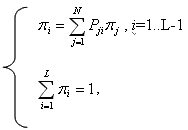Назад в библиотеку
Параллельный алгоритм построения дискретной марковской модели неоднородного кластера
Автор: Кучереносова О.В.
Источник: Государственный университет информатики и искусственного интеллекта. IV Международная научно-практическая конференция молодых ученых, аспирантов, студентов «Современная информационная Украина: информатика, экономика, философия» – Донецьк, 2010.
В статье рассмотрен неоднородный кластер с совместным использованием дискового пространства (рисунок 1).
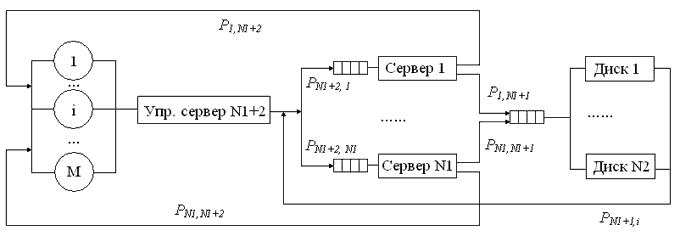
Рисунок 1 – Структурная схема кластера без предоставления доступа к ресурсам
Управляющий сервер распределяет поступающие задачи по серверам приложений. Количество серверов приложений – N1,
дисков – N2. Задачи, обрабатываемые на таком кластере, неоднородные и имеют следующие характеристики:
PN1+2,i – вероятность запроса к i-му серверу, i=1..N1; Pi,N1+1 – вероятность запроса i-го сервера
к одному из N2 дисков, i=1..N1; Pi, N1+2 – вероятность завершения обслуживания задачи i-м сервером, i=1..N1;
PN1+1,i – вероятность завершения обслуживания задачи одним из N2 дисков и поступление на i-й сервер, i=1..N1;
PN1+2,0 – вероятность завершения обслуживания задачи;
P0,N1+2 – вероятность появления новой задачи. Ввиду ограниченных вычислительных возможностей будем считать,
что количество задач, обрабатываемое такой вычислительной системой не более М [1]. Число состояний системы для одного и того
же количества задач 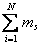 равно числу размещений j задач по N узлам и определяется по формуле
равно числу размещений j задач по N узлам и определяется по формуле
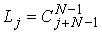 , общее количество состояний вычисляется так:
, общее количество состояний вычисляется так:
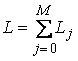
В реализации параллельного алгоритма построния дискретной марковской модели необходимо вычислить матрицу переходных вероятностей и вектор стационарных вероятностей.
Элементы матрицы переходных вероятностей по отношению друг к другу являются независимыми. Это позволяет на каждом из процессоров вычислять отдельную строку, столбец или блок матрицы. Каждый процесс определяет, какие строки (столбцы, блоки) матрицы переходных вероятностей он должен вычислить и отправить управляющему процессу. Этот принцип позволяет равномерно распределить нагрузку между вычислительными узлами и добиться более высоких показателей эффективности по сравнению с последовательным алгоритмом.
Для определения вектора стационарных вероятностей состояний 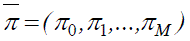 необходимо решить систему линейных алгебраических уравнений (СЛАУ),
необходимо решить систему линейных алгебраических уравнений (СЛАУ),
где 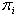 – вероятность застать систему в i-м состоянии.
– вероятность застать систему в i-м состоянии.
Параллельный алгоритм решения данной задачи может быть реализован с помощью итерационного метода, в котором в качестве базового используется алгоритм умножения матрицы на вектор [2]. В основу реализации базового алгоритма может быть взята ленточная (по строкам, по столбцам) или блочная схема разделения данных.
При разделении данных по строкам для выполнения базовой подзадачи скалярного произведения матрицы на вектор процессор должен содержать соответствующую строку (столбец, блок) матрицы P={Pij} и копию вектора
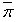 После завершения вычислений каждая базовая подзадача определяет один из элементов вектора результата.
После завершения вычислений каждая базовая подзадача определяет один из элементов вектора результата.
Для объединения результатов расчета и получения полного вектора, рассчитанных стационарных вероятностей, на каждом из процессоров вычислительной системы необходимо выполнить операцию обобщенного сбора данных, в которой каждый процессор передает свой вычисленный элемент вектора результата всем остальным процессорам.
Приведенный в статье параллельный алгоритм построения дискретной марковской модели неоднородного кластера служит для повышения эффективности работы при дальнейшем анализе и реконфигурации подобных систем.
Список использованной литературы
1. Фельдман Л.П., Михайлова Т.В. Дискретная модель Маркова однородного кластера // Искусственный интеллект.– Донецк: ІПШІ МОН і НАН України “Наука і освіта”, №3, 2006. – С. 79-91.
2. Фельдман Л.П., Михайлова Т.В., Ролдугин А.В. Реализация параллельного алгоритма построения марковских моделей. // Наукові праці ДонНТУ. Серія: Інформатика, кібернетика та обчислювальна техніка, випуск 10. — http://www.nbuv.gov.ua/portal/natural/Npdntu/ikot/2009_10/09flppmm.pdf