
Реферат за темою випускної роботи
Зміст
- Введення
- 1. Актуальність теми
- 2. Мета і задачі магістерської роботи
- 3. Опис методу PIV
- 4. Огляд методів паралельних обчислень
- 4.1 Класифікація архітектур паралельних обчислювальних систем
- 4.2 Hardware‐рішення
- 4.3 Software‐рішення
- Висновки
- Список джерел
Введення
В наш час коло завдань, що вимагають для свого рішення застосування потужних обчислювальних ресурсів, постійно розширюється. Це пов'язано з тим, що відбулися фундаментальні зміни в самій організації наукових досліджень. Внаслідок широкого впровадження обчислювальної техніки, значно посилився напрям чисельного моделювання та чисельного експерименту. Чисельне моделювання, заповнюючи проміжок між фізичними експериментами і аналітичними підходами, дозволило вивчати явища, які є або надто складними для дослідження аналітичними методами, або занадто дорогими або небезпечними для експериментального вивчення. При цьому чисельний експеримент дозволив значно здешевити процес наукового і технологічного пошуку. Стало можливим моделювати в реальному часі процеси інтенсивних фізико-хімічних і ядерних реакцій, глобальні атмосферні процеси, процеси економічного та промислового розвитку регіонів і т.д. Очевидно, що рішення таких масштабних завдань вимагає значних обчислювальних ресурсів.
1. Актуальність теми
В даний час є кілька реалізацій методу швидкості Зображення Частинок (PIV) [1], однак, жодна з них не підтримує розподілених паралельних обчислень, що могло б в рази збільшити швидкодію. За рахунок збільшення продуктивності, стане можливим більш оперативне зміна параметрів досліджуваного об'єкта.
Цей метод отримав широке поширення в різних областях науки і техніки. Найбільш популярне застосування — це моделювання поведінки киплячого шару.
В даний час киплячий шар отримав застосування в широкому колі областей: харчова промисловість (розчинна кава, чай, мюслі т.д.), хімічна промисловість (полімери, полікарбонати, миючі речовини і т.д.), інші галузі промисловості (активоване вугілля, гіпс, піски та ін.) Особливо актуально застосування киплячого шару в області енергетики для більш ефективного спалювання палива та зменшення викидів в атмосферу.
2. Мета і задачі магістерської роботи
Мета магістерської роботи полягає в тому, щоб прискорити роботу методу PIV за допомогою засобів паралельного програмування.
Задачами роботи є дослідження існуючих систем, що реалізують метод PIV, аналіз способів розпаралелювання обчислювальних процесів, застосування одного із способів для прискорення роботи реалізації методу PIV. Також необхідно провести порівняльний аналіз швидкості роботи системи при різних конфігураціях системи, виявити оптимальні параметри роботи, а також провести дослідження можливостей прискорення обчислювальних процесів.
3. Опис методу PIV
Методи візуалізації для вивчення потоків були відомі задовго до появи електронних обчислювальних машин. Перші спостереження за перебігом рідини у водоймах за допомогою природних природних трассеров були описані ще Леонардо да Вінчі. Людвіг Прандтль (1875-1953) використовував суспензія з часток слюди на поверхні води для аналізу обтікання циліндрів, призм і профілів крила в експериментальному каналі.
Поступово від якісних спостережень відбувся перехід до вимірювання кількісних характеристик течій, і до 60-м років XX століття сформувалося широке напрямок в діагностиці, відоме як "стробоскопічний візуалізація". Принцип стробоскопічний трассерного візуалізації полягає у вимірюванні зсуву трассеров в заданому перерізі потоку рідини чи газу за відомий інтервал часу. Областю виміру служить площину, освітлювана світловим ножем (рис. 1) [2].
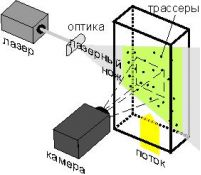
Рисунок 1 — стробоскопічний візуалізація
Результатом вимірювання є миттєве поле швидкості в вимірювальної площині. Однією з найбільш показових вітчизняних робіт того часу є стаття [3], в якій наведено результати вимірювання полів швидкості і турбулентних пульсацій в прикордонному шарі на пластині, отримані шляхом ручної обробки трассерних картин, зареєстрованих на фотографічній плівці. Однак ручна обробка була трудомістка, займала тривалий час і не дозволяла отримувати достатнього обсягу даних для розрахунку статистичних характеристик. Дана ситуація була типовою для усіх дослідних груп у світі, що займалися кількісної візуалізацією потоків.
Поява терміна PIV (Particle Image Velocimetry) — міжнародна назва методу цифрової трассерного візуалізації, пов'язують з роботою [4] в якій метод PIV був виділений як окремий випадок методу лазерної спеклометріі LSV (Лазерні спекл Velocimetry) [5] базується на оптичному перетворенні Фур'є яркостних картин.
