
Essay on the theme of work
Contents
1. The aims and objectives of the research, the expected results
2. Analytical model for calculating network processor performance
3. Analysis with network schedule
4. Creation of a network schedule
5. Curve approximation of service and input streams
Introduction
Every second in telecommunication networks are exchanged a lot of packages that must be handled in different ways. To maintain the capacity of networks and data packets are devices such as switches, adapters, routers, brandmauers and the other.
Number of packets that need to process network systems, increases all the time, at the same time, packet processing is becoming more and more complex. This creates a huge performance problem. Network processors should resolve such problems.
1. The aims and objectives of the research, the expected results
In this paper we show how it is possible to calculate analytically the performance of the network processor. The main objectives of the research:
1. Review existing analytical model to calculate its performance network processor.
2. Investigate the characteristics that affect the performance of network processor.
3. Explore the concept of the network schedule.
4. To analyze the performance of a typical network processor architecture, with a network schedule.
The object of research: the performance of network processor.
Subject of research: an analytical model to calculate network processor performance.
As part of the master's work is to get the actual scientific results in the following areas:
1. Research network processors: the requirements provided by the architecture, core modules, algorithms.
2. Investigation of the influence of network topology on its characteristics.
3. The construction of an expert system that models the optimal architecture of network processors, based on a given network configuration.
For experimental evaluation of the theoretical results and the formation of the foundation further research, as the practical results is planned to develop a cross-platform system to choose the best architecture of the network processor based on the specified requirements, calculate the different characteristics as the network processor and the network as a whole.
2. Analytical model for calculating network processor performance
Network processor is considered as a collection of different processing elements (such as the CPU, core, micro-devices, and special units, such as an encoder, hardware classifier and so on) and memory modules, which are connected by communication buses.[1] At each of these processing elements is realized by one or more processing tasks. Depending on the order in which these tasks are processed packet, and the connection of these problems with different processing element network processor, any packet entering the network processor, passes through a specific sequence of different processing elements. The thread that owns the package associated with its incoming flow curve. Thus, all the resources are of their service curves (lines of service). Because packets in the flow move from one processing element to another, and go through the communication resources, such as tires, both curves: service and downstream, — will be modified according to the formula given below:
![]() (1)
(1)
![]() (2)
(2)
![]() (3)
(3)
![]() (4)
(4)
, where ![]() - package flow, after processing with resource
- package flow, after processing with resource ![]() ,
, ![]() и
и ![]() — upper and lower input curve. Similarly,
— upper and lower input curve. Similarly, ![]() и
и ![]() — upper and lower curves of the remaining services
— upper and lower curves of the remaining services ![]() .
.
Hence, the maximum delay through the data of any package, the required memory chip network processor and utilization of various resources, can be calculated by to (5), (6) and (7) respectively.
![]() (5)
(5)
![]() (6)
(6)
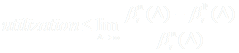 (7)
(7)
Formal procedures outlined above are
the following. For the set of flows ![]() , within the network processor, there exists a graph of tasks
, within the network processor, there exists a graph of tasks ![]() . Any vertex
. Any vertex ![]() means a communication problem or task processing. For any flow
means a communication problem or task processing. For any flow ![]() , define a set of batch processing tasks
, define a set of batch processing tasks ![]() , which must be implemented by all packages
, which must be implemented by all packages ![]() . In addition, a subset of directed edges
. In addition, a subset of directed edges ![]() determines the order in which tasks
determines the order in which tasks ![]() should be implemented for any package
should be implemented for any package ![]() . Thus, if the
. Thus, if the ![]() represents two
tasks, such that for any package that
represents two
tasks, such that for any package that ![]() , task
, task ![]() should be implemented immediately after the task
should be implemented immediately after the task ![]() , a directed edge
, a directed edge ![]() belongs set
belongs set ![]() . Hence, for each flow
. Hence, for each flow ![]() there is a unique path through the graph
there is a unique path through the graph ![]() , from one of its vertices and finishing sources
one of the peaks of the recipient. The vertices of this path are tasks
batch processing, which are implemented on packets belonging
, from one of its vertices and finishing sources
one of the peaks of the recipient. The vertices of this path are tasks
batch processing, which are implemented on packets belonging ![]() .
.
Figure 1 shows a hypothetical block network processor architecture [2,3]. PPC is core Power-PC 440, PLB и OPB – two busses, which are the local bus of the processor chip and peripheral bus. The numbers on the arrows in the figure, determine the course of action undertaken by various units in the process of moving the package through architecture.
