
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи магистерской работы
- 3. Описание метода PIV
- 4. Обзор методов параллельных вычислений
- 4.1 Классификация архитектур параллельных вычислительных систем
- 4.2 Hardware – решения
- 4.3 Software – решения
- Выводы
- Список источников
Введение
В наше время круг задач, требующих для своего решения применения мощных вычислительных ресурсов, постоянно расширяется. Это связано с тем, что произошли фундаментальные изменения в самой организации научных исследований. Вследствие широкого внедрения вычислительной техники, значительно усилилось направление численного моделирования и численного эксперимента. Численное моделирование, заполняя промежуток между физическими экспериментами и аналитическими подходами, позволило изучать явления, которые являются либо слишком сложными для исследования аналитическими методами, либо слишком дорогостоящими или опасными для экспериментального изучения. При этом численный эксперимент позволил значительно удешевить процесс научного и технологического поиска. Стало возможным моделировать в реальном времени процессы интенсивных физико-химических и ядерных реакций, глобальные атмосферные процессы, процессы экономического и промышленного развития регионов и т.д. Очевидно, что решение таких масштабных задач требует значительных вычислительных ресурсов.
1. Актуальность темы
В настоящее время имеется несколько реализаций метода Particle Image Velocimetry (PIV) [1], однако, ни одна из них не поддерживает распределенных параллельных вычислений, что могло бы в разы увеличить быстродействие. За счет увеличения производительности, станет возможным более оперативное изменение параметров исследуемого объекта.
Этот метод получил широкое распространение в различных областях науки и техники. Наиболее популярное применение — это моделирование поведения кипящего слоя.
В настоящее время кипящий слой получил применение в широком круге областей: пищевая промышленность (растворимый кофе, чай, мюсли т.д.), химическая промышленность (полимеры, поликарбонаты, моющие вещества и т.д.), другие отрасли промышленности (активированный уголь, гипс, пески и др.). Особенно актуально применение кипящего слоя в области энергетики для боле эффективного сжигания топлива и уменьшения выбросов в атмосферу.
2. Цель и задачи магистерской работы
Цель магистерской работы заключается в том, чтобы ускорить работу метода PIV при помощи средств параллельного программирования.
Задачами работы являются исследования существующих систем, реализующих метод PIV, анализ способов распараллеливания вычислительных процессов, применение одного из способов для ускорения работы реализации метода PIV . Также необходимо провести сравнительный анализ скорости работы системы при различных конфигурациях системы, выявить оптимальные параметры работы, а также провести исследования возможностей ускорения вычислительных процессов.
3. Описание метода PIV
Методы визуализации для изучения потоков были известны задолго до появления электронных вычислительных машин. Первые наблюдения за течением жидкости в водоемах при помощи естественных природных трассеров были описаны еще Леонардо да Винчи. Людвиг Прандтль (1875–1953) использовал взвесь из частиц слюды на поверхности воды для анализа обтекания цилиндров, призм и профилей крыла в экспериментальном канале.
Постепенно от качественных наблюдений произошел переход к измерению количественных характеристик течений, и к 60-м годам XX столетия сформировалось широкое направление в диагностике, известное как «стробоскопическая визуализация». Принцип стробоскопической трассерной визуализации заключается в измерении смещения трассеров в заданном сечении потока жидкости или газа за известный интервал времени. Областью измерения служит плоскость, освещаемая световым ножом (рис. 1) [2].
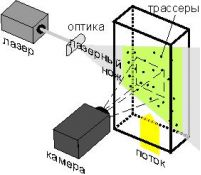
Рисунок 1 — Стробоскопическая визуализация
Результатом измерения является мгновенное поле скорости в измерительной плоскости. Одной из наиболее показательных отечественных работ того времени является статья [3], в которой приведены результаты измерения полей скорости и турбулентных пульсаций в пограничном слое на пластине, полученные путем ручной обработки трассерных картин, зарегистрированных на фотографической пленке. Однако ручная обработка была трудоемка, занимала длительное время и не позволяла получать достаточного объема данных для расчета статистических характеристик. Данная ситуация являлась типичной для всех исследовательских групп в мире, занимавшихся количественной визуализацией потоков.
Появление термина PIV (Particle Image Velocimetry) — международное название метода цифровой трассерной визуализации, связывают с работой [4] в которой метод PIV был выделен как частный случай метода лазерной спеклометрии LSV (Laser Speckle Velocimetry) [5] базирующегося на оптическом преобразовании Фурье яркостных картин.
Пример обработки изображений методом PIV представлен на рисунке 2.

Рисунок 2 — Обработка изображений методом PIV (анимация: 7 кадров, 5 циклов повторения, 163 килобайта)
4. Обзор методов параллельных вычислений
4.1 Классификация архитектур параллельных вычислительных систем
Самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.
SISD (single instruction stream / single data stream) — одиночный поток команд и одиночный поток данных (рис 3.а). К этому классу относятся классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка — как машина CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными попадают в этот класс.
SIMD (single instruction stream / multiple data stream) — одиночный поток команд и множественный поток данных (рис. 3.б). В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными — элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1.
MISD (multiple instruction stream / single data stream) — тип архитектуры параллельных вычислений, где несколько функциональных модулей (два или более) выполняют различные операции над одними данными (рис. 3.в).
Отказоустойчивые компьютеры, выполняющие одни и те же команды избыточно с целью обнаружения ошибок, как следует из определения, принадлежат к этому типу. К этому типу иногда относят конвейерную архитектуру, но не все с этим согласны, так как данные будут различаться после обработки на каждой стадии в конвейере. Некоторые относят систолический массив процессоров к архитектуре MISD.
