
Реферат по теме выпускной работы
Содержание
1. Цели и задачи исследования, планируемые результаты
2. Аналитическая модель вычисления производительности сетевого процессора
3. Анализ с помощью сетевого графика
5. Аппроксимация кривых обслуживания и входных потоков
Введение
Ежесекундно в телекоммуникационных сетях происходит обмен огромным количеством пакетов, которые должны обрабатываться различным образом. Для поддержания дееспособности сетей и обработки данных пакетов служат такие устройства как свитчи, адаптеры, роутеры, брандмауэеры и тому прочее.
Количество пакетов, которые необходимо обработать сетевым системам, все время увеличивается, в то же время, обработка пакетов становится все более и более сложной. Это создает гигантскую проблему производительности. Разрешить данную проблему призваны сетевые процессоры.
1. Цели и задачи исследования, планируемые результаты
В данной работе будет показано, каким образом возможно аналитически вычислить производительность сетевого процессора. Основные задачи исследования:
1. Рассмотреть существующую аналитическую модель вычисления производительности сетевого процессора.
2. Исследовать характеристики, влияющие на производительность сетевого процессора.
3. Изучить понятие сетевого графика.
4. Провести анализ производительности типовой архитектуры сетевого процессора, с помощью сетевого графика.
Объект исследования: производительность сетевого процессора.
Предмет исследования: аналитическая модель вычисления производительности сетевого процессора.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
1. Исследования сетевых процессоров: требования предоставленные к архитектуре, основные модули, алгоритмы работы.
2. Исследование влияния топологии сети на ее характеристики.
3. Построение экспертной системы, моделирующей оптимальные архитектуры сетевых процессоров, исходя из заданной конфигурации сети.
Для экспериментальной оценки полученных теоретических результатов и формирования фундамента последующих исследований, в качестве практических результатов планируется разработка кроссплатформенной системы, позволяющей подобрать оптимальную архитектуру сетевого процессора, исходя из заданных требований, рассчитать различные характеристики, как сетевого процессора так и сети в целом.
2. Аналитическая модель вычисления производительности сетевого процессора
Сетевой процессор рассматривается как коллекция различных обрабатывающих элементов (таких как CPU, ядро, микро-устройства, и специальные юниты, такие как шифратор, аппаратный классификатор и так далее) и модулей памяти, которые соединены между собой коммуникационными шинами.[1] На каждом из этих обрабатывающих элементах реализуется одна или более задач обработки. В зависимости от последовательности, в которой эти задачи обрабатывают пакет, и связи этих задач с различными обрабатывающими элементами сетевого процессора, любой пакет, поступающий в сетевой процессор, проходит через специфическую последовательность различных обрабатывающих элементов. Поток, которому принадлежит пакет, связан со своей кривой входящего потока. Таким образом, все ресурсы имеют свои сервисные кривые (кривые обслуживания). Так как пакеты в потоке двигаются от одного обрабатывающего элемента к другому, а также проходят через коммуникационные ресурсы, такие как шины, обе кривые: сервисные и входящего потока, — будут модифицированы согласно формулам, приведенным ниже:
![]() (1)
(1)
![]() (2)
(2)
![]() (3)
(3)
![]() (4)
(4)
, где ![]() - поток пакетов, после обработки ресурсом
- поток пакетов, после обработки ресурсом ![]() ,
, ![]() и
и ![]() - верхняя и нижняя
кривая входного потока. Аналогично,
- верхняя и нижняя
кривая входного потока. Аналогично, ![]() и
и ![]() - верхняя и нижняя
кривые, оставшихся сервисов ресурса
- верхняя и нижняя
кривые, оставшихся сервисов ресурса ![]() .
.
Отсюда, максимальная задержка сквозной передачи данных любого пакета, необходимая память чипа сетевого процессора и утилизация различных ресурсов, может быть вычислена по формулам (5), (6) и (7) соответственно.
