
Автореферат
Введение
При установлении диагноза и проведении лечения врачи все больше полагаются на медицинские изображения, к которым относятся рентгенограммы, УЗИ, магнитно-резонансная томография (MRI - Magnetic Resonance Imaging), компьютерная томография (CT - Computed Tomography), томография на позитивном излучении (PET – Positive Emission Tomography) и т.д. Использование медицинских изображений растет с каждым годом, в следствии внедрения новейшей медицинской техники в больницах и диагностических центрах.
Объекты на медицинских изображениях обладают большой сложностью и многофакторностью, что обусловливает высокие требования к надёжности, точности и достоверности результатов исследований. Быстрое развитие цифровой и аналоговой техники в последнее время открывает новые возможности перед разработчиками. Например, увеличение быстродействия вычислительной техники позволяет использовать сложные, критичные ко времени алгоритмы, а благодаря появлению цветных телевизионных датчиков высокого разрешения можно получать и обрабатывать цветные изображения. Именно новые технические возможности позволяют значительно расширить круг исследований, открывают новые пути решения задач, касающихся анализа изображений
Актуальность
Сегодня весь мир стремится к автоматизации процессов во всех сферах жизни человека. Медицина – не исключение. С каждым годом все больше медицинской техники появляется в больницах и поликлиниках. Именно новые технические возможности позволяют значительно расширить круг исследований, открывают новые пути решения задач.
В следствии этого появляется больше информации, значительная часть которых содержится в изображениях.
Постановка задачи
Медицинские изображения дают основной объем информации о пациенте, для извлечения которой,
требуется их анализ. Одной из главных частей автоматизации измерения оптических и геометрических параметров является
выделение объектов на препаратах. Эта задача решается с помощью методов и средств цифрового анализа изображений.
Сегментация медицинского изображения является сложной задачей, методы для решения которой выбираются в соответствии
с характеристиками и свойствами анализируемого изображения.[2]
Научная новизна
Алгоритм муравьиных колоний применим во многих задачах оптимизацизации, особенно, на графах. В большинстве своем он дает положительный эффект.
Применяя его к алгоритмам сегментации мы получаем большую эффективность. В данный момент разработки в такой плоскости производятся, но практическое применение его в широкомасштабных
проектах лишь в перспективе.
Кластеризация методом К-средних
Кластеризация методом К-средних — хорошо известный метод определения принадлежности элементов кластерам с помощью минимизации разницы между элементами кластера и максимизации расстояния между кластерами. Слово «средние» в названии метода относится к центроидам кластеров. Центроид — точка данных, которая выбирается произвольно, а затем итеративно уточняется, пока не начинает представлять собой истинное среднее всех точек данных кластера. «К» означает произвольное количество точек, используемых для формирования начальных значений процесса кластеризации. Алгоритм К-средних вычисляет квадраты евклидовых расстояний между записями данных в кластере и вектор, представляющий собой среднее данного кластера. Метод сходится, выдавая окончательный набор из К кластеров, когда упомянутая сумма минимизирована.
Алгоритм К-средних назначает каждой точке данных ровно один кластер и не допускает неопределенности в принадлежности точки кластеру. Принадлежность к классу выражается расстоянием от центроида.
Обычно алгоритм К-средних используется для создания кластеров непрерывных атрибутов, для которых несложно вычислить расстояние до среднего. Однако реализация Майкрософт использует метод К-средних и для кластеризации дискретных атрибутов с помощью вероятностей.[3] Алгоритм муравьиных колоний
Идея муравьиного алгоритма – моделирование поведения муравьёв, связанного с их способностью
быстро находить кратчайший путь от муравейника к источнику пищи и адаптироваться к изменяющимся условиям, находя
новый кратчайший путь. При своём движении муравей оставляет на своем пути феромон, и эта информация используется
другими муравьями для выбора пути. Это элементарное правило поведения и определяет способность муравьёв находить
новый путь, если старый оказывается недоступным.
Рассмотрим случай, показанный на рисунке 1.