Было создано немного ЭВМ с MISD-архитектурой, поскольку MIMD и SIMD чаще всего являются более подходящими для общих методик параллельных данных. Они обеспечивают лучшее масштабирование и использование вычислительных ресурсов, чем архитектура MISD [6].
MIMD (multiple instruction stream / multiple data stream) — множественный поток команд и множественный поток данных (рис. 3.г). Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных [7].

Рисунок 3 — Виды архитектур по Флинну
4.2 Hardware – решения
Мощности современных процессоров достаточно для решения элементарных шагов большинства задач, а объединение нескольких десятков таких процессоров позволяет быстро и эффективно решать многие поставленные задачи, не прибегая к помощи мэйнфреймов и супер компьютеров.
Появилась идея создания параллельных вычислительных систем из общедоступных компьютеров на базе процессоров Intel и недорогих Ethernet-сетей, установив на эти компьютеры Linux и, объединив с помощью одной из бесплатно распространяемых коммуникационных библиотек (PVM или MPI) эти компьютеры в кластер. Эксперименты показали, что на многих классах задач и при достаточном числе узлов такие системы дают производительность, которую можно получить, используя дорогие суперкомпьютеры [8].
Также помимо кластерной технологии используется архитектура CUDA. CUDA — это программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах).
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA, и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления [9].
Также для решения задач параллельного программирования можно использовать многоядерные процессоры совместно со специальным ПО и библиотеками, например, Microsoft Parallel Extensions to the .Net Framework.
4.3 Software – решения
Для реализации кластерной технологии существует несколько коммуникационных библиотек. Рассмотрим две из них: PVM и MPI.
PVM (Parallel Virtual Machine) представляет собой программный пакет, который позволяет объеденять Unix и / или Windows компьютеры через сеть, и таким образом смогут использоваться как один большой параллельный компьютер. Таким образом большие вычислительные задачи могут быть решены более экономично и эффективно, используя совокупность мощности и памяти многих компьютеров. PVM позволяет пользователям использовать свои существующие аппаратные средства для решения проблемы при минимальных затратах [10].
MPI расшифровывается как "Message passing interface" ("Интерфейс передачи сообщений"). MPI — это стандарт на программный инструментарий для обеспечения связи между отдельными процессами параллельной задачи. MPI предоставляет программисту единый механизм взаимодействия процессов внутри параллельно исполняемой задачи независимо от машинной архитектуры (однопроцессорные, многопроцессорные с общей или раздельной памятью), взаимного расположения процессов (на одном физическом процессоре или на разных) и API операционной системы [11].
Для реализации параллельных вычислений на GPU (CUDA) или CPU (многоядерные процессоры) можно использовать OpenCL либо OpenMP.
OpenCL (от англ. Open Computing Language — открытый язык вычислений) — фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических (англ. GPU) и центральных процессорах (англ. CPU) [12].
OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран. Описывает совокупность директив компилятора, библиотечных процедур и переменных окружения, которые предназначены для программирования многопоточных приложений на многопроцессорных системах с общей памятью.
Выводы
Для решения поставленной задачи будет использоваться кластер, состоящий из нескольких компьютеров. В качестве операционной системы будет использоваться Windows, а в качестве средства распараллеливания вычислений используем сокеты. Для реализации кластерной технологии применим коммуникационную библиотеку MPI.
Данные средства были выбраны исходя из относительно низкой стоимости, доступности и сравнительно легкой реализации проекта. Также за счет такой структуры возможно удобное конфигурирование системы и повышение производительности путем добавления компьютеров в кластер.
Список источников
- Метод Particle Image Velocimetry: основы систем цифровой трассерной визуализации. [Электронный ресурс]. – 2011. – Режим доступа: http://cameraiq.ru/faq/flow_diagnostics/PIV_method/PIV_basic. – Загл. с экрана.
- PIV-метод. [Электронный ресурс]. – 2011. – Режим доступа: http://www.laser-portal.ru/content_184#_ftn1. – Загл. с экрана.
- Хабахпашева Е.М., Перепелица Б.В. Поля скоростей и турбулентных пульсаций при малых добавках к воде высокомолекулярных веществ // ИФЖ. 1968. T. 14, № 4. C. 598.
- Adrian R.J. Scattering particle characteristics and their effect on pulsed laser measurements of fluid flow: speckle velocimetry vs. particle image velocimetry // Appl. Opt. 1984. Vol. 23. P. 1690–1691
- Meynart R. Convective flow field measurement by speckle velocimetry // Rev. Phys.Appl. 982. Vol. 17. P. 301–330.
- MISD. [Электронный ресурс]. – 2011. – Режим доступа: http://ru.wikipedia.org/wiki/MISD. – Загл. с экрана.
- Воеводин В.В. Классификация Флинна. [Электронный ресурс]. – 2011. – Режим доступа: http://www.parallel.ru/computers/taxonomy/flynn.html. – Загл. с экрана.
- Сбитнев Ю.И. Параллельные вычисления. [Электронный ресурс]. – 1998-2011. – Режим доступа: http://cluster.linux-ekb.info. – Загл. с экрана.
- CUDA. [Электронный ресурс]. – 2012. – Режим доступа: http://ru.wikipedia.org/wiki/CUDA. – Загл. с экрана.
- Parallel Virtual Machine. [Электронный ресурс]. – 2011. – Режим доступа: http://www.portablecomponentsforall.com/edu/pvm-ru. – Загл. с экрана.
- Сбитнев Ю.И. Кластеры. Практическое руководство. – Екатеринбург, 2009. – 45 с.
- OpenCL. [Электронный ресурс]. – 2012. – Режим доступа: http://ru.wikipedia.org/wiki/OpenCL. – Загл. с экрана.