Приклад обробки зображень методом PIV представлений на рисунку 2.

Рисунок 2 — Обробка зображень методом PIV (анімація: 7 кадрів, 5 циклів повторення, 163 кілобайт)
4. Огляд методів паралельних обчислень
4.1 Класифікація архітектур паралельних обчислювальних систем
Найбільш ранній і найбільш відомою є класифікація архітектур обчислювальних систем, запропонована в 1966 році М.Флінном. Класифікація базується на понятті потоку, під яким розуміється послідовність елементів, команд або даних, що обробляється процесором. На основі числа потоків команд і потоків даних Флінн виділяє чотири класу архітектур: SISD, MISD, SIMD, MIMD.
SISD (один потік інструкцій / єдиний потік даних) — одиночний потік команд і одиночний потік даних (рис 3.а). До цього класу належать класичні послідовні машини, або інакше, машини фон-неймановского типу, наприклад, PDP-11 або VAX 11/780. В таких машинах є тільки один потік команд, всі команди обробляються послідовно один за одним і кожна команда ініціює одну операцію з одним потоком даних. Не має значення той факт, що для збільшення швидкості обробки команд і швидкості виконання арифметичних операцій може застосовуватися конвеєрна обробка - як машина CDC 6600 зі скалярними функціональними пристроями, так і CDC 7600 з конвеєрними потрапляють в цей клас.
SIMD (один потік інструкцій / безліч потоків даних) — одиночний потік команд і множинний потік даних (рис. 3.б). В архітектурах подібного роду зберігається один потік команд, що включає, на відміну від попереднього класу, векторні команди. Це дозволяє виконувати одну арифметичну операцію відразу над багатьма даними — елементами вектора. Спосіб виконання векторних операцій не обмовляється, тому обробка елементів вектора може виробляється або процесорної матрицею, як в ILLIAC IV, або за допомогою конвеєра, як, наприклад, в машині CRAY-1.
MISD (кілька інструкцій потік / єдиний потік даних) — тип архітектури паралельних обчислень, де кілька функціональних модулів (два або більше) виконують різні операції над одними даними (рис. 3.в).
Відмовостійкі комп'ютери, що виконують одні й ті ж команди надлишково з метою виявлення помилок, як випливає з визначення, належать до цього типу. До цього типу іноді відносять конвеєрну архітектуру, але не всі з цим згодні, тому що дані будуть різнитися після обробки на кожній стадії в конвеєрі. Деякі відносять систолічний масив процесорів до архітектури MISD.
Було створено трохи ЕОМ з MISD-архітектурою, оскільки MIMD і SIMD найчастіше є більш придатними для загальних методик паралельних даних. Вони забезпечують краще масштабування та використання обчислювальних ресурсів, ніж архітектура MISD [6].
MIMD (безліч потоків інструкцій / безліч потоків даних) — множинний потік команд і множинний потік даних (рис. 3.Г). Цей клас припускає, що в обчислювальній системі є декілька пристроїв обробки команд, об'єднаних в єдиний комплекс і працюючих кожне зі своїм потоком команд і даних [7].

Рисунок 3 — Види архітектур по Флинну
4.2 Hardware‐рішення
Потужності сучасних процесорів достатньо для вирішення елементарних кроків більшості завдань, а об'єднання декількох десятків таких процесорів дозволяє швидко і ефективно вирішувати багато поставлені завдання, не вдаючись до допомоги мейнфреймів і супер комп'ютерів.
З'явилася ідея створення паралельних обчислювальних систем із загальнодоступних комп'ютерів на базі процесорів Intel і недорогих Ethernet-мереж, встановивши на ці комп'ютери Linux і, об'єднавши за допомогою однієї з безкоштовно розповсюджуваних комунікаційних бібліотек (PVM або MPI) ці комп'ютери в кластер. Експерименти показали, що на багатьох класах задач і при достатньому числі вузлів такі системи дають продуктивність, яку можна отримати, використовуючи дорогі суперкомп'ютери [8].
Також крім кластерної технології використовується архітектура CUDA. CUDA — це програмно-апаратна архітектура, дозволяє робити обчислення з використанням графічних процесорів NVIDIA, що підтримують технологію GPGPU (Довільних обчислень на відеокартах).
CUDA SDK дозволяє програмістам реалізовувати на спеціальному спрощеному діалекті мови програмування Сі алгоритми, здійснимі на графічних процесорах NVIDIA, і включати спеціальні функції в текст програми на Cи. CUDA дає розробнику можливість на свій розсуд організовувати доступ до набору інструкцій графічного прискорювача і управляти його пам'яттю, організовувати на ньому складні паралельні обчислення [9].