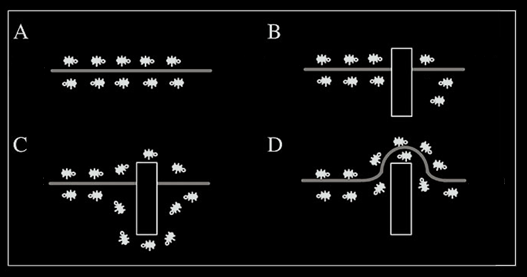
Когда на оптимальном пути (Рисунок 1.А) возникает преграда (Рисунок 1.В) муравью необходимо определить новый оптимальный путь. Дойдя до преграды, муравьи с равной вероятностью будут обходить её справа и слева. То же самое будет происходить и на обратной стороне преграды. Однако, те муравьи, которые случайно выберут кратчайший путь, будут быстрее его проходить, и за несколько передвижений он будет более обогащён феромоном. Поскольку движение муравьёв определяется концентрацией феромона, то следующие будут предпочитать именно этот путь (Рисунок 1.D), продолжая обогащать его феромоном до тех пор, пока этот путь по какой-либо причине не станет недоступен.
Очевидная положительная обратная связь быстро приведёт к тому, что кратчайший путь станет единственным маршрутом движения большинства муравьёв. Моделирование испарения феромона – отрицательной обратной связи – гарантирует нам, что найденное локально оптимальное решение не будет единственным – муравьи будут искать и другие пути. Если мы моделируем процесс такого поведения на некотором графе, рёбра которого представляют собой возможные пути перемещения муравьёв, в течение определённого времени, то наиболее обогащённый феромоном путь по рёбрам этого графа и будет представлять решение задачи, полученное с помощью муравьиного алгоритма.[1]
Базовый муравьиный алгоритм, независимо от модификаций, можно представить в виде схемы (Рисунок 2)

Инициализация муравьёв - стартовая точка, куда помещается муравей, зависит от ограничений, накладываемых условиями задачи. Потому что для каждой задачи способ размещение муравьёв является определяющим. Либо все они помещаются в одну точку, либо в разные с повторениями, либо без повторений. На этом же этапе задаётся начальный уровень феромона. Он инициализируется небольшим положительным числом для того, чтобы на начальном шаге вероятности перехода в следующую вершину не были нулевыми.
 представляет множество возможных вершин, связанных с вершиной i, для муравья k, τ (ij)- уровень феромона,
d(ij) – эвристическое расстояние, α и β – константные параметры.
Обновление феромона происходит в соответствии с формулой 2.
представляет множество возможных вершин, связанных с вершиной i, для муравья k, τ (ij)- уровень феромона,
d(ij) – эвристическое расстояние, α и β – константные параметры.
Обновление феромона происходит в соответствии с формулой 2.
 – феромон, откладываемый k-ым муравьём, использующим ребро (i,j).
– феромон, откладываемый k-ым муравьём, использующим ребро (i,j).
Для того чтобы построить соответствующий муравьиный алгоритм для решения какой-либо задачи, необходимо:
1. представить задачу в виде набора компонент и переходов или набором неориентированных взвешенных графов, на которых муравьи могут строить решения;
2. определить значение следа феромона;
3. определить эвристику поведения муравья, когда строим решение;
4. если возможно, то реализовать эффективный локальный поиск;
5. выбрать специфический муравьиный алгоритм и применить для решения задачи;
6. настроить параметры алгоритма. [3]
Рассмотрим алгоритм кластеризации изображения, основанный на алгоритме муравьиных колоний. В этом алгоритме муравьи представляются простыми агентами, которые случайным образом перемещаются по дискретному массиву. Пикселы, которые рассеяны в элементах массива могут быть перемещены из одного элемента массива в другой, формируя кластеры. Перемещение пикселов косвенным образом определяется поведением муравьев. Каждый муравей может присоединять или исключать пиксел согласно функции, которая вычисляет сходство пиксела с другими пикселами в кластере. Таким образом, муравьи динамически кластеризируют изображение на независимые кластеры, которые включают только сходные между собой пикселы. Кроме этого агент представляет новые вероятностные правила для присоединения или исключения пикселов, а так же стратегию локального перемещения для ускорения сходимости алгоритма.
