Источник: http://www.chipnews.ru/html.cgi/arhiv_i/99_02/stat-33.htm
При проектировании особенно важно понимать взаимодействие между стилем HDL кодирования, различными архитектурами устройств FPGA и программным обеспечением для автоматизированного проектирования.
Если бы мы жили в идеальном мире, существующие инструменты синтеза логических схем могли бы толковать и эксплуатировать различные архитектуры программируемых пользователем вентильных матриц (FPGA) и их специальные функции без вмешательства разработчика. В реальном мире всё не так легко. Приложения, от которых требуется высокая производительность и плотность размещения логики, являются очень критичными к используемому разработчиком стилю кодирования. Для получения оптимальных результатов необходимо понимание архитектуры матриц FPGA, принципов работы инструментов синтеза схем и программного обеспечения конечной трассировки.
Большинство устройств FPGA состоят не из множества малых элементарных ячеек, а из набора программируемых функциональных блоков (Programmable Functional Units, PFU), реализующих комбинационную логику на основе поисковых таблиц (LUT), и некоторого количества триггеров или регистров. Ниже приводится список некоторых особенностей матриц FPGA, без учёта которых могут возникнуть трудности при использовании стандартных инструментов синтеза: триггеры внутри блоков PFU совместно используют некоторые сигналы управления, например, сигналы синхронизации, разрешения синхронизации и сброса/установки. В архитектуре ORCA, например, возможно реализовать четыре триггера в одном функциональном блоке PFU при условии, что они имеют одинаковые вышеупомянутые сигналы. Большинство инструментов синтеза этого не понимает. Если проект был закодирован без учёта этого факта, то набор триггеров использовался бы неэффективно, что привело бы к значительному увеличению размера кристалла микросхемы; запоминающие элементы внутри матрицы FPGA могут быть реализованы на блоках PFU в её LUT части. Такой метод создания модулей ОЗУ или ПЗУ внутри FPGA позволяет сэкономить большое количество логических элементов и значительно улучшает быстродействие устройства. К сожалению, в HDL не имеется никакого способа реализовать модули памяти. Следовательно, инструменты синтеза не могут обнаружить их присутствие, чтобы затем использовать функцию табличного поиска матриц FPGA; реализация счётчиков и конечных автоматов также затруднена. Так как имеется большое количество различных видов этих схем, использование какой-либо определённой из них целиком определяется приложением. Выбор наиболее эффективного метода в значительной степени определяется знанием архитектуры устройства FPGA; иерархия проекта и разработка общей топологии кристалла для инструментов синтеза — задача также достаточно сложная; сигнал глобального сброса (Global Set Reset, GSR) представляет собой внутренне маршрутизируемый сигнал, который не потребляет никаких ресурсов маршрутизации микросхемы. В настоящее время реализовать эту функцию в языке VHDL принципиально невозможно. Следовательно, инструменты синтеза не могут использовать эту функцию, так как GSR компонент никак не описывается в коде HDL.
Имеются три основных метода написания VHDL кода. Ниже они представлены в порядке возрастания эффективности: Общий код, который не привязан к архитектуре. Общий код, привязанный к архитектуре используемого устройства. HDL код с макроконкретизацией.
В данной статье мы сравним эти три метода, включая стили кодирования, с целью повысить эффективность синтеза.
Синхронная логика
Триггеры и защёлки в большинстве устройств FPGA на основе поисковых таблиц могут быть сконфигурированы в синхронном режиме сброса/установки с использованием назначаемого разработ-чиком локального сигнала сброса (Local Set Reset, LSR). Для правильной реализации защёлки или триггера, инструмент синтеза должен найти в библиотеке соответствующий макрос. Этого не произойдет, если HDL код не будет содержать правильное описание элемента, а поэтому требование общего понимания архитектуры устройств FPGA надо считать обязательным.
Разработчики должны иметь представление о видах триггеров и защёлок, которые являются доступными в библиотеке макросов данного поставщика. Если код реализует функции регистра, который не представлен соответствующим макросом в библиотеке, его дополнительные функциональные возможности будут добавлены к схеме с использованием дополнительной логики. В большинстве случаев, наличие дополнительной логики отрицательно отражается на канале данных регистров, увеличивая задержки и необходимую площадь кристалла.
В каждом программируемом функциональном блоке (PFU) может быть реализовано несколько защёлок и/или триггеров, которые совместно используют некоторые из его входов. Чтобы получить максимальную эффективность использования площади кристалла, защёлки и триггеры должны быть сгруппированы по несколько штук, чтобы оптимально использовать объём блоков PFU.
