
Реферат по теме выпускной работы
Содержание
1. Введение.
2. Актуальность и мотивация темы работы.
3. Цели и задачи, которые должны решаться.
4. Предполагаемая научная новизна.
5. Планируемые практические результаты.
6. Обзор исследований и разработок по теме.
8. Разработка алгоритма очистки от информационного шума.
9. Заключение, перечень основных результатов и перспектив исследования.
10. Литература.
Введение
Наступивший XXI век станет этапным для проникновения новых информационных технологий и создаваемых на их основе высокопроизводительных компьютерных систем во все сферы человеческой деятельности – управление, производство, науку, образование и т.д.
Высокая доступность огромного количества постоянно пополняющейся информации, а также растущая популярность веб-услуг среди всех категорий пользователей обострили проблему выделения значимой для пользователя части информации [9].
Особенностью представления документов в сети Интернет является наличие на странице, помимо самого текста (содержательной части web-документа) [8] определяющего предмет страницы, большого количества вспомогательных элементов, таких как навигационные ссылки, версия для печати, «дорожные знаки» (ссылки, показывающие путь от главной страницы сайта к текущей), блоки текста с рекламой других разделов сайта, контактные данные компании и т.п. (так называемая служебная информация), призванных обеспечить навигацию по страницам сайта. Часто эти элементы не имеют прямого отношения к теме страницы и поэтому могут отрицательно влиять на качество восприятия информации пользователем.
Такое многообразие данных скрывает в себе проблемы, которые могут возникнуть при анализе необходимой информации в Интернет:
- Проблема перегруженности веб-страниц различной не важной для пользователя информацией: спамом, рекламой, всевозможными ссылками. Зачастую при визуальной фильтрации контента и оценке его значимости пользователь теряет массу времени.
- Отсутствие персонализации веб-пространства – задача по созданию средств, адаптирующих свои возможности (навигация, контент, баннеры и другие рекламные предложения) под пользователя на основании собранной и проанализированной информации о пользовательских предпочтениях [6].
Актуальность и мотивация темы работы
Зачастую при визуальной фильтрации контента и оценке его значимости пользователь теряет массу времени. Для решения этой проблемы необходимо применять очистку веб-страниц от информационного шума. Обозначим несколько областей, для которых можно будет применить задачу очистки веб-страниц:
- сервисы доставки контента, когда другие способы по каким-то причинам не подходят (например, RSS лента отсутствует) [11];
- системы по сбору некоторой информации из различных источников
- в мобильных приложениях, где важно минимизировать траффик
- системах data mining (data mining – это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности)
Задача очистки веб-страниц от информационного шума весьма актуальна в наше время и решение данной проблемы поможет преподносить искомую пользователем информацию в удобном для него виде, а так же положительно скажется на результатах web-поиска, классификации информации, извлечение текстовой информации и т.п.
Цели и задачи, которые должны решаться
Цель работы – создание общедоступных инструментальных средств, позволяющих очистить web страницы от информационного шума.
Для достижения поставленной цели необходимо решить основные задачи:
- Провести сравнительный анализ методов выделения основного контента web-страницы
- Разработать классификационную схему информационных блоков сайта
- Разработать адаптационный алгоритм оценки информационных блоков страниц
- Разработать инструментальные средства позволяющие обрабатывать определенные информационные блоки
- Провести тестирование эффективности разработанных инструментальных средств
Предполагаемая научная новизна
- Предложена новая классификационная схема информационных блоков сайтов, с набором значений параметров, которая учитывает структуру и специфику сайта
- Разработана модель очистки веб-станиц от информационного шума на основе классификационной схемы блоков
Планируемые практические результаты
Планируемая практическая значимость работы заключается в разработке инструментальных средств очистки web-страниц от информационного шума.
Применение разработанных средств позволит пользователю легко и быстро получить основной контент web-страницы не отвлекаясь на информацию не несущую смысловую нагрузку.
