
Реферат за темою випускної роботи
Зміст
1. Вступ.
2. Актуальність і мотивація теми роботи.
3. Цілі й завдання, які повинні вирішуватися.
4. Гіпотетична наукова новизна.
5. Плановані практичні результати.
6. Огляд досліджень і розробок по темі.
8. Розробка алгоритму очищення від інформаційного шуму.
9. Висновки, перелік основних результатів і перспектив дослідження.
10. Література.
Вступ
XXI століття стане етапним для проникнення нових інформаційних технологій в усі сфери людської діяльності - керування, виробництво, науку, освіту і т.д.
Висока доступність величезної кількості інформації, що постійно поповнюється, а також зростаюча популярність веб-послуг серед всіх категорій користувачів загострили проблему виділення значимої для користувача частини інформації.
Особливістю представлення документів у мережі Інтернет є наявність на сторінці, крім самого тексту (змістовної частини web-документа) [8] який визначає предмет сторінки, великої кількості допоміжних елементів, таких як навігаційні посилання, версія для друку, «дорожні знаки» (посилання, що показують шлях від головної сторінки сайту до поточної), блоки тексту з рекламою інших розділів сайту, контактні дані компанії й т.п. (так звана службова інформація), покликаних забезпечити навігацію по сторінках сайту. Часто ці елементи не мають прямого відношення до теми сторінки й тому можуть негативно впливати на якість сприйняття інформації користувачем.
Таке різноманіття даних ховає в собі проблеми, які можуть виникнути при аналізі необхідної інформації в Інтернеті:
- Проблема перевантаженості веб-сторінок різною не важливої для користувача інформацією: спамом, рекламою, усілякими посиланнями. Найчастіше при візуальній фільтрації контенту й оцінці його значимості користувач втрачає масу часу.
- Відсутність персоналізації веб-простору – задача по створенню засобів, що адаптують свої можливості (навігація, контент, банери й інші рекламні пропозиції) під користувача на підставі зібраної й проаналізованої інформації про користувацькі переваги [6].
Актуальність і мотивація теми роботи
Найчастіше при візуальній фільтрації контенту й оцінці його значимості користувач втрачає масу часу. Для вирішення цієї проблеми необхідно застосовувати очищення веб-сторінок від інформаційного шуму. Позначимо кілька галузей, для яких можна буде застосувати задачу очищення веб-сторінок:
- сервіси доставки контенту, коли інші способи з якихось причин не підходять (наприклад, RSS стрічка відсутня) [11];
- системи по збору деякої інформації з різних джерел
- у мобільних додатках, де важливо мінімізувати трафік
- системах data mining(data mining — це процес виявлення в сирих даних раніше невідомих, нетривіальних, практично корисних і доступних інтерпретації знань, необхідних для прийняття розв'язків у різних сферах людської діяльності.)
Задача очищення веб-сторінок від інформаційного шуму досить актуальна в наш час і вирішення даної проблеми допоможе підносити шукану користувачем інформацію в зручному для нього виді, а так само позитивно позначиться на результатах web-пошуку, класифікації інформації, витяг текстової інформації й т.п.
Цілі й завдання, які повинні вирішуватися
Ціль роботи – створення загальнодоступних інструментальних засобів, що дозволяють очистити web сторінки від інформаційного шуму.
Для досягнення поставленої мети необхідно вирішити основні завдання:
- Здійснити порівняльний аналіз методів виділення основного контенту web-сторінки
- Розробити класифікаційну схему інформаційних блоків сайту
- Розробити адаптаційний алгоритм оцінки інформаційних блоків сторінок
- Розробити інструментальні засоби, що дозволяють обробляти певні інформаційні блоки
- Провести тестування ефективності розроблених інструментальних засобів
Гіпотетична наукова новизна
- Запропонована нова класифікаційна схема інформаційних блоків сайтів, з набором значень параметрів, яка враховує структуру й специфіку сайту
- Розроблена модель очищення веб-станиць від інформаційного шуму на основі класифікаційної схеми блоків
Плановані практичні результати
Планована практична значимість роботи полягає в розробці інструментальних засобів очищення web-сторінок від інформаційного шуму.
Застосування розроблених засобів дозволить користувачеві легко й швидко одержати основний контент web-сторінки не відволікаючись на інформацію не несуче значеннєве навантаження.
