
Geographic Information System is designed for the collection, storage, analysis and graphical visualization of spatial data and related information presented in the GIS objects. The term is also used in a narrower sense — GIS as a tool (software) that allows users to search, analyze, and edit digital maps, as well as additional information about the objects.
However, with increasing amount of data stored on the Internet, are having problems rendering a large volume of spatial data.
Nowadays, the most common geographic information system is Google Maps. But this system has its own problems with the mapping of large amounts of spatial data. The mapping GIS data can take a lot of time — even for high–speed Internet, such operations can be a serious challenge, not to mention the connection speed from the average user. One solution to this problem is clustering.
At the moment there are a large number of clustering methods that use different measures and metrics. But despite this, the problem is acute, developing new algorithms and approaches. This problem is quite complicated, so is not completely solved, since for each task, you must select the appropriate algorithm and measure distances. The choice of metrics lies entirely on the researcher, because the clustering results may differ when using different measures.
Nowadays developments in clustering of spatial data by means of Google Maps almost underway. Since there are standard features of the Google Maps API. But in practice standard means clustering does not meet the requirements. Visualization of large amounts of spatial data takes a long time.
This problem will be solved by choosing a more appropriate clustering method, which will greatly improve the display of spatial data and make it easier to work with them.
While working on the thesis work will examine the methods and clustering algorithms, to understand the scope of every of them and select the most suitable for this task. Result will be an information system that will solve the problem of visualizing large amounts of spatial data faster than the standard tools of Google Maps.
Clustering (or cluster analysis) — is the task of partitioning a set of objects into groups called clusters. Within each group must be "similar" objects, and objects of different groups should be different from each other. The main difference between the clustering of the classification is a list of groups that are not clearly defined and determined during the algorithm[4].
Cluster analysis performs the following tasks:
Regardless of subject matter, the use of cluster analysis involves the following steps:
Cluster analysis requires the following data:
After receiving and analyzing the results can adjust the chosen metric and clustering method to obtain optimal results.
Objectives clustering:
In the first case, the number of clusters tend to do less. In the second case is more important to ensure a high degree of similarity of objects within each cluster, a cluster can be any number. In the third case of greatest interest are the individual objects that do not fit into any of the clusters[1].
Classify clustering algorithms in a broad sense, we can for the next two classes.
1. Hierarchical and flat.
Hierarchical algorithms (also known as algorithms, taxonomies) build more than one partition the sample into non–overlapping clusters, and a system of nested partitions. Thus, the output we get a tree of clusters, which is the root of the whole sample, and the leaves — the smallest cluster.
Since the basic system requirement is a performance, the calculation methods with nested hierarchical cluster will only complicate and slow down the process of displaying spatial data.
Flat algorithms construct a single partition of objects into clusters.
Flat algorithms are quite fast and easy–to–action that meets the requirements. In addition, a single partition eliminates the need to store large amounts of intermediate data.
2. Crisp and fuzzy.
Clear (or disjoint) selection algorithms for each object placed in the line number of the cluster, that is, each object belongs to only one cluster.
Since the main feature of the objects in the clusters is their geographical location, it is a clear clustering of the best way to solve the problem of objects on the explicit separation of the group.
Fuzzy (or overlapping) algorithms for each object placed in a matching set of real values, showing the degree of relationship to the object clusters. That is, each object belongs to each cluster with some probability.
When working with spatial data visualization is the main purpose of geo–information, so if the same object will be included in different clusters, it is much harder work and confuse the user.
There are basic steps distribution of objects in clusters. First we need to make a feature vector for each object — usually a set of numerical values. However, there are algorithms that work with qualitative (categorical) features.
In this case, the feature vector will store the geographical coordinates of spatial data.
Once we have defined the feature vector normalization can be done to all of the components gave the same contribution when calculating the "distance". In the process of normalization, all values are reduced to a certain range, for example, [–1, –1] or [0, 1].
For each pair of objects is measured by the "distance" between them — the degree of similarity. There are many metrics are just the major ones:
1. Euclidean distance.
Most common function of the distance. Represents the geometric distance in multidimensional space:
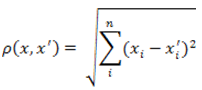
Figure 1 — The formula for Euclidean distance
2. The square of the Euclidean distance.
Used to give greater weight to more distant from each other objects. This distance is calculated as follows:
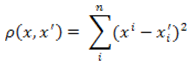
Figure 2 — The formula of the square Euclidean distance
3. Distance from urban areas (Manhattan distance).
This distance is the average of the differences of the coordinates. In most cases, this measure distances leads to the same results as for the usual Euclidean distance. However, for this measure, the effect of large individual differences (emission) decreases (as they are not squared). The formula for calculating the Manhattan distance:
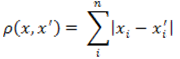
Figure 3 — The Distance Formula urban areas
4. Chebyshev distance.
This distance can be useful when you need to define two objects as "different" if they differ by a single coordinate. Chebyshev distance calculated by the formula:
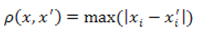
Figure 4 — Chebyshev distance formula
Select metrics lies entirely on the researcher, because the clustering results may differ when using different measures[8].