Предположим, размерность массива равна N. Каждый элемент этого массива связан с гнездом муравьев в определенном порядке, что позволяет муравьям легко переходить от одного элемента к другому. В процессе алгоритма муравьи могут изменять, строить или убирать существующие кластеры пикселов. Кластер представляется соединением двух или более пикселов и пространственно расположен в отдельной ячейке массива, что упрощает его идентификацию.
Инициализируем N пикселов {Р1,…,Рn} для кластеризации, расположенные в массиве таким образом, что каждый элемент массива связан только с одним пикселом. Каждый муравей а(i) из колонии с К муравьями {a(1),…,а(k)} присоединяет случайно выбранный пиксел из элементов массива и возвращается в гнездо.
После начального этапа инициализации происходит этап кластеризации. Выбор муравья производится случайным образом. Он перемещается от своего гнезда к элементам массива и определяет с помощью вероятностного правила, присоединять ли этот пиксел к кластеру. Каждый муравей знает список расположения пикселов, которые не были присоединены другими муравьями. Случайным образом муравей определяет следующий пиксел из списка свободных. Этот алгоритм повторяется для каждого муравья. Алгоритм останавливается при прохождении заданного количества итераций.[4]
• сегментировать данным алгоритмом все изображения не хуже заданного уровня (сравнение на «не хуже» осуществляется субъективно самими пользователями, для сравнения даётся какой-то образец сегментации). После чего определяется самый быстрый алгоритм;
• за заданное ограниченное время, как можно лучше выполнить сегментацию данных изображений. По истечении положенного срока, пользователь субъективно оценивает, какой алгоритм дал лучшую сегментацию.
Для грубой оценки качества метода в конкретной задаче обычно фиксируют несколько свойств, которыми должна обладать хорошая сегментация. Качество работы метода оценивается в зависимости от того, насколько полученная сегментация обладает этими свойствами. Наиболее часто используются следующие свойства:
• однородность регионов (однородность цвета или текстуры);
• непохожесть соседних регионов;
• гладкость границы региона;
• маленькое количество мелких «дырок» внутри региона.[8]
Рассмотрим случай, показанный на рисунке 1.
Рисунок 1 -Пути прохождения муравьев от “дома” к пище.
Когда на оптимальном пути (Рисунок 1.А) возникает преграда (Рисунок 1.В) муравью необходимо определить новый оптимальный путь. Дойдя до преграды, муравьи с равной вероятностью будут обходить её справа и слева. То же самое будет происходить и на обратной стороне преграды. Однако, те муравьи, которые случайно выберут кратчайший путь, будут быстрее его проходить, и за несколько передвижений он будет более обогащён феромоном. Поскольку движение муравьёв определяется концентрацией феромона, то следующие будут предпочитать именно этот путь (Рисунок 1.D), продолжая обогащать его феромоном до тех пор, пока этот путь по какой-либо причине не станет недоступен.
Очевидная положительная обратная связь быстро приведёт к тому, что кратчайший путь станет единственным маршрутом движения большинства муравьёв. Моделирование испарения феромона – отрицательной обратной связи – гарантирует нам, что найденное локально оптимальное решение не будет единственным – муравьи будут искать и другие пути. Если мы моделируем процесс такого поведения на некотором графе, рёбра которого представляют собой возможные пути перемещения муравьёв, в течение определённого времени, то наиболее обогащённый феромоном путь по рёбрам этого графа и будет представлять решение задачи, полученное с помощью муравьиного алгоритма.[1]
Базовый муравьиный алгоритм, независимо от модификаций, можно представить в виде схемы (Рисунок 2)
Рисунок 2 - Обобщенный муравьиный алгоритм.