Разработанные инструментальные средства позволят выполнять следующие задачи:
- Скрытие банеров, рекламных блоков, мультимедийного контента, не несущего смысловую нагрузку и отвлекающего внимание пользователя
- Адаптация представления информации на сайте под запросы пользователя
Обзор исследований и разработок по теме
Применяемые методы анализа структуры web-страниц можно разделить на:
- Методы, основанные на выделении повторяющихся для всех (или части) страниц сайта фрагментов информации [1]
- Методы, основанные на анализе dom-деревьев страниц сайта [3]
- Комбинированные методы [2]
- Методы синтаксического и визуального анализа [5]
- Методы анализа страниц построенных на HTML 5 [4]
Анализ существующих методов выделения основного веб-контента показал, что методы, основанные на анализе DOM дерева эффективны и просты, а также предоставляют возможность проводить обработку единичной веб-станицы.
Существуют инструментальные средства, которые частично решают задачу выделения основного веб-контента:
NoScript– это дополнение для Firefox , которое позволяет защитить браузер от любых скриптов, которые, как известно, всегда потенциально опасны.
AdBlock Plus– является самым популярным расширением браузера Firefox, позволяющее блокировать загрузку и показ различных элементов страницы
Flash Block– Его назначение заключается в блокировки Flash-контента. Последний часто представляет собой банеры
Safari Reader– функция браузера Safari, позволяет в более удобном формате читать статьи и блоги, убирая весь мусор, который может отвлекать внимание
Readability– букмарклет (маленькая Javascript-программа, оформленная как URL и сохраняемая как закладка браузера) которая избавляет веб-страницу от рекламного мусора
Все эти средства, в основном направлены на борьбу с рекламой. Проведенный обзор существующих инструментальных средств очистки веб-страниц от информационного шума позволил выделить основные трудности, с которыми сталкиваются пользователи:
- Блокирование полезного для пользователя контента
Зачастую системы выделения основного контента вместе с навигацией и банерами блокируют и полезную информацию для пользователя (например, ссылки на сопутствующие статьи и прочее), причем пользователю данная информация станет доступной лишь при отмене обработки веб-страницы.
- Не универсальность
Множество существующих средств разработаны под конкретный браузер, что приводит к сужению категории пользователей.
- Отсутствие адаптации под конкретного пользователя
Обзор показал, что при работе выделения основного контента веб-страницы инструментальные средства основываются на общем восприятии понятия «полезная информация» – блок текстовой информации, что не всегда соответствует запросам пользователя.
- Недостаточная эффективность
Исходя из всего вышесказанного, можно сделать вывод, что разработка инструментальных средств очистки веб-страниц от информационного шума ведется довольно активно, но пока не существует универсальных средств, которые бы могли удовлетворить все запросы пользователей.
Математическая постановка
Очищенная страница от информационного шума представляется в виде:
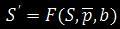
Где 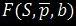 – функция очистки,
– функция очистки,
S – исходный сайт,
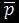 – параметры обработки, задающиеся пользователями. Данный параметр задается в случае когда при обработке произошло отсечение важной информации для пользователя. Пользователи отмечают блок контента который необходимо отобразить, при этом устанавливается значение для .
– параметры обработки, задающиеся пользователями. Данный параметр задается в случае когда при обработке произошло отсечение важной информации для пользователя. Пользователи отмечают блок контента который необходимо отобразить, при этом устанавливается значение для .
b – параметр блока контента, который определяется по следующей формуле:

Где g – функция определения свойств содержимого сайта
Значения параметра блока контента и определение свойств его содержимого сведем в Табл. 5.1
Таблица 1 – Признаки типов информационных блоков контента
| № | Признаки блока | Значимость блока |
0 |
наличие большого количества изображений
|
Информационный шум |
1 |
наличие большого количества гиперссылок |
Маловажная информация |
2 |
наличие графического, мультимедийного, видео контента |
Важная информация |
Анализ вопроса очистки web-страниц от информационного шума дал возможность определить несколько типов сайтов исходя из соответствующих им характерным признакам и их значения. Типы сайтов и признаки характерные для них были сведены в табл.2
Таблица 2 – Признаки типов сайтов
| Типы сайтов | Характерные признаки |
Для этих сайтов характерно высокое количество информативных изображений, т.е изображений которые будут полезны для пользователя и могут считаться полезным контентом. |
|
|
Для данных сайтов характерно высокое количество ссылок, которые могут считаться полезным контентом |
Разработка алгоритма очистки от информационного шума
Приняв во внимание все сильные и слабые стороны существующих инструментальных средств, остановим свой выбор на идеи создания букмарклета.
