годинами стоячи в чергах, але і автоматизувати і прискорити процес оплати. Також людина у будь-який час і в будь-якому місці може отримати інформацію за станом своєї заборгованості і тарифам на комунальні послуги в реальному часі, стан яких може бути змінене представниками послуг.
Методи збору і обробки інформації в глобальній мережі
Для здійснення збору і обробки інформації в глобальній мережі найчастіше використовуються розподілені інформаційні системи. Інформаційна система - сукупність технічного, програмного і організаційного забезпечення основним завданням якої є задоволення конкретних інформаційних потреб в рамках конкретної наочної області.[4]
Розподілені інформаційні системи по архітектурі можна розділити на двох основних типів:
1. Файл-cерверні ІС (ІС з архітектурою «файл-сервер»);
Файл-cерверні системи — системи, схожі по своїй структурі з локальними застосуваннями і що використовують мережевий ресурс для зберігання програми і даних. Функції сервера: зберігання даних і кодів програми. Функції клієнта: обробка даних відбувається виключно на стороні клієнта. Кількість клієнтів обмежена десятками.
Плюси: низька вартість розробки; висока швидкість розробки; невисока вартість оновлення і зміни ПО.
Мінуси: низька продуктивність (залежить від продуктивності мережі, сервера, клієнта); погана можливість підключення нових клієнтів; ненадійна система; обмеженість мови; негнучкість середовища розробки.[5]
2. Клієнт-серверні ІС (ІС з архітектурою «клієнт-сервер»).
Зазвичай під терміном «клієнт-сервер» розуміють архітектуру розрахованих на багато користувачів систем, яка передбачає наявність клієнтських і серверних програмних компонент. Клієнтські модулі використовуються на видалених робочих місцях користувачів, а централізовані серверні програми забезпечують обслуговування клієнтів, тобто прийом видалених запитів користувачів, їх обробку і повернення ним же результатів цієї обробки.[8]
Переваги:
- Робить можливим, в більшості випадків, розподілити функції обчислювальної системи між декількома незалежними комп'ютерами в мережі.
- Всі дані зберігаються на сервері, який, як правило, захищений набагато краще за більшість клієнтів.
- Використовувати ресурси одного сервера часто можуть клієнти з різними апаратними платформами, операційними системами і тому подібне
Недоліки:
- Непрацездатність сервера може зробити непрацездатною всю обчислювальну мережу;
- Підтримка роботи даної системи, вимагає окремого фахівця - системного адміністратора;
- Висока вартість устаткування.[6]
У свою чергу клієнт-серверна архітектура розділяється на декілька типів:
- Дворівнева архітектура «клієнт-сервер»;
- Трирівнева архітектура «клієнт-сервер»;
- Багаторівнева архітектура або n-рівнева архітектура.
Дворівнева архітектура «клієнт-сервер».
У випадку з дворівневою архітектурою «клієнт-сервер» база даних поміщається на мережевому сервері, проте програма клієнта позбавлена можливості прямого доступу до БД. Доступ до БД регулюється спеціальною програмою – сервером БД.
Взаємодію сервера БД і клієнта реалізується за допомогою sql-запітів, які формує і посилає серверу клієнт. Сервер, прийнявши запит, виконує його і повертає результат клієнтові. У клієнтському застосуванні в основному здійснюються інтерпретація отриманих від сервера даних, реалізація призначеного для користувача інтерфейсу, а також реалізація частини бізнес-правив.[9]
Але дворівнева архітектура не позбавлена недоліків, таких як:
- Погіршення продуктивності прямопропорціональна кількості користувачів;
- Незалежно від того, який тип клієнта використовується, велика частина обробки даних повинна знаходитися в базі даних, це означає, що вона повністю залежить від можливостей передбачених в базі даних виробником.
- Дворівнева архітектура настільки залежить від конкретної реалізації бази даних, що перенесення існуючих застосувань для різних СУБД, стає серйозною проблемою.[10]
Дворівнева архітектура «клієнт-сервер» зображена на рисунку 1.
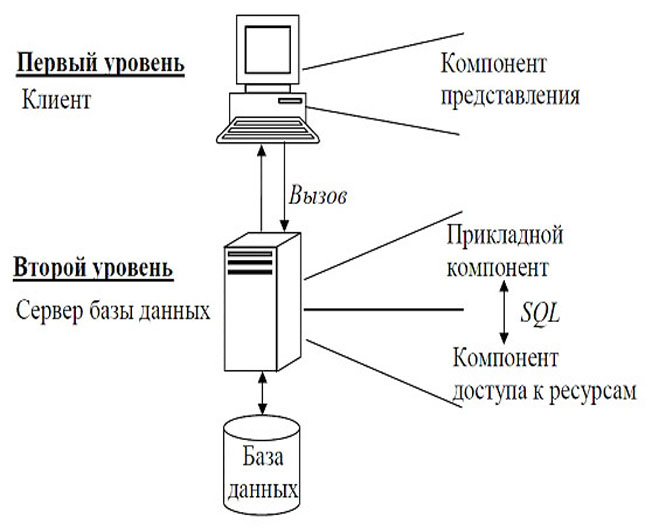
Рисунок. 1. Дворівнева архітектура «клієнт-сервер».[1]
Трирівнева архітектура «клієнт-сервер».