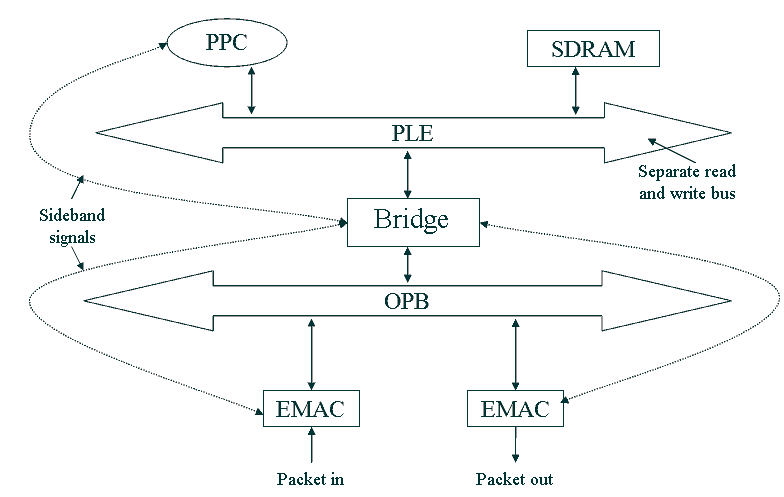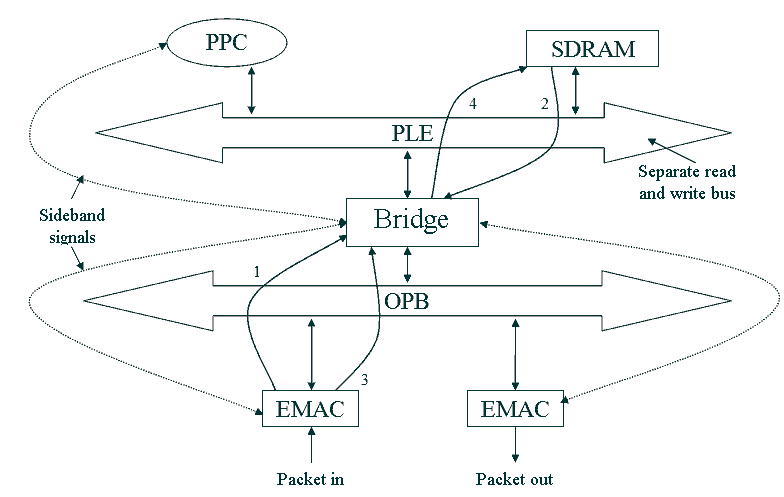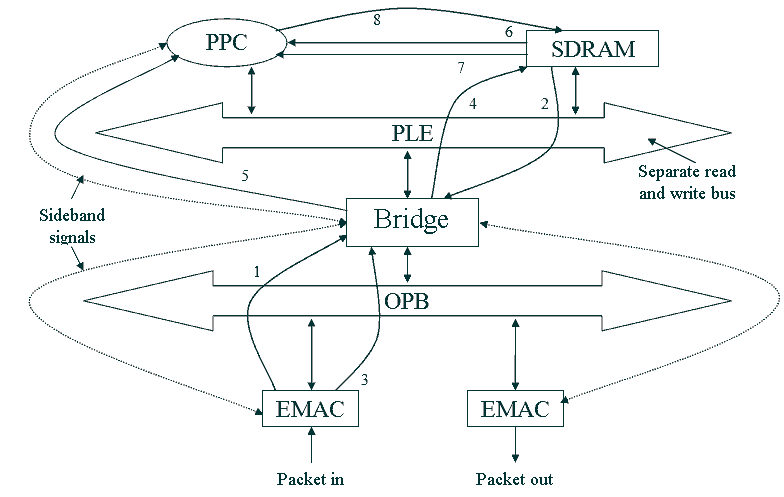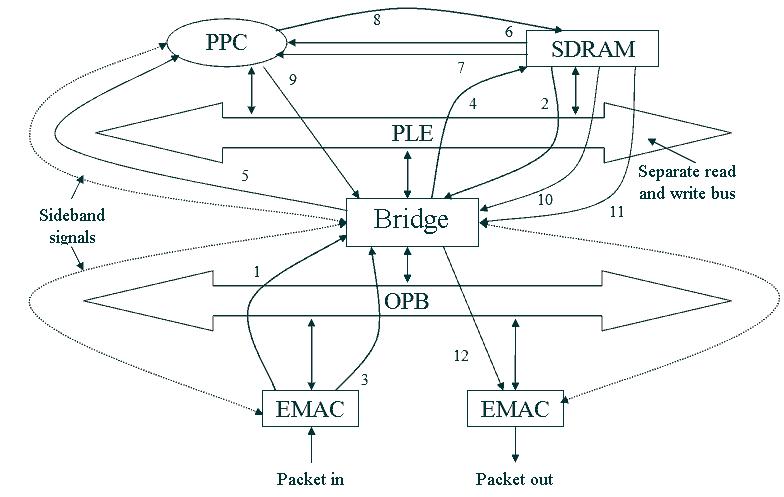
Figure 1 - Hypothetical modular network processor architecture. Animation is made by Phothop CS2. Delay: 1s, the delay after the final frame: 2c. Number of shots: 12. Approximate size: 30KB.
