
Выявления схожего видеоматериала, используя методы распознавания образов
Источник: Сборник материалов II всеукраинской научно-технической конференции студентов, аспирантов и молодых ученых «Комп'ютерний моніторінг та інформаційні технології (ИУС и КМ 11-13 апрель - 2011)». III том. Донецк, ДонНТУ - 2011. с. 150-155.
Аннотация:
Выявления схожего видеоматериала, используя методы распознавания образов. Рассмотрены существующие способы нахождения дубликатов файлов. Детально описан кардинально новый алгоритм поиска видеоматериала с одинаковым содержанием, но с различными техническими характеристиками, основанный на использовании методов распознавания образов.
Введение
Социальные сети в настоящее время стали основным средством общения, поддержки и развития социальных контактов, поиска, хранения, редактирования и классификации информации, творческой деятельности и выполнения множества других задач. Не смотря на разнообразие взглядов и предпочтений людей, в сети возникает повторение опубликованного материала. Это связано в первую очередь с таксономическим и фолксономическим подходами классификации данных.
Недостаток таксономического подхода в том, что объект в таком можно привязать только к одному узлу, то есть становится невозможным при помощи такой структуры описать все необходимые качества этого объекта. В связи с этим очевидно копирование этого же объекта в другой узел с описанием других качеств.
Фолксономический подход лишен этого недостатка - можно привязать объект к любым узлам. Однако, в последнем подходе отсутствует всяческая структура, т.е. нет элементарных отношений (род-вид) между узлами. Таким образом, нельзя выявить объекты, носящие более общий или более частный характер. Это также является значительным недостатком для сервисов видеохостинга с огромными объемами информации, что снижает эффективность поиска и приводит к созданию копий файлов.
Следует отметить, что количество копий видеоматериалов, размещенных на одном видеосервисе или социальной сети, напрямую зависит от популярности видеоролика и тенденций моды. Из личных исследований было выявлено, что «популярный» видеоматериал размещен на одном видеосервисе от 5 до 20 раз, и лишь 1-2 видеоролика из них отличаются качеством видеоизображения, при объемах видеоматериалов крупных сетевых сервисов это значительный объем дискового пространства, измеряемый в терабайтах. Также увеличивает объем хранимых данных использование технологии RAID 10 на серверах, и CDN-сети доставки контента.
Общая постановка проблемы
Сравнение видеоматериалов проще всего производить на основании сравнения кадров, взятых из этих видеоматериалов.
В таком случае постановка проблемы будет выглядеть следующим образом:
имеется последовательность из кадров, полученных и преобразованных определенным образом из видеоматериалов через промежутки времени соответствующие ключевым кадрам видеоматериала. Необходимо на основании сравнения таких последовательностей, взятых из различных видеоматериалов, принять решение о похожести видеоматериалов.
Существующий способ решения проблемы
Существующие методы, из-за огромного количества загружаемых видеоматериалов, не в полной мере удовлетворяют условиям рациональной стратегии использования дискового пространства. В общем случае в большинстве видеосервисов, решение задачи поиска идентичных видеофайлов сводится к двум методам. Методу сравнения хеш-кода или контрольной суммы и методу сравнения сравнение свойств файлов.
Первый метода основан на преобразовании входного массива данных в короткое число фиксированной длины (которое называется хешем или хеш-кодом) таким образом, чтобы с одной стороны, это число было значительно короче исходных данных, а с другой стороны, с большой вероятностью однозначно им соответствовало. Преобразование выполняется при помощи хеш-функции. Ясно, что в общем случае однозначного соответствия между исходными данными и хеш-кодом быть не может. Обязательно будут возможны массивы данных, дающих одинаковые хеш-коды, но вероятность таких совпадений в каждой конкретной задаче должна быть сведена к минимуму выбором хеш-функции. В задачи сравнения файлов применяют алгоритмы хеширования MD-5, SHA-1, CRC. Алгоритм работы метода основанного на использовании хеш-кода заключается в следующем:
· Рассчитываются хеш-суммы для всех видеофайлов и заносятся в специальную таблицу в базе данных.
· С некоторой периодичностью запускается скрипт-программа сравнивающая хеш-суммы между собой.
Если в результате работы скрипта найдены одинаковые хеш-суммы то один из совпавших файлов удаляется.
В методе поиска основанном на сравнении свойств файлов хеш-сумма не рассчитывается, и процесс работы заключается следующем:
· Выбирается файлы с одинаковым размером и длительностью видеоряда
· При помощи регулярных выражений отсекаются лишние знаки и сравниваются названия.
· Так же возможны критерии сравнения по дате создания файла, при условии, что видеосервис хранить не преобразованные копии файлов.
· Если все результата сравнения положительны один удаляется
Эти методы имеют характерный недостаток. Ни один из них не позволяет анализировать видеоряд данных и неспособен определить равные по содержимому, но разные по размеру, кодеку сжатия, разрешению файлы. Типичная ситуация, приводящая к дублированию видеоматериалов – наличие двух разных файлов у двух разных пользователей, сжатых различными кодеками и имеющими разный размер (см. рис. 2.).