Если требуется синхронная работа триггера, то глобальный сигнал сброса (GSR) здесь не подойдет, так как он обеспечивает только асинхронный режим работы. Несмотря на это, он может быть использован совместно с сигналом локального сброса (LSR).
Если код подразумевает использование стробированного сигнала разрешения синхронизации (Clock Enable, CE), инструмент синтеза имеет тенденцию дублировать разрешающую логику для каждого регистра проекта. Чтобы избежать этого, рекомендуется держать стробированные сигналы в отдельной процедуре, а затем подавать их на CE вход главного модуля.
Чтобы реализовать правильный триггер, код HDL должен корректно описать его функционирование. Например, приведенный ниже листинг кода используется, чтобы реализовать двухбитовый регистр с уровнем синхронного сброса +VE, и уровнем +VE сигнала разрешения:
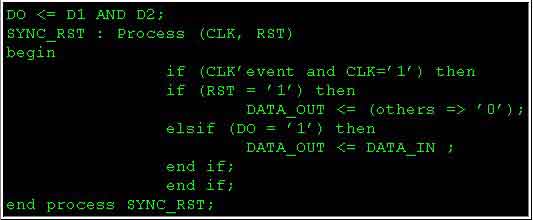
Обратите внимание, что здесь, чтобы корректно осуществить син-хронный сброс, оператор “if (RST = ’1’) then” должен быть введён внутри процедуры после оператора с CLK’event. А для того, чтобы связать “DO” с входом CE триггера, оператор “elsif (DO = ’1’) then” должен стоять после “if (RST = ’1’) then”.
При использовании такого подхода надо быть очень бдительным, так как некоторые инструменты синтеза имеют ограничения в осуществлении режима синхронного сброса/установки. В итоге могут быть получены некоторые непредсказуемые результаты, которые, хотя они и будут правильны функционально, пагубно отразятся на быстродействии и объёме конечных схем. Сигнал DO связан с входом CE триггера только в случае, если HDL код реализован, как показано в предыдущем примере. К тому же, некоторые сигналы не предполагалось подавать на CE порт. Но известно, что они будут присутствовать, если разработчик не знает точно, какой алгоритм закончится CE связью. Рассмотрим:
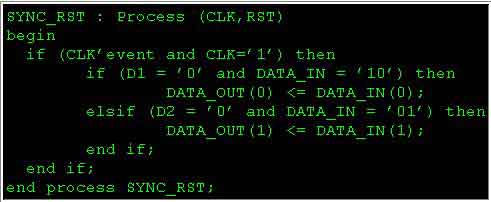
Приведённый в этом листинге код произведет два триггера с двумя различными сигналами CE по двум причинам. Во-первых, в процедуре имеется несколько неопределённых состояний (например, состояние, когда D1 = ’1’ и DATA_IN = ’10’). Во-вторых, не все возможные выходы для определённых состояний были определены в каждом операторе “if”.
Обе эти причины вынудят инструмент синтеза использовать порт CE триггера, чтобы сохранить их предыдущие состояния. В результате, эта схема потребует две программируемых логических ячейки (PLC) вместо одной. Чтобы избежать таких моментов, снижающих эффективность проектирования, при написании HDL кода пользуйтесь следующими правилами: всегда старайтесь группировать по четыре триггера под каждым оператором “if”; старайтесь определить все возможные состояния сигналов управления и статус выходов регистра для каждого из этих состояний.

В этом листинге приведен пример кода, который не будет пытаться использовать CE входы триггера.
Модули памяти
Наиболее эффективным способом организовать статическое ОЗУ (SRAM) внутри матриц FPGA является способ использования внутренних поисковых таблиц внутри функциональных блоков PFU. В устройствах FPGA производства компании Lucent, например, на одном блоке PFU может быть реализовано две матрицы ОЗУ или ПЗУ: один блок памяти 16х4 или два блока 16х2. Применение нескольких блоков PFU позволяет организовать матрицы больших размеров (например, 16х8, 32х4 и 64х8). Ниже мы обсудим три метода реализации блока памяти 16х8.
Первый метод представляет собой написание типового VHDL кода (листинг 1). Когда VHDL код, приведённый в этом листинге, реализуется на устройствах 2C04, проект задействует 128 триггеров, 76 из 100 блоков PFU и 0 из 800 буферов с тремя состояниями (TBUF). После компоновки и трассировки такой схемы была произведена оценка её быстродействия. Максимальная рабочая частота для нее составила 38 МГц.