Based on Figure 1, we can construct a schedule of tasks in accordance with the desired route of delivery of a packet from one resource to another. This graph problems can be used to calculate the load on different tires (such as OPB or PLB), the memory requirements of the chip architecture for storing buffered packets and delays in forwarding packets.
3. Analysis with network schedule
Outgoing curve input process stream includes data packets (eg, its packet data), which may differ from the characteristics of the stream, which has to logon to the share. Thus, the outgoing service curve shows the capacity of the resource for processing, which remained after the data flow. The idea is to use this outgoing curve input as the input to another resource node (more precisely, a node of the resource, which is the next task of processing the package, determined schedule of tasks described above). Similarly, the outgoing service curve of the first resource used to process packets from a possible second stream. This procedure corresponds to forward packets in the architecture shown in Figure 1. [4]
In general, the set of flows is a network processor and processed by different resources in the order determined by the schedule of tasks described above. Since packets from multiple flows are in life, they are served in the order established planning policy, which is implemented on the resource. For example, multiple buses use a fixed priority scheme of access control bus. Other rules may be planning to use FCFS (first-come-first-serve) or a round robin scheme. Here we illustrate the analytical model, assuming that all resources have a fixed priority. However, this model can easily be extended to work with other planning rules. Suppose that there
In the scheme with fixed priority, ![]() flows
flows ![]() , which arrive to resource
, which arrive to resource ![]() . This resource, in turn, serves the flows in
decreasing order of priority, that is,
. This resource, in turn, serves the flows in
decreasing order of priority, that is, ![]() has the greatest
priority and
has the greatest
priority and ![]() the smallest. For
each packet flow
the smallest. For
each packet flow ![]() , some package-processing task, implemented on
resource
, some package-processing task, implemented on
resource ![]() , processes the package and needs
, processes the package and needs ![]() processing elements
processing elements ![]() . For example,
. For example, ![]() may be of
CPU instruction or bus cycle if
may be of
CPU instruction or bus cycle if ![]() — communication resource. From this point on we denote
— communication resource. From this point on we denote ![]() , как
, как ![]() , where
, where ![]() — resource number. Each flow
— resource number. Each flow ![]() , coming to resource
, coming to resource ![]() , associated with its upper and lower curves input
, associated with its upper and lower curves input ![]() and
and ![]() respectively, and
receives service service из
respectively, and
receives service service из ![]() , which can be attached to the upper and lower curves
обслуживания
, which can be attached to the upper and lower curves
обслуживания ![]() и
и ![]() respectively. The service, which is available from
respectively. The service, which is available from ![]() No load
condition attached to the upper and lower service curves
No load
condition attached to the upper and lower service curves ![]() и
и ![]() respectively.[5]
respectively.[5]
![]() serves flows
order of decreasing priority curve remaining service flow is
to service flows with lower priorities.
serves flows
order of decreasing priority curve remaining service flow is
to service flows with lower priorities.![]() . If
. If ![]() и
и ![]() outgoing curves input
flow from node resource calculated using formulas
(1) — (2), that
outgoing curves input
flow from node resource calculated using formulas
(1) — (2), that ![]() и
и ![]() . Function minimum/maximum use from the time when
resource node can start processing package, and only after the task
implemented on
. Function minimum/maximum use from the time when
resource node can start processing package, and only after the task
implemented on ![]() , will be completed.
, will be completed.
Thus, the data curves for the unloaded service resource ![]() и
и ![]() , and the curves of the input stream
, and the curves of the input stream ![]() , show how the curves can be defined service
, show how the curves can be defined service ![]() и
и ![]() . As described above:
. As described above:
![]() ,
, ![]() ,
, ![]()
![]()
![]()
![]()
![]()
![]()
![]() ,
, ![]() ,
, ![]()
, where ![]() и
и ![]() для
для ![]() determined from the formula
(3) and (4). Ultimately, service curves left after
treatment of all flows are as follows:
determined from the formula
(3) and (4). Ultimately, service curves left after
treatment of all flows are as follows:
![]()
![]()
Described above can be used to calculate
maximum utilization of the resource, using (7). processed
flows and their resulting curve input ![]() и
и ![]() now part of the site
resource for further processing.
now part of the site
resource for further processing.