![]() (5)
(5)
![]() (6)
(6)
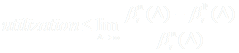 (7)
(7)
Формально процедуры, представленные выше, представляют
собой следующее. Для множества потоков ![]() , входящих в сетевой процессор, существует граф задач
, входящих в сетевой процессор, существует граф задач ![]() . Любая вершина
. Любая вершина ![]() означает коммуникационную задачу или задачу обработки. Для любого потока
означает коммуникационную задачу или задачу обработки. Для любого потока ![]() , определим набор задач пакетной обработки
, определим набор задач пакетной обработки ![]() , которые должны быть реализованы всеми пакетами
, которые должны быть реализованы всеми пакетами ![]() . В дополнение, подмножество направленных ребер
. В дополнение, подмножество направленных ребер ![]() определяет порядок, в
котором задачи в
определяет порядок, в
котором задачи в ![]() должны быть
реализованы для любого пакета
должны быть
реализованы для любого пакета ![]() . Таким образом, если
. Таким образом, если ![]() представляет собой две
задачи, такие, что для любого пакета, который принадлежит
представляет собой две
задачи, такие, что для любого пакета, который принадлежит ![]() , задача
, задача ![]() должна быть выполнена
немедленно после задачи
должна быть выполнена
немедленно после задачи ![]() , то направленное ребро
, то направленное ребро ![]() принадлежит множеству
принадлежит множеству ![]() . Отсюда, для каждого потока
. Отсюда, для каждого потока ![]() существует уникальный
путь через граф
существует уникальный
путь через граф ![]() , начиная от одной из его вершин источников и заканчивая
одной из вершин получателя. Вершины этого пути представляют собой задачи
пакетной обработки, которые реализованы на пакетах, принадлежащих
, начиная от одной из его вершин источников и заканчивая
одной из вершин получателя. Вершины этого пути представляют собой задачи
пакетной обработки, которые реализованы на пакетах, принадлежащих ![]() .
.
Рисунок 1 показывает гипотетическую блочную архитектуру сетевого процессора [2,3]. PPC обозначает ядро Power-PC 440, PLB и OPB – две шины, которые являются локальной шиной процессора и переферической шиной чипа. Цифры на стрелках в данном рисунке, определяют порядок действий, которые выполняются различными блоками в процессе движения пакета через архитектуру.

Рисунок 1 – Гипотетическая блочная архитектура сетевого процессора. Анимация выполнена с помощью Phothop CS2. Задержка: 1с, задержка после финального кадра: 2с. Количество кадров: 12. Приблизительный размер: 30Кб.
Исходя из рисунка 1, можно построить график задач в соответствии с необходимым маршрутом пересылки пакета от одного ресурса к другому. Этот график задач может быть использован для вычисления нагрузки на различных шинах (таких как OPB или PLB), требований к памяти чипа данной архитектуры для хранения буферизированных пакетов и задержки при пересылки пакетов.
3. Анализ с помощью сетевого графика
Исходящая кривая входного потока охватывает характеристики обрабатываемого потока пакетов (например, его пакетные данные), которые могут отличаться от характеристик потока, имеющихся до входа в ресурс. Таким образом, исходящая сервисная кривая показывает возможности ресурса для обработки, которые остались после обработки потока. Идея состоит в использовании данной исходящей кривой входного потока, как входа в другой ресурсный узел (точнее, узел ресурса, в котором происходит следующая задача обработки пакета, определенная графиком задач, описанным выше). Аналогичным образом, исходящая сервисная кривая первого ресурса используется для обработки пакетов из возможного второго потока. Данная процедура соответствует пересылке пакетов в архитектуре, изображенной на рисунке 1. [4]
В общем случае, множество потоков входит в сетевой процессор и обрабатывается различными ресурсами в порядке, определенном графиком задач описанным выше. Так как пакеты из нескольких потоков пребывают в ресурс, они обслуживаются в порядке, определенном политикой планирования, которая реализована на ресурсе. Например, несколько шин используют схему фиксированных приоритетов управления доступа шиной. Другие правила планирования могут использовать FCFS (first-come-first-serve) или схему циклического обслуживания. Здесь мы иллюстрируем аналитическую модель, предполагая, что все ресурсы имеют фиксированный приоритет. Однако, данная модель может быть с легкостью расширена для работы с другими правилами планирования. Предположим, что существует В схеме с фиксированными приоритетами, ![]() потоков