Букмарклет(bookmarklet) – это javascript-код, который сохраняется как закладка в браузере. Он работает за счет использования протокола < a href="javascript:..."> [10].
Алгоритм очистки web-страниц от информационного шума состоит из следующих этапов:
- Букмарклет получает адрес страницы для ее обработки.
- Для заданной страницы определяется структура DOM дерева из HTML-кода.
- Происходит проход по DOM дереву и классификация тегов(узлов) по соответствующим признакам.
- Далее определяются значимые узлы.
- Система обрабатывает информационные блоки, выделяет блок основного контента, отсекая теги, помеченные как информационный шум (медиа, навигация, ссылки и прочее).
- Обработанная страница отображается для пользователя.
- В случае, если произошло отсечение важной информации, пользователь отменяет обработку. Страница отображается ему в первичном виде с рамками вокруг различных блоков контента. Отметив нужный блок, пользователь сохраняет результат. Страница вновь проходит обработку, в ходе которой отмеченные пользователем блоки отсекаться не будут. Обработанная страница отображается для пользователя вместе с сообщением, в котором будет предложено сохранить результаты обработки страницы в системе.
- Адрес обрабатываемой страницы и результаты ее обработки сохраняются.

Рис. 1 – Блок-схема алгоритма работы букмарклета
Заключение, перечень основных результатов и перспектив исследования
Очищение web-страниц от информационного шума является одним из перспективных направлений развития отрасли информационно – коммуникационных технологий.
Свидетельством актуальности выделения основного контента страницы по запросам пользователей является постоянное совершенствование программного инструментария для формирования и отображения web-страниц. В условиях насыщения рынка технологических услуг все большее внимание привлекают методы и средства персонализации потоков контента.
Литература:
- Агеев М.С., Добров Б.В., Лукашевич Н.В., Сидоров А.В. Экспериментальные алгоритмы поиска/классификации и сравнение с «basic line». // Российский семинар по Оценке Методов Информационного Поиска (РОМИП 2004) [электронный ресурс]. Режим доступа – http://romip.narod.ru/...
- И. Некрестьянов, Е. Павлова. Обнаружение структурного подобия HTML-документов. СПГУ, 2002 [электронный ресурс]. Режим доступа – http://meta.math.spbu.ru
- М.С. Агеев, И.В. Вершинников, Б.В. Добров. Извлечение значимой информации из web-страниц для задач информационного поиска. Интернет-математика 2005. Сборник работ по программам научных стипендий Яндекса. Москва, 2005.
- Р.Ф. Кузнецов, Н.В. Мурашов. Оценка влияния извлечения значимой информации на качество классификации web-страниц
- Определение понятия «информационный шум» [электронный ресурс]. Режим доступа – http://mediart.ru/...
- Yi, L., Liu, B., Web Page Cleaning for Web Mining through Feature Weighting, in the proceedings of Eighteenth International Joint Conference on Artificial Intelligence (IJCAI-03), Acapulco, Mexico, August, 2003.
- Краковецкий А. Очищаем веб-страницы от информационного шума [электронный ресурс]. Режим доступа – http://msug.vn.ua/...
- Soumen Chakrabarti. Integrating the Document Object Model with Hyperlinks for Enhanced Topic Distillation and Information Extraction // In Proceedings of WWW10, May 1-5, 2001, Hong Kong. [электронный ресурс]. Режим доступа – http://www10.org/...
- Suhit Gupta, Gail E Kaiser, Peter Grimm, Michael Chiang, Justin Starren, Automating Content Extraction of HTML Documents // World Wide Web Journal, January 2005
- Краковецкий А. Получение основного контента веб-страниц программно [электронный ресурс]. Режим доступа – http://habrahabr.ru/...
- Методы и средства извлечения слабоструктурированных схем из документов в HTML и конвертирования HTML документов в их XML представление [электронный ресурс]. Режим доступа – http://www.raai.org/resurs/...