Второй метод представляет собой написание типового VHDL кода, привязанного к архитектуре FPGA (листинг 2). При реализации этого VHDL кода на устройствах 2C04 проект задействует 128 триггеров, 41 из 100 блоков PFU и 128 из 800 буферов TBUF. Максимальная частота для этой схемы после компоновки и трассировки составляет 40 МГц.
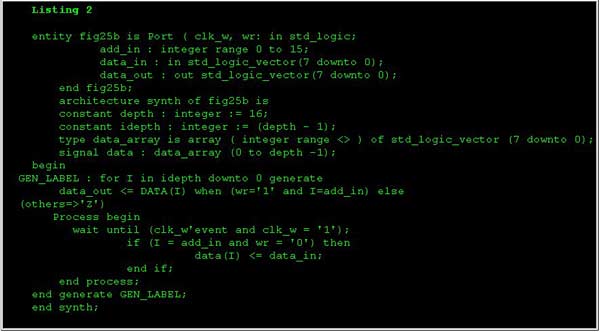
Третьим и заключительным методом является конкретизация ОЗУ (листинг 3). Когда представленный в листинге VHDL код реализуется на устройствах 2C04, проект задействует 20 триггеров, 6 из 100 блоков PFU, и 8 из 800 буферов TBUF. Максимальная рабочая частота такой схемы составляет 52 МГц.
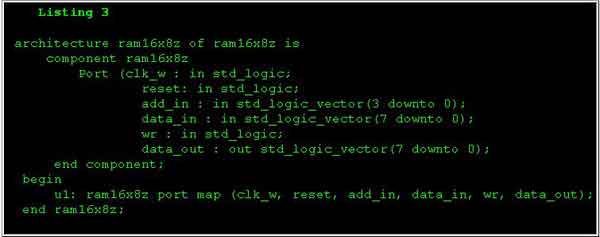
Преимуществом первого метода является то, что применяемый здесь типовой VHDL код может быть реализован на любой технологии. Кроме того, здесь не требуется никакого представления об архитектуре FPGA. Однако, у этого метода имеются явные недостатки: здесь абсолютно не используются архитектурные функции матрицы FPGA, поэтому схема получается очень насыщенной и низкопроизводительной.
Второй метод имеет несколько преимуществ. Во-первых, представленный здесь типовой VHDL код реализуется на любой технологии, но, по сравнению с первым методом, синтезированная схема получается вдвое меньшей. Во-вторых, полученная задержка между сигналом син-хронизации и выходным сигналом здесь вдвое меньше.
Но всё же, этот метод имеет и слабые места. Первое неудобство — использование буферов с тремя состояниями матрицы FPGA, что может значительно затруднить маршрутизацию при разработке больших проектов. Кроме того, этот метод, как и первый, не задействует архитектурные функции матрицы FPGA.
Последний метод имеет два основных преимущества. Быстродействие синтезированной схемы почти на 25% выше, чем в первых двух случаях, а число используемых блоков PFU сокращено на 35 штук по сравнению со вторым методом. К сожалению, используемый здесь VHDL код привязан к определённой технологии.
Счётчики и конечные автоматы
Имеется большое количество различных типов счётчиков и конечных автоматов, которые могут быть реализованы с помощью языка VHDL. Каждый из них ориентирован на определённое приложение и имеет свои преимущества и недостатки.
Схемы двоичных счётчиков являются самыми легкими для описания на языке HDL. Они также очень хорошо реализуются на некоторых современных FPGA с помощью поисковых таблиц. В архитектуре ORCA, например, режим сквозной страничной выборки каждой LUT таблицы может быть сконфигурирован таким образом, что каждый блок PFU сможет выполнять арифметические функции с разрядностью до 4 бит. Кроме того, большинство общих инструментов синтеза понимают эту функцию устройств FPGA и могут получать преимущества от неё даже при использовании типового HDL кода. Приведённый ниже код показывает простую HDL реализацию синхронного суммирующего 8-разрядного счётчика с линией разрешения.

Реализованный на устройствах 2C04, счётчик использует 8 триггеров и 2 из 100 блоков PFU. Максимальная рабочая частота для данной схемы после компоновки и трассировки составила 91,542 МГц.
Преимущества счётчика очевидны. Его очень просто реализовать на большинстве матриц FPGA с помощью поисковых таблиц. Однако, имеется одно главное неудобство: если выходные сигналы счётчика должны быть декодированы для приложений, подобных контроллеру конечных автоматов или типовому модулю памяти, дешифрующаяся логическая схема будет содержать большое количество дополнительных логических элементов к общей схеме, а это наверняка отрицательно скажется на производительности.