потоков ![]() , которые прибывают в ресурс
, которые прибывают в ресурс ![]() . Данный ресурс, в свою очередь, обслуживает эти потоки в
порядке уменьшения приоритета, то есть,
. Данный ресурс, в свою очередь, обслуживает эти потоки в
порядке уменьшения приоритета, то есть, ![]() имеет наибольший
приоритет, а
имеет наибольший
приоритет, а ![]() наименьший. Для
каждого пакета потока
наименьший. Для
каждого пакета потока ![]() , некоторая задача по обработке пакета, реализованная на
ресурсе
, некоторая задача по обработке пакета, реализованная на
ресурсе ![]() , обрабатывает данный пакет и нуждается в
, обрабатывает данный пакет и нуждается в ![]() элементах обработки
элементах обработки ![]() . Например,
. Например, ![]() может быть количеством
инструкций процессора или циклами шины, если
может быть количеством
инструкций процессора или циклами шины, если ![]() — коммуникационный ресурс. С этого момента обозначим
— коммуникационный ресурс. С этого момента обозначим ![]() , как
, как ![]() , где
, где ![]() — номер ресурса. Каждый поток
— номер ресурса. Каждый поток ![]() , прибывающий в ресурс
, прибывающий в ресурс ![]() , связан с его верхними и нижними кривыми входного потока
, связан с его верхними и нижними кривыми входного потока ![]() и
и ![]() соответственно и
получает обслуживающий сервис из
соответственно и
получает обслуживающий сервис из ![]() , который может быть привязан к верхним и нижним кривым
обслуживания
, который может быть привязан к верхним и нижним кривым
обслуживания ![]() и
и ![]() соответственно. Сервис, который доступен из
соответственно. Сервис, который доступен из ![]() в незагруженном
состоянии, привязан к верхним и нижним кривым обслуживания
в незагруженном
состоянии, привязан к верхним и нижним кривым обслуживания ![]() и
и ![]() соответственно.[5]
соответственно.[5]
![]() обслуживает потоки в
порядке уменьшения приоритетов кривая оставшихся сервисов потока используется
для обслуживания потоков с более низкими приоритетами.
обслуживает потоки в
порядке уменьшения приоритетов кривая оставшихся сервисов потока используется
для обслуживания потоков с более низкими приоритетами.![]() . Если
. Если ![]() и
и ![]() исходящие кривые входного
потока из узла ресурса вычисляются используя формулы
(1) — (2), то
исходящие кривые входного
потока из узла ресурса вычисляются используя формулы
(1) — (2), то ![]() и
и ![]() . Функции минимума/максимума используются с момента, когда
узел ресурса может начать обработку пакета и только после того как задача,
реализованная на
. Функции минимума/максимума используются с момента, когда
узел ресурса может начать обработку пакета и только после того как задача,
реализованная на ![]() , будет завершена.
, будет завершена.
Итак, данные кривые обслуживания для незагруженного ресурса ![]() и
и ![]() , и кривые входного потока
, и кривые входного потока ![]() , показывают, как могут быть определены кривые обслуживания
, показывают, как могут быть определены кривые обслуживания ![]() и
и ![]() . Как было описано выше:
. Как было описано выше:
![]() ,
, ![]() ,
, ![]()
![]()
![]()
![]()
![]()
![]()
![]() ,
, ![]() ,
, ![]()
, где ![]() и
и ![]() для
для ![]() определено из формул
(3) и (4). В конечном счете, сервисные кривые, оставшиеся после
обработки всех потоков имеют вид:
определено из формул
(3) и (4). В конечном счете, сервисные кривые, оставшиеся после
обработки всех потоков имеют вид:
![]()
![]()
Описанное выше может быть использовано для вычисления
максимальной утилизации ресурса, используя неравенство (7). Обработанные
потоки с их результирующими кривыми входного потока ![]() и
и ![]() теперь входят в узел
ресурса для дальнейшей обработки.
теперь входят в узел
ресурса для дальнейшей обработки.
4. Создание сетевого графика
Используя ранее полученные результаты можно описать процедуру создания сетевого графика. Он может быть использован для определения свойств архитектуры, таких как требования к памяти чипа, задержки в передаче пакетов и утилизация различных ресурсов чипа, таких как процессоры и шины.
Входы необходимо конструировать, рассматривая сеть как график задач, который определяет для каждого потока последовательность задач обработки пакетов, которые будут выполнены для каждого пакета потока. Также необходимо брать в учет целевую архитектуру, на которой эти задачи будут выполняться.