(анимация: объем - 7,4 КБ; размер - 400x400; количество кадров - 25; задержка между кадрами - 5 мс; задержка между последним и первым кадрами - 5 мс;количество циклов повторения - бесконечно.)
(анимация: объем - 7,4 КБ; размер - 400x400; количество кадров - 25; задержка между кадрами - 5 мс; задержка между последним и первым кадрами - 5 мс;количество циклов повторения - бесконечно.)
Инициализация муравьёв - стартовая точка, куда помещается муравей, зависит от ограничений, накладываемых условиями задачи. Потому что для каждой задачи способ размещение муравьёв является определяющим. Либо все они помещаются в одну точку, либо в разные с повторениями, либо без повторений. На этом же этапе задаётся начальный уровень феромона. Он инициализируется небольшим положительным числом для того, чтобы на начальном шаге вероятности перехода в следующую вершину не были нулевыми.
Поиск решений.
Вероятность перехода из вершины i в вершину j определяется согласно формулы 1: (1)
(1)
представляет множество возможных вершин, связанных с вершиной i, для муравья k, τ (ij)- уровень феромона,
d(ij) – эвристическое расстояние, α и β – константные параметры.
Обновление феромона происходит в соответствии с формулой 2. (2)
(2)
– феромон, откладываемый k-ым муравьём, использующим ребро (i,j).
Этапы решения задачи при помощи муравьиных алгоритмов.
Для того чтобы построить соответствующий муравьиный алгоритм для решения какой-либо задачи, необходимо:
1. представить задачу в виде набора компонент и переходов или набором неориентированных взвешенных графов, на которых муравьи могут строить решения;
2. определить значение следа феромона;
3. определить эвристику поведения муравья, когда строим решение;
4. если возможно, то реализовать эффективный локальный поиск;
5. выбрать специфический муравьиный алгоритм и применить для решения задачи;
6. настроить параметры алгоритма. [3]
Применение алгоритма муравьиных колоний к задаче сегментации изображений.
Поскольку в основе муравьиного алгоритма лежит моделирование передвижения муравьёв по некоторым путям графа,
то такой подход является эффективным способом поиска рациональных решений для задач оптимизации, в первую очередь,
на графах. Рассмотрим алгоритм кластеризации изображения, основанный на алгоритме муравьиных колоний. В этом алгоритме муравьи представляются простыми агентами, которые случайным образом перемещаются по дискретному массиву. Пикселы, которые рассеяны в элементах массива могут быть перемещены из одного элемента массива в другой, формируя кластеры. Перемещение пикселов косвенным образом определяется поведением муравьев. Каждый муравей может присоединять или исключать пиксел согласно функции, которая вычисляет сходство пиксела с другими пикселами в кластере. Таким образом, муравьи динамически кластеризируют изображение на независимые кластеры, которые включают только сходные между собой пикселы. Кроме этого агент представляет новые вероятностные правила для присоединения или исключения пикселов, а так же стратегию локального перемещения для ускорения сходимости алгоритма.
Предположим, размерность массива равна N. Каждый элемент этого массива связан с гнездом муравьев в определенном порядке, что позволяет муравьям легко переходить от одного элемента к другому. В процессе алгоритма муравьи могут изменять, строить или убирать существующие кластеры пикселов. Кластер представляется соединением двух или более пикселов и пространственно расположен в отдельной ячейке массива, что упрощает его идентификацию.
Инициализируем N пикселов {Р1,…,Рn} для кластеризации, расположенные в массиве таким образом, что каждый элемент массива связан только с одним пикселом. Каждый муравей а(i) из колонии с К муравьями {a(1),…,а(k)} присоединяет случайно выбранный пиксел из элементов массива и возвращается в гнездо.