Другий спосіб взаємодії – трирівнева архітектура «клієнт-сервер». У цій моделі процес, що виконується на клієнтові, відповідає, за інтерфейс з користувачем. Звертаючись за виконанням послуг до прикладного компонента. Прикладний компонент реалізований як група процесів, що виконують прикладні функції, і називається сервером додатка. Всі операції над інформаційними ресурсами баз даних виконуються компонентамі доступу до ресурсів. Таким чином, на відміну від попередньої архітектури, обмін між клієнтом і сервером здійснюється за допомогою спеціально розробленого набору команд (API), а не SQL запитам. Набір цих команд визначається розробником, що дозволяє йому обмежити набір допустимих дій з даними доступним клієнтові. Трирівнева архітектура клієнт сервер представлена на малюнку 2.[9]
Введення додаткового рівня дозволяє здолати деякі обмеження дворівневої архітектури, описаних у загальних рисах вище. Як і з дворівневою моделлю, рівні можуть розташовуватися або на різних комп'ютерах (малюнок 2), або на одному комп'ютері в тестовому режимі.[10]
Рисунок 2. Трирівнева архітектура «клієнт-сервер».[1]
Багаторівнева архітектура “клієнт-сервер”.
Багаторівнева архітектура клієнт-сервер — різновид архітектури клієнт-сервер, в якій функція обробки даних винесена на один або декілька окремих серверів. Це дозволяє розділити функції зберігання, обробки і представлення даних для ефективнішого використання можливостей серверів і клієнтів.[6]
Трирівнева архітектура є окремим випадком багаторівневою, але якщо розглядати їх окремо те можна виділити декілька переваг багаторівневої архітектури перед трирівневою, такі як:
- Масштабованість. Навантаження розподіляється на декілька web-серверів, які взаємодіють з базою даних або з сервером наступного рівня.
- Захищеність. Використання декількох фізичних рівнів підвищує захищеність інформаційної системи від мережевих атак, а також функцію захист можуть виконувати всі рівні сервера, розподіляючи навантаження.
- Стабільність. При виводі з роботи одних з проміжних рівнів його функцію можуть розподіляти між собою останні рівні ідентичної функціональності. Хоча і продуктивність
в такій ситуації і загубиться, але система не буде виведена з роботи як у випадку з трирівневою системою.
Багаторівнева архітектура зазвичай складається з чотирьох рівнів (рисунок 3), де в мережі сервер відповідає за обробку з'єднання між клієнтом браузером і сервером системи.[10]
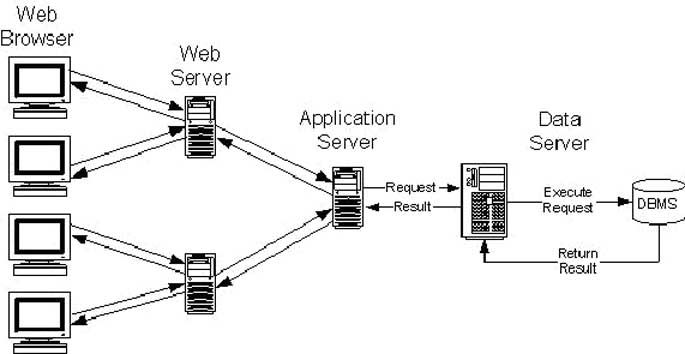
Рисунок 3. Багаторівнева архітектура «клієнт-сервер».[10]
Цілі і завдання магістерської роботи
Розглянувши існуючі методи збору і обробки інформації, в магістерській роботі ставляться наступні завдання:
- Проаналізувати і порівняти різні методи організації n-рівневої архітектури «клієнт-сервер»;
- Вивчити існуючі методи розподілу навантаження сервера, і розробити власний метод рівномірного розподілу підключень до серверів;
- Розробити систему онлайн оплати комунальних послуг на основі багаторівневої архітектури «клієнт-сервер» використовуючи отримані результати дослідження;
- Розробити власний протокол обміну інформацією між клієнтом і сервером, використовуючи для передачі формат даний XML (текстовий формат, призначений для зберігання структурованих даних);
- На базі розробленої системи проаналізувати масштабованість і продуктивність системи залежно від збільшення кількості проміжний серверів.
Практична цінність і наукова новизна
Проектована система – це програмний продукт, який дозволяє здійснювати онлайн оплату комунальних послуг. Використання багаторівневої архітектури «клієнт-серверного» застосування дозволяє одночасно в режимі реального часу обслуговувати велику кількість клієнтів одночасно.