Сетевой график содержит один узел источника и узел
ресурса и один узел целевого ресурса. То есть, для каждого потока
пакетов существует узел источника пакетов и целевой узел пакета. Для каждой
задачи обработки пакета потока существует узел в сети, помеченный задачей и
ресурсом, на котором эта задача выполняется.[6] Для
двух последовательных задач потока ![]() и
и ![]() , если
, если ![]() имплементирована на
ресурсе
имплементирована на
ресурсе ![]() , а
, а ![]() на ресурсе
на ресурсе ![]() , то существует грань в сетевом графике из узла
, то существует грань в сетевом графике из узла ![]() в узел
в узел ![]() . Для данного потока, если
. Для данного потока, если ![]() и
и ![]() — две задачи, выполняемые на одном
ресурсе
— две задачи, выполняемые на одном
ресурсе ![]() и
и ![]() предшествует
предшествует ![]() в графе задач, то
существует грань из узла
в графе задач, то
существует грань из узла ![]() в узел
в узел ![]() .
.
Кривые входных потоков и кривые облуживания ресурсов проходят из одного узла в другой в сетевом графике и изменяются в процессе, согласно формулам (1) — (4).
Для данного потока ![]() , примем верхней кривой входного потока
, примем верхней кривой входного потока ![]() , перед входом в сетевой процессор. Предположим, что этот
поток проходит через узлы сетевого графика, который имеет входные нижние
сервисные кривые равные
, перед входом в сетевой процессор. Предположим, что этот
поток проходит через узлы сетевого графика, который имеет входные нижние
сервисные кривые равные ![]() . Тогда
. Тогда ![]() , которая используется для облуживания данного потока может
быть вычислена следующим образом:
, которая используется для облуживания данного потока может
быть вычислена следующим образом:
![]() ,
,
![]()
![]() ,
,
![]()
Отсюда, максимальная задержка и общее количество
невыполненных задач по отношению к пакетам потока ![]() могут быть рассчитаны
с помощью формул (8) и (9) соответственно.
могут быть рассчитаны
с помощью формул (8) и (9) соответственно.
![]() (8)
(8)
![]() (9)
(9)
5. Аппроксимация кривых обслуживания и входных потоков
Формулы (1) — (4) очевидно избыточны для вычисления обычных кривых обслуживания и входящего потока. Более того, эти формулы должны пересчитываться для всех узлов сетевого графика.[7] В дополнение, если кривые преимущественно получены из следа пакета, то результирующие кривые могут быть описаны несколькими параметрами, такими как максимальный размер пакета, скорость передачи пакетов, скорость прибытия пакетов. Исходя из этого, можно предложить кусочную линейную аппроксимацию кривых обслуживания и прибытия. Используя данную аппроксимацию, формулы (1) — (4) будут вычисляться более эффективно.
Каждая кривая, в этом случае, аппроксимируется, используя комбинацию трех сегментов линии. Это позволяет нам точно смоделировать кривую прибытия в формате T-SPEC, которая широко используется в коммуникационных сетях.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: январь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
1. IBM Blue Logic. Режим доступа http://www.chips.ibm.com/bluelogic свободный.
2. IBM сoreconnect bus architecture. Режим доступа http://www.chips.ibm.com/products/coreconnect свободный.
3. Shenker S. , Wroclawski J., General characterization parameters for integrated service network elements, RFC 2215, IETF, September 1997.
4. Abraham S.G., Rau B.R., Shreiber R., Fast design space exploration through validity and quality filtering of subsystem designs, Technical Report HPL-2001-220, Compiler and Architecture Research Program, Hewlett Packard Laboratories, August 2000.
5. Agarwal A., Performance tradeoffs in multithreaded processors, IEEE Transactions on Parallel and Distributed Systems 3 (5) (1992) 525–539.
6. Alpha Architecture Reference Manual, Digital Press,1992.
7. Le Boudec J.Y., Thiran P., Network Calculus––A Theory of Deterministic Queuing Systems for the Internet, Lecture Notes in Computer Science, vol. 2050, Springer, Berlin, 2001.
8. Burger D.C., Austin T.M., The SimpleScalar tool set, Technical Report CS-TR-1997-1342, University of Wisconsin, Madison, 1997.
9. Chakraborty Samarjit, Kunzli Simon, Thiele Lothar, Herkersdorf Andreas, Sagmeister. Patricia «Performance evaluation of network processor architectures: combining simulation with analytical estimation». Computer Engineering and Networks Laboratory, Swiss Federal Institute of Technology (ETH) Zurich, Gloriastrasse 35, CH-8092 Zurich, Switzerland.