Если производительность является основным параметром, по которому оптимизируется схема, то применение одного горячего ключа или счётчиков на сдвиговых регистрах оказывается более пригодным, чем предыдущее решение. Однако, этот метод имеет серьезный недостаток: схема потребляет большое количество логических элементов. Ниже на листинге показан HDL код, описывающий 4-разрядный счётчик, реализованный по конфигурации с одним горячим ключом.

Конечная схема, реализованная на устройствах 2C04, использует 5 триггеров и 2 из 100 блоков PFU. После компоновки и трассировки максимальная рабочая частота для этой схемы составила 109 МГц.
Схема на основе одного горячего ключа или счётчика на сдвиговом регистре работает намного быстрее простых двоичных счётчиков, особенно когда далее она объединяется с каким-либо конечным автоматом. Это происходит потому, что дешифрация выхода счётчика производится только по единственному биту. Кроме того, такая схема легко описывается в VHDL. Легко заметить, что в последнем листинге имеется только одна строка кода, где используются операции конкатенации (and).
С другой стороны, реализация схемы требует большого количества триггеров. Предположим, что надо синтезировать N-разрядный счётчик. При использовании указанного метода для реализации всех возможных состояний счётчика потребуется [(2N)+1] регистров. Эта форма счётчиков или конечных автоматов совсем не использует преимущества архитектурных функций FPGA, которые допускают непосредственное выполнение арифметических функций.
Пример
Давайте рассмотрим пример реализации блока памяти FIFO (First-In-First-Out) размером 127ґ4. Блок будет выполнен двумя методами: с конкретизацией памяти и без неё.
Блок FIFO представляет собой однопортовое устройство, а это означает, что в один момент времени может производиться операция только записи или чтения массива. Для индикации статуса блока FIFO служат сигналы FULL_L и EMPTY_L. Низкий уровень сигналов WRL и RDL говорит об активности операции записи или чтения, соответственно.
Сначала попробуем типовое VHDL описание для блока FIFO размером 127ґ4. В этом случае весь блок FIFO размещается в одной процедуре и синтезируется как моноблок. Из-за ограниченного объёма данной статьи листинг кода для этой реализации не приводится. Будучи выполненным на устройстве FPGA типа 2C15, проект задействует 528 триггеров и 200 из 400 блоков PFU. По-сле компоновки и трассировки максимальная рабочая частота блока составляет 20 МГц.
Теперь давайте рассмотрим конкретизированный подход к написанию VHDL кода. Тот же самый код, который использовался для предыдущего метода, теперь разделён на два блока. Первый блок представляет собой отдельную процедуру со следующими функциями:
Вычисление текущих адресов записи и чтения как функций сигналов FULL_L, EMPTY_L, WRL и RDL.
Вычисление параметра DIFF_PTR, который увеличивается на 1 при операции записи и уменьшается при операции чтения. Параметр используется для формирования сигналов FULL_L и EMPTY_L блока FIFO.
Этот первый блок включает в себя все, кроме объекта RAM_ARRAY. Процедура, реализующая этот блок, приведена в листинге 4.

Второй блок создан с конкретизацией VHDL кода. В этом объекте имеется конкретизация для восьми макросов RPP16-by-4z из библиотеки устройств FPGA типа ORCA. Эти макросы были переработаны, чтобы реализовать блок памяти FIFO размером 127x4 (RAM_ARRAY).
Реализованный на устройствах 2C15, проект использует 20 триггеров и 25 из 400 блоков PFU. После компоновки и трассировки максимальная рабочая частота схемы составляет 29 МГц.
Заключение
Для устройств, где особых требований к быстродействию и объему схемы не предъявляется, скорее всего, достаточно написать типовой синтезируемый HDL код. Однако для систем, где эти характеристики являются критическими, необходимы элементарные знания архитектур FPGA и корректного стиля HDL кодирования для данной архитектуры.
В настоящее время для синтеза логических схем разработчики программного обеспечения совместно с производителями микросхем FPGA работают над совершенствованием своих продуктов и надеются, что в ближайшем будущем их инструменты будут автоматически эксплуатировать архитектурные функции всего устройства. Но сейчас при HDL кодировании от разработчиков требуется моби-лизация всего их опыта разработки цифрового оборудования, так как это единственный способ получить максимальную отдачу от использования программируемых логических матриц.