Рисунок 1 Типичная ситуация приводящая к дублированию видеоматериалов
Исходя из всего вышеперечисленного для решения задачи поиска и удаления дублирующегося видеоматериала, необходим новый метод сравнения и выявления данных. Этот метод должен распознавать видеоряд, а не сравнивать атрибуты или хеш-суммы. Одним из возможных способов реализации такого метода является подсистема основанная на теории распознавания образов.
Метод поиска основанный на системе распознавания образов
Системы распознавания - это отнесение исходных данных к определенному классу с помощью выделения существенных признаков, характеризующих эти данные, из общей массы несущественных данных. Структурная схема системы распознавания представлена на рисунке 3.
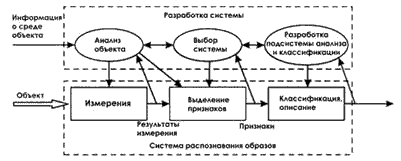
Рисунок 2. Структурная схема системы распознавания
Наиболее часто в задачах распознавания образов рассматриваются монохромные изображения, что дает возможность рассматривать изображение как функцию на плоскости. Если рассмотреть точечное множество на плоскости T, где функция f(x,y) выражает в каждой точке изображения его характеристику — яркость, прозрачность, оптическую плотность, то такая функция есть формальная запись изображения.
Множество же всех возможных функций f(x,y) на плоскости T — есть модель множества всех изображений X. Вводя понятие сходства между образами можно поставить задачу распознавания. Конкретный вид такой постановки сильно зависит от последующих этапов при распознавании в соответствии с тем или иным подходом. Распознавание образов можно осуществить, используя три различных подхода.
· Подход оптического распознавания образов. В данном случае применяется методы перебора вида объекта под различными углами, масштабами, смещениями, для букв нужно перебирать шрифт, свойства шрифта, жирность наклон и т д.
· Второй подход - найти контур объекта и исследовать его свойства (связность, наличие углов и т. д.)
· Третий - использовать искусственные нейронные сети. Этот метод требует либо большого количества примеров задачи распознавания (с правильными ответами), либо специальной структуры нейронной сети, учитывающей специфику данной задачи
Для решения данной проблемы предлагается использование второго подхода, в связи со следующими причинами:
- заранее неизвестно количество видеофайлов
- количество видеофайлов на устройствах хранения постоянно растет, а значит при использовании нейронных сетей сеть постоянно не обходимо будет переучивать, что приводит к нецелесобразному использованию мощностей сервера.
- Использование подхода исследования свойств изображения или частей изображения с сохранением результатов в базе данных исключает, необходимость перерасчета показателей для разных видео файлов при добавлении данных на устройства хранения.
Данный метод оптимизации можно разложить на несколько подзадач (Рис. 4):
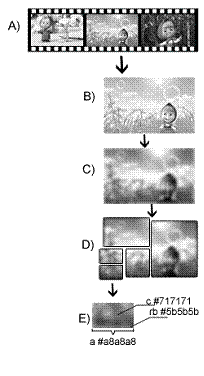 Рисунок 4. Алгоритм работы метода
Рисунок 4. Алгоритм работы метода
1.Детектирование сцен видеофильма. Сохранение информации в БД. (рис. 4 A).
2. Сделать захват кадра в конце сцены. (рис.4.B)
3. Изменения разрешения и размера кадра к единому. (рис.4.B)
4. Перевод изображений в градации серого. (рис.4. C)
5. Нормализация и сглаживание изображения. (рис.4.C)
6. Разделение полученного изображения на участки по 5х6. (рис.4.D)
7. Измерение параметров участков и передача данных. (рис.4. E)
8. Поиск существующих дубликатов файлов
Для захвата кадров может использоваться утилита ffmpeg. Длительность сцен фиксируется в базе данных.
Для проведения манипуляция с захваченными изображениями могут использоваться следующие утилиты: CImg Library, ImageMagick.
Измерение параметров сводиться к расчету средней градации участка, максимальной, минимальной и градациям в углах и по центру. Все полученные данные фиксируются в базе.
Поиск дубликатов заключается в следующем:
1. Выбор файлов с некоторой совпадающей последовательностью
2. Сравнение данных в совпавших сценах, удаления дубликатов.
Выводы
Высокая степень дублирования видеоматериалов, располагающихся на серверах, приводит к их излишней загруженности. Т.о., задача определения и удаления схожих видеоматериалов является актуальной.
Сделано предположение, что сравнение видеоматериалов на похожесть наиболее логично производить на основании сравнения кадров, взятых из этих видеоматериалов преобразованных особым образом таким как: переводом к градациям серого, нормализации и фильтрации изображения, для того чтобы увеличить точность распознавания.
Выделены группы методов, способных решать данную задачу. Предлагается использовать метод, использующий теорию распознавания образов, основанный на исследовании свойств разделенного на части изображения.
Предложенный алгоритм решения задачи позволит, значительно сократить объемы дискового пространства, тем самым позволив уменьшить затраты компаний предоставляющих услуги видеохостинга, что повысит эффективность их работы.
Литература
1. Распознавание образов - применение на практике
2. Д. Рутковская. Нейронные сети, генетические алгоритмы и нечеткие системы
3. Сайт о распознавании образов