4. Creating a network graph
Using the previous results can be described how to create a network schedule. It can be used for determine the properties of architecture, such as the requirements for memory chip delay packet transmission and utilization of the various resources of the chip, such as processors and tires.
Inputs must be designed by considering the network as a schedule tasks, which determines for each flow sequence of tasks packet processing to be performed for each packet flow. It is also necessary taking into account the target architecture on which these objectives will be met.
Roadmap contains one source node and the node
resource and one node of the target resource. That is, for each flow
packages exist source node and destination node packages package. for each
packet processing flow problem exists in a network node, labeled task and
resource on which the task runs.[6] for
two consecutive flow tasks ![]() и
и ![]() , if
, if ![]() to implement
resource
to implement
resource ![]() , а
, а ![]() on resource
on resource ![]() , то there is an edge in the network from node
, то there is an edge in the network from node ![]() to node
to node ![]() . For a given flow, if
. For a given flow, if ![]() и
и ![]() — two tasks performed on one
resource
— two tasks performed on one
resource ![]() и
и ![]() preceded
preceded ![]() in the graph tasks,
There edge from node
in the graph tasks,
There edge from node ![]() в узел
в узел ![]() .
.
Curves and curves of the input streams tinning resources pass from one node to another in the network and changes in the process, according to the formulas (1) — (4).
For a given flow ![]() , take the upper curve of the input stream
, take the upper curve of the input stream ![]() , in front of the network processor. We assume that this
flow through the network graph nodes, which has a lower input
service curves are
, in front of the network processor. We assume that this
flow through the network graph nodes, which has a lower input
service curves are ![]() . Then
. Then ![]() , which is used for tinning of the flow can
be calculated as follows:
, which is used for tinning of the flow can
be calculated as follows:
![]() ,
,
![]()
![]() ,
,
![]()
Hence, the maximum delay and the total number
outstanding problems in relation to the flow of packets ![]() can be calculated
Using (8) and (9) respectively.
can be calculated
Using (8) and (9) respectively.
![]() (8)
(8)
![]() (9)
(9)
5. Curve approximation of service and input streams
Formulas (1) — (4) obviously overkill for calculating normal curves of service and the incoming stream. Moreover, these formulas have to be recomputed for all nodes of network graph.[7] In Additionally, if the curves are mainly derived from the following package, The resulting curve can be described by several parameters such as the maximum packet size, packet rate, the arrival rate packages. On this basis, we propose a piecewise linear curve fitting service and arrival. using this approximation formulas (1) — (4) will be evaluated more efficiently.
Each curve in this case, is approximated, using a combination of the three line segments. This allows us to accurately arrival curve model in the format T-SPEC, which is widely used in communication networks.
This master's work is not completed yet. Final completion: January 2013. The full text of the work and materials on the topic can be obtained from the author or his head after this date.
List of sources
1. IBM Blue Logic. Access mode http://www.chips.ibm.com/bluelogic free.
2. IBM сoreconnect bus architecture. Access mode http://www.chips.ibm.com/products/coreconnect free.
3. Shenker S. , Wroclawski J., General characterization parameters for integrated service network elements, RFC 2215, IETF, September 1997.
4. Abraham S.G., Rau B.R., Shreiber R., Fast design space exploration through validity and quality filtering of subsystem designs, Technical Report HPL-2001-220, Compiler and Architecture Research Program, Hewlett Packard Laboratories, August 2000.
5. Agarwal A., Performance tradeoffs in multiflowed processors, IEEE Transactions on Parallel and Distributed Systems 3 (5) (1992) 525–539.
6. Alpha Architecture Reference Manual, Digital Press,1992.
7. Le Boudec J.Y., Thiran P., Network Calculus––A Theory of Deterministic Queuing Systems for the Internet, Lecture Notes in Computer Science, vol. 2050, Springer, Berlin, 2001.
8. Burger D.C., Austin T.M., The SimpleScalar tool set, Technical Report CS-TR-1997-1342, University of Wisconsin, Madison, 1997.
9. Chakraborty Samarjit, Kunzli Simon, Thiele Lothar, Herkersdorf Andreas, Sagmeister. Patricia «Performance evaluation of network processor architectures: combining simulation with analytical estimation». Computer Engineering and Networks Laboratory, Swiss Federal Institute of Technology (ETH) Zurich, Gloriastrasse 35, CH-8092 Zurich, Switzerland.