Розроблені інструментальні засоби дозволять виконувати наступні завдання:
- Приховання банерів, рекламних блоків, мультимедійного контенту, що не несе значеннєве навантаження й відволікаючого увагу користувача
- Адаптація представлення інформації на сайті під запити користувача
Огляд досліджень і розробок по темі
Застосовувані методи аналізу структури web-сторінок можна розділити на:
- Методи, засновані на виділенні повторюваних для всіх (або частини) сторінок сайту фрагментів інформації [1]
- Методи, засновані на аналізі dom-дерев сторінок сайту [3]
- Комбіновані методи [2]
- Методи синтаксичного й візуального аналізу [5]
- Методи аналізу сторінок побудованих на HTML 5 [4]
Аналіз існуючих методів виділення основного веб-контенту показав, що методи, засновані на аналізі DOM дерева ефективні й прості, а також надають можливість здійснювати обробку одиничної веб-станиці.
Існують інструментальні засоби, які частково вирішують завдання виділення основного веб-контенту:
NoScript – це доповнення для Firefox, яке дозволяє захистити браузер від будь-яких скриптів, які, як відомо, завжди потенційно небезпечні.
AdBlock Plus – є самим популярним розширенням браузера Firefox, що дозволяє блокувати завантаження й показ різних елементів сторінки
Flash Block – його призначення полягає в блокування Flash-Контенту. Останній часто являє собою банери
Safari Reader – функція браузера Safari, дозволяє в більш зручному форматі читати статті й блоги, забираючи все сміття, яке може відволікати увагу
Readability – букмарклет(маленька Javascript-Програма, оформлена як URL, що й зберігається як закладка браузера) яка позбавляє веб-сторінку від рекламного сміття
Всі ці засоби, в основному спрямовані на боротьбу з рекламою. Проведений огляд існуючих інструментальних засобів очищення веб-сторінок від інформаційного шуму дозволив виділити основні труднощі, з якими зустрічаються користувачі:
- Блокування корисного для користувача контенту
Найчастіше системи виділення основного контенту разом з навігацією й банерами блокують і корисну інформацію для користувача (наприклад, посилання на супутні статті та інше), причому користувачеві дана інформація стане доступною лише при скасуванні обробки веб-сторінки. - Не універсальність
Безліч існуючих засобів розроблені під конкретний браузер, що приводить до звуження категорії користувачів. - Відсутність адаптації під конкретного користувача
Огляд показав, що при роботі виділення основного контенту веб-сторінки інструментальні засоби ґрунтуються на загальнім сприйнятті поняття «корисна інформація» – блок текстової інформації, що не завжди відповідає запитам користувача. - Недостатня ефективність
Походячи із усього вищесказаного, можна зробити висновок, що розробка інструментальних засобів очищення веб-сторінок від інформаційного шуму ведеться досить активно, але поки не існує універсальних засобів, які б могли задовольнити всі запити користувачів.
Математична постановка
Очищена сторінка від інформаційного шуму представляється у вигляді:
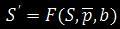
Де 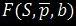 – функція очищення,
– функція очищення,
S – вихідний сайт,
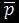 – параметри обробки, що задаються користувачами. Даний параметр задається у випадку коли при обробці відбулося відсікання важливої інформації для користувача. Користувачі відзначають блок контенту який необхідно відобразити, при цьому встановлюється значення для .
– параметри обробки, що задаються користувачами. Даний параметр задається у випадку коли при обробці відбулося відсікання важливої інформації для користувача. Користувачі відзначають блок контенту який необхідно відобразити, при цьому встановлюється значення для .
b – параметр блоку контенту, який визначається по наступній формулі:

Де g – функція визначення властивостей умісту сайту
Значення параметра блоку контенту й визначення властивостей його вмісту зведемо в Табл.1
Таблиця 1 – Ознаки типів інформаційних блоків контенту
| № | Ознаки блоку | Значимість блоку |
0 |
наявність великої кількості зображень
|
Інформаційний шум |
1 |
наявність великої кількості гіперпосилань |
Несуттєва інформація |
2 |
наявність графічного, мультимедійного, відео контенту |
Важлива інформація |
Аналіз питання очищення web-сторінок від інформаційного шуму дав можливість визначити кілька типів сайтів походячи з відповідних їм характерним ознакам і їх значення. Типи сайтів і ознаки характерні для них були зведені в табл.2
Таблиця 2 – Ознаки типів сайтів
| Типи сайтів | Характерні ознаки |
Для цих сайтів характерно висока кількість інформативних зображень, тобто зображень які будуть корисні для користувача й можуть вважатися корисним контентом |
|
Для даних сайтів характерно висока кількість посилань, які можуть вважатися корисним контентом |
Розробка алгоритму очищення від інформаційного шуму
Прийнявши до уваги всі сильні й слабкі сторони існуючих інструментальних засобів, зупинимо свій вибір на ідеї створення букмарклета.