Наукова новизна роботи полягає в тому, що буде створена система збору і обробки даних на основі багаторівневої архітектури «клієнт-сервер». Основна особливість системи полягає в тому, що буде створена розподілена серверна частина, яка залежно від навантаження на сервер може бути розширена на фізичному рівні. А також буде досліджено збільшення продуктивності при розширенні.
Практичні результати
Були розглянуті методи збору і обробки інформації в глобальній мережі, проаналізовані недоліки і переваги кожного з методів. Також була розроблена програма онлайн оплати комунальних послуг на базі трирівневої архітектури «клієнт-сервер».
У розробленій системі клієнтська програма, написана на actionscript 3, завантажується на комп'ютер користувача як звичайний флеш файл з сервера. Запускаючись, ця програма підключається до сервера, написаного на C#, що використовує базу даних MS SQL. Запити клієнта передаються у форматі XML, який на стороні сервера розшифровується і на основі отриманих даних формується Sql запит до бази. При цьому сервер перед формуванням запиту перевіряє всі команди, що приходять. Набір команд обміну між сервером і клієнтом дуже обмежений і дозволяє виконувати лише певний набір дій з базою даних. Проте такий підхід для створення вузько спеціалізованих СУБД виправдовує малу функціональність великою захищеністю бази даних. Формат XML дуже зручний для передачі даних, але він є відкритим і зрозумілим навіть для звичайної людини. Отже для захисту даних користувачів при передачі по мережі використовуються стандартні методи шифрування даних. Що реалізовується програма-клієнт розташовуватиметься на комп'ютері зі встановленим http сервером, і буде доступна будь-якому користувачеві, що має доступ в Інтернет. Завантажуватися на комп'ютер користувача і запускатися вона буде як звичайний флеш-ролік через браузер, і не вимагатиме додаткової установки. Для роботи програми-клієнта на комп'ютері користувача повинен буде встановлений будь-який браузер і Flash Player версії не нижче 10.0. Програма сервер для більшої безпеки може розташовуватися на будь-якій іншій серверній машині без встановлених http і ftp серверів і захищеною firewall-ом. Така локалізація частин програм значно підвищує безпеку сервера з базами даних і унеможливлює видаленого доступу до файлів програми і бази даних.[9]
Також в майбутньому заплановано розширення системи до чотирьохрівневої архітектури, реалізація алгоритму рівномірного розподілу клієнтів між серверами, а також проаналізувати масштабованість і продуктивність системи залежно від збільшення кількості проміжних серверів.
Висновок
Дана магістерська робота присвячена актуальній темі створення інформаційної системи, використовуючи багаторівневу архітектуру клієнт-сервера. Постійному розвитку і удосконаленню таких систем сприяє стрімкий розвиток Інтернет технологій.
Проаналізовані в роботі методи збору і обробки інформації дозволяють створити стабільну і гнучку в масштабуванні систему.
Слід зазначити, що в Україні немає компаній, що спеціалізуються на створенні подібних інформаційних систем. Зазвичай такі системи в міру необхідності розробляються групами програмістів, що не мають досвіду розробки в цій сфері діяльності, що приводить до нераціонального використання ресурсів, неефективній роботі системи і постійному доопрацюванні і виправленні створеної системи.
Література
- Маркин А.В. Построение запросов и програмирование на SQL / А.В. Маркин // Рязань 2008. 312с.
- Вийера Р. Програмирование баз данных Microsoft SQL Server 2005 для профессионалов / Р. Вийера // 2008. 256с.
- Шаньгин В. Компьютерная безопасность информационных систем. / В. Шаньгин // 2008 416c.
- Информационная система. Википедия свободная энциклопедия [Электронный ресурс] Режим доступа: http://ru.wikipedia.org/wiki/Информационная_система.
- Файл-сервер. Википедия свободная энциклопедия [Электронный ресурс] Режим доступа: http://ru.wikipedia.org/wiki/Файл-сервер.
- Клиент-сервер. Википедия свободная энциклопедия [Электронный ресурс] Режим доступа: http://ru.wikipedia.org/wiki/Клиент-сервер.
- Шокин Ю.И., Федотов А.М. Распределенные информационные системы [Электронный ресурс] Режим доступа: http://old.ict.nsc.ru/win/gis/lib/publ/inf_sys.html.
- Вышинский Л.Л., Гринев И.Л., Флеров Ю.А., Широков А.Н., Широков Н.И. Генератор проектов инструментальный комплекс для разработки «клиент-серверных» систем [Электронный ресурс] Режим доступа: http://ict.informika.ru/ft/002154/journ1-2_page6_25.pdf.
- Чернобай Ю.А., Романченко П.К. Теплинский С. В. Безопасность организации системы онлайн оплаты коммунальных услуг [Электронный ресурс] Режим доступа: ../library/tez1.htm.
- Крамек Э. Перевод: Чернобай Ю. А.. Введение в архитектуру клиент-серверных систем [Электронный ресурс] Режим доступа: ../library/translate.htm.