For this case the most appropriate "distance" — Euclidean, since this measure is ideally suited for the calculation of geographic distances. The rest of the "distance" is less suitable, because they solve specific problems, which only complicate the clustering of spatial data.
Based on system requirements and preferences selected, it is possible to determine the specific clustering algorithm.
Problem of clustering can be viewed as the construction of the optimal partition of objects into groups. In this case the optimality can be defined as the requirement to minimize the mean square error of the partition.
Squared error algorithms are of the type of plane algorithms. The most common algorithm for this category is the method of k–means. This algorithm builds a set number of clusters, located as far away from each other. The algorithm is divided into several stages:
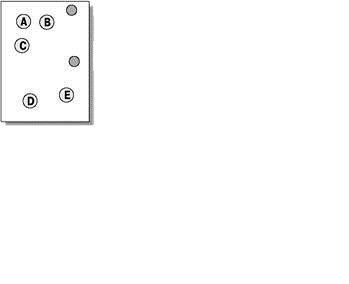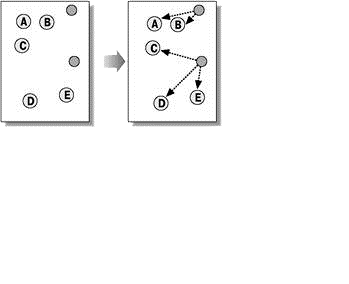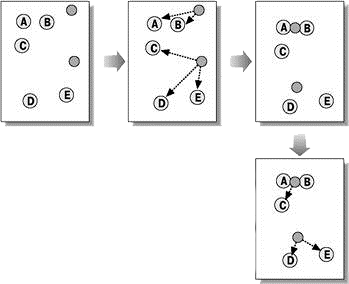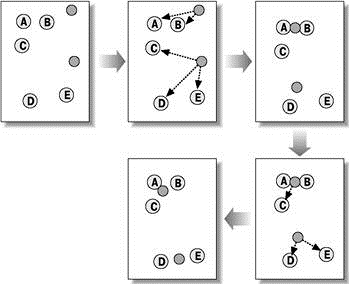
Figure 5 — Method of k–means
(animation: volume — 20 KB, number of frames — 5, number of cycles of repetition — 6, size — 349x284)
As a criterion to stop the algorithm usually opt for the minimum change in mean square error. It is also possible to stop the algorithm if step 2 did not object moved from cluster to cluster.
The disadvantages of this algorithm is the necessity to specify the number of clusters to split, but in this case can be considered a positive feature of this method.
k–means method is also called a quick cluster analysis, using the name, you can determine that this method is most suitable for the clustering of spatial data. So the computational complexity of the method of k–means — O (nkl), where k — the number of clusters, l — the number of iterations. This method fully meets our requirements: speed, clarity of the distribution of clusters. Also, with the ability to initially set the number of clusters, we can calculate the optimal number of displayed objects[2:3].
Since the main objective is to reduce the number of spatial objects are displayed without any data loss, the main goal of clustering is to understand the data, by identifying the cluster structures. Since it has the advantage that lies in the fact that the number of clusters to try to do less.
To effectively solve this problem you need to implement an algorithm that relates to a flat clustering, since it does not need to be embedded in the clusters. All spatial data must be sampled once divided into clusters.
Also algorithm must clearly relate to the clustering, since the intersection of clusters allowed. One–dimensional object will only refer to the same cluster.
To determine the degree of "similarity" of spatial objects based on their position on the map, you must use Euclidean distance as a measure of the distance between the objects to merge them into clusters.
According to a comparative analysis of the basic algorithms for clustering can be concluded that the most appropriate algorithm for the partitioning of spatial data clustering algorithm is the quadratic error. Namely, the method of k–means.
This method is most effectively minimizes the number of displayed data without losing information. The disadvantage of the method — the need to specify the number of clusters does not affect the results.
Other algorithms only complicate the job, increase processing time and load on the traffic.
In general, we can say that clustering — the most effective solution to display large amounts of spatial data, as this method enables compact distribute the information without losing data. This decision was largely affect the performance of geographic information system, and thus reduce the amount of time user.