Також для вирішення задач паралельного програмування можна використовувати багатоядерні процесори спільно зі спеціальним ПО і бібліотеками, наприклад, Microsoft Parallel Extensions для. Net Framework.
4.3 Software‐рішення
Для реалізації кластерної технології існує кілька комунікаційних бібліотек. Розглянемо дві з них: PVM і MPI.
PVM (Parallel Virtual Machine) являє собою програмний пакет, який дозволяє об'єднує Unix та / або Windows, комп'ютери через мережу, і таким чином зможуть використовуватися як один великий паралельний комп'ютер. Таким чином великі обчислювальні завдання можуть бути вирішені більш економічно і ефективно, використовуючи сукупність потужності та пам'яті багатьох комп'ютерів. PVM дозволяє користувачам використовувати свої існуючі апаратні засоби для вирішення проблеми при мінімальних витратах [10].
MPI розшифровується як "інтерфейс передачі повідомлень" ("Інтерфейс передачі повідомлень"). MPI — це стандарт на програмний інструментарій для забезпечення зв'язку між окремими процесами паралельної завдання. MPI надає програмісту єдиний механізм взаємодії процесів всередині паралельно виконується завдання незалежно від машинної архітектури (однопроцесорні, багатопроцесорні із загальною або роздільною пам'яттю), взаємного розташування процесів (На одному фізичному процесорі або на різних) і API операційної системи [11].
Для реалізації паралельних обчислень на GPU (CUDA) або процесор (багатоядерні процесори) можна використовувати OpenCL або OpenMP.
OpenCL (від англ Open Computing Language — відкрита мова обчислень) — фреймворк для написання комп'ютерних програм, пов'язаних з паралельними обчисленнями на різних графічних (англ. GPU) і центральних процесорах (Англ. CPU) [12].
OpenMP (Open Multi-Processing) — відкритий стандарт для розпаралелювання програм на мовах Сі, Сі + + і Фортран. Описує сукупність директив компілятора, бібліотечних процедур і змінних оточення, які призначені для програмування багатопотокових додатків на багатопроцесорних системах із загальною пам'яттю.
Висновки
Для вирішення поставленого завдання буде використовуватися кластер, що складається з декількох комп'ютерів. В якості операційної системи буде використовуватися Windows, а як засіб розпаралелювання обчислень використовуємо сокети. Для реалізації кластерної технології застосуємо комунікаційну бібліотеку MPI.
Дані кошти були обрані виходячи з відносно низькою вартістю, доступності і порівняно легкої реалізації проекту. Також за рахунок такої структури можливо зручне конфігурування системи і підвищення продуктивності шляхом додавання комп'ютерів в кластер.
Список джерел
- Метод Particle Image Velocimetry: основы систем цифровой трассерной визуализации. [Электронный ресурс]. – 2011. – Режим доступа: http://cameraiq.ru/faq/flow_diagnostics/PIV_method/PIV_basic. – Загл. с экрана.
- PIV-метод. [Электронный ресурс]. – 2011. – Режим доступа: http://www.laser-portal.ru/content_184#_ftn1. – Загл. с экрана.
- Хабахпашева Е.М., Перепелица Б.В. Поля скоростей и турбулентных пульсаций при малых добавках к воде высокомолекулярных веществ // ИФЖ. 1968. T. 14, № 4. C. 598.
- Adrian R.J. Scattering particle characteristics and their effect on pulsed laser measurements of fluid flow: speckle velocimetry vs. particle image velocimetry // Appl. Opt. 1984. Vol. 23. P. 1690–1691
- Meynart R. Convective flow field measurement by speckle velocimetry // Rev. Phys.Appl. 982. Vol. 17. P. 301–330.
- MISD. [Электронный ресурс]. – 2011. – Режим доступа: http://ru.wikipedia.org/wiki/MISD. – Загл. с экрана.
- Воеводин В.В. Классификация Флинна. [Электронный ресурс]. – 2011. – Режим доступа: http://www.parallel.ru/computers/taxonomy/flynn.html. – Загл. с экрана.
- Сбитнев Ю.И. Параллельные вычисления. [Электронный ресурс]. – 1998-2011. – Режим доступа: http://cluster.linux-ekb.info. – Загл. с экрана.
- CUDA. [Электронный ресурс]. – 2012. – Режим доступа: http://ru.wikipedia.org/wiki/CUDA. – Загл. с экрана.
- Parallel Virtual Machine. [Электронный ресурс]. – 2011. – Режим доступа: http://www.portablecomponentsforall.com/edu/pvm-ru. – Загл. с экрана.
- Сбитнев Ю.И. Кластеры. Практическое руководство. – Екатеринбург, 2009. – 45 с.
- OpenCL. [Электронный ресурс]. – 2012. – Режим доступа: http://ru.wikipedia.org/wiki/OpenCL. – Загл. с экрана.