Букмарклет(bookmarklet) – це javascript-код, який зберігається як закладка в браузері. Він працює за рахунок використання протоколу < a href="javascript:..."> [10].
Алгоритм очищення web-сторінок від інформаційного шуму складається з наступних етапів:
- Букмарклет одержує адресу сторінки для її обробки.
- Для заданої сторінки визначається структура DOM дерева з Html-Коду.
- Відбувається прохід по DOM дереву й класифікація тегів(вузлів) по відповідних до ознак.
- Далі визначаються значимі вузли.
- Система обробляє інформаційні блоки, виділяє блок основного контенту, відсікаючи теги, позначені як інформаційний шум (медіа, навігація, посилання та інше).
- Оброблена сторінка відображається для користувача.
- У випадку, якщо відбулося відсікання важливої інформації, користувач скасовує обробку. Сторінка відображається йому в первинному виді з рамками навколо різних блоків контенту. Відзначивши потрібний блок, користувач зберігає результат. Сторінка знову проходить обробку, у ході якої відзначені користувачем блоки відсікатися не будуть. Оброблена сторінка відображається для користувача разом з повідомленням, у якім буде запропоновано зберегти результати обробки сторінки в системі.
- Адреса оброблюваної сторінки й результати її обробки зберігаються.

Рис. 1 – Блок-схема алгоритму роботи букмарклета
Висновки, перелік основних результатів і перспектив дослідження
Очищення web-сторінок від інформаційного шуму є одним з перспективних напрямків розвитку галузі інформаційно – комунікаційних технологій .
Свідченням актуальності виділення основного контенту сторінки по запитах користувачів є постійне вдосконалювання програмного інструментарію для формування й відображення web-сторінок. В умовах насичення ринку технологічних послуг все більша увагу привертають методи й засоби персоналізації потоків контенту.
Література:
- Агєєв М.С., Добров Б.В., Лукашевич М.В., Сідоров О.В. Експериментальні алгоритми пошуку/класифікації й порівняння з «basic line». Російський семінар по Оцінці Методів Інформаційного Пошуку (РОМІП 2004) [електронний ресурс]. Режим доступу – http://romip.narod.ru/...
- І. Некрестьянов, Е. Павлова. Виявлення структурної подоби Html-Документів. [електронний ресурс]. Режим доступу – http://meta.math.spbu.ru
- М.С. Агєєв, І.В. Вершинников, Б.В. Добров. Витяг значимої інформації з web-сторінок для завдань інформаційного пошуку.// Інтернет-Математика 2005. Збірник робіт із програм наукових стипендій Яндексу. Москва, 2005.
- Р.Ф. Кузнєцов, Н.В. Мурашов. Оцінка впливу добування значимої інформації на якість класифікації web-сторінок
- Визначення поняття «інформаційний шум» [електронний ресурс]. Режим доступу – http://mediart.ru/...
- Yi, L., Liu, B., Web Page Cleaning for Web Mining through Feature Weighting, in the proceedings of Eighteenth International Joint Conference on Artificial Intelligence (IJCAI-03), Acapulco, Mexico, August, 2003.
- Краковецький О. Очищаємо веб-сторінки від інформаційного шуму [електронний ресурс]. Режим доступу – http://msug.vn.ua/...
- Soumen Chakrabarti. Integrating the Document Object Model with Hyperlinks for Enhanced Topic Distillation and Information Extraction // In Proceedings of WWW10, May 1-5, 2001, Hong Kong [електронний ресурс]. Режим доступу – http://www10.org/...
- Suhit Gupta, Gail E Kaiser, Peter Grimm, Michael Chiang, Justin Starren, Automating Content Extraction of HTML Documents // World Wide Web Journal, January 2005
- Краковецький О. Одержання основного контенту веб-сторінок програмно [електронний ресурс]. Режим доступу – http://habrahabr.ru...
- Методи й засобу витягу слабоструктурированных схем з документів в HTML і конвертування HTML документів у них XML вистава [електронний ресурс]. Режим доступу – http://www.raai.org/resurs/...