После начального этапа инициализации происходит этап кластеризации. Выбор муравья производится случайным образом. Он перемещается от своего гнезда к элементам массива и определяет с помощью вероятностного правила, присоединять ли этот пиксел к кластеру. Каждый муравей знает список расположения пикселов, которые не были присоединены другими муравьями. Случайным образом муравей определяет следующий пиксел из списка свободных. Этот алгоритм повторяется для каждого муравья. Алгоритм останавливается при прохождении заданного количества итераций.[4]
Оценка качества работы алгоритмов.
Как видно, сама постановка задачи не является четкой. Как оценить априорное представление пользователя о разбиении объектов? В автоматической сегментации, для построения меры качества разбиения, используются предположения о том, что подобие (похожесть) цвета пикселов, текстуры внутри одного объекта должна быть максимальной, а между объектами - минимальной. В интерактивной сегментации пользователь может добавлять новые ограничения, уточнять входную информацию до тех пор, пока не получит ожидаемого результата. Можно было бы оценивать качество сегментации при одних и тех же подсказках, но различные алгоритмы получают различную входную информацию от пользователя.
В интерактивной сегментации также предполагается, что пользователь при помощи «подсказок» алгоритму, должен иметь возможность сегментировать объект даже в тех случаях, когда его часть и по цвету и по текстуре ближе фону, чем оставшейся части объекта. Это тоже затрудняет создание объективных метрик.
Поэтому естественно, что для сравнения алгоритмов интерактивной сегментации чаще всего используют субъективное сравнение: берется несколько изображений, и нескольким пользователям ставится одна из 2 задач:• сегментировать данным алгоритмом все изображения не хуже заданного уровня (сравнение на «не хуже» осуществляется субъективно самими пользователями, для сравнения даётся какой-то образец сегментации). После чего определяется самый быстрый алгоритм;
• за заданное ограниченное время, как можно лучше выполнить сегментацию данных изображений. По истечении положенного срока, пользователь субъективно оценивает, какой алгоритм дал лучшую сегментацию.
Для грубой оценки качества метода в конкретной задаче обычно фиксируют несколько свойств, которыми должна обладать хорошая сегментация. Качество работы метода оценивается в зависимости от того, насколько полученная сегментация обладает этими свойствами. Наиболее часто используются следующие свойства:
• однородность регионов (однородность цвета или текстуры);
• непохожесть соседних регионов;
• гладкость границы региона;
• маленькое количество мелких «дырок» внутри региона.[8]
Вывод.
Хотя алгоритмы обработки изображений могут обеспечить получение точных количественных показателей (например,
измерение фракции выброса левого желудочка сердца по динамической последовательности изображений) или могут
решать некоторые задачи, которые невыполнимы при ручной обработке (например, точная регистрация мультимодальных
изображений), проблемы надежности и ответственности остаются главными препятствиями на пути широкомасштабного
использования этих алгоритмов. Проверка правильности алгоритма часто бывает затруднительна из-за отсутствия теории,
позволяющей количественно сравнивать результаты обработки.[7] Литература.
1. Информационные управляющие системы и компьютерный мониторинг 2010/ Сборник материалов к I Всеукраинской научно-технической конференции студентов, аспирантов и молодых ученых.- Донецк,ДонНТУ-2010, с.12-16. 2.Винсент Бретон. Медицинские изображения и их обработка
3. Методы сегментации изображений: интерактивная сегментация. Вадим Конушин, Владимир Вежневец
4. Image Segmentation Using ACO. Manda M. Ukey, Dr. V. M. Thakare
5. Swarm Intelligence: Focus on Ant and Particle Swarm Optimization, Book edited by: Felix T. S. Chan and Manoj Kumar Tiwari, ISBN 978-3-902613-09-7, pp. 532, December 2007, Itech Education and Publishing, Vienna, Austria
6. N. R. Pal and S. K. Pal, “A Review on Image Segmentation Techniques,” Pattern Recognition, Vol. 26, No 9, 2000
7. R. Jain, R. Kasturi, and B. G. Schunck, Machine Vision, 2005
8. S.-T. Bow, Pattern Recognition and Image Preprocessing, Marcel Dekker, Inc., New York, NY, 2006.