
ABSTRACT
Content
- Purpose and tasks
- The relevance of the research topic
- The scientific novelty
- Expected practical results
- A review of research and development on the subject. The global level
- A review of research and development on the subject. The national level
- A review of research and development on the subject. The local level
- Increasing the efficiency of extracting knowledge from online sources on the basis of methods and Web Text Mining
- Approaches to data mining and knowledge from the Web
- Extracting meaningful information and
noise
filtering - Organization of extracting objects from specialized texts
- Suggested ways of improving algorithms for knowledge extraction
- Conclusion
- References
Purpose and tasks
The aim of this work is the development and analysis of algorithms for mining site content recovery and verification of knowledge in a given domain.
To achieve this goal, the following objectives:
- Analysis of existing approaches to the extraction of data and knowledge of the Web.
- Development of algorithms for extracting meaningful information and
noise
filtering. - Development of algorithms for extracting objects from text documents.
- Development of algorithms for pattern formation and verification of knowledge learned.
- Analysis of the effectiveness of the proposed algorithms.
The relevance of the research topic
The development of the Internet in the global information infrastructure has allowed ordinary users to be not only consumers of information but its creators and distributors. This has led to an avalanche growth and continuous replenishment randomly organized information network. The Internet contains a measurable set of knowledge and information, and such an abundance of often creates difficulties in finding the necessary information. All this leads to the need to use any special techniques to extract useful knowledge from the Internet. Of particular importance are intelligent software agents automatically extracting relevant information, the accuracy of which can beformally check or verify.
Developed so far approaches to verification of knowledge used primarily syntactic and statistical methods to check the integrity of the consistency and placed in a separate knowledge base, which leads to the inability of existing verification methods to cope with heterogeneous, unstructured and inconsistencies in the information provided on the Web.
On the Web, a wide range of data: text, graphics, audio, video. Since more traditional documents contained in the databasetext form, actually improving methods for extracting knowledge from text information. Text information on the Web can be unstructured in the form of free text, semi-structured in the form of HTML-pages or structured in the form of documents from the database.
A new direction in the methodology of data analysis – Web Mining can successfully serve these purposes. Web Mining is developing at the intersection of disciplines such as knowledge discovery in databases, efficient information retrieval, artificial intelligence, machine learning and processing natural languages. Destination Web Mining, called Web Content Mining, provides methods which are capable of site-based data discover new, previously unknown knowledge that can later be used in practice. In other words, the technology of Web Content Mining Data Mining uses technology for the analysis of unstructured, heterogeneous, and distributed on a large volume of information contained on Web-sites.
In this regard, the current task is the development of algorithms for extracting knowledge from distributed heterogeneous sources, the models and methods semantic verification of acquired knowledge, which will enable intelligent agents or programs to automatically ensure confidence in a certain context information provided by the system.
The scientific novelty
Algorithms for extracting knowledge from local and distributed sources formulaic training methods and semantic verification with using a modified ontology of subject areas.
Expected practical results
Algorithmic software can be used to build an intelligent system recovery, and verification of knowledge.
A review of research and development on the subject. The global level
Today, there are a lot of systems to analyze a text and Web content mining. The development of such systems are engaged as a small private company, a group of scientists and programmers, and computer industry giants.
For example, IBM is providing its development Intelligent Miner for Text [1], which is essentially a set of individual
utilities. Language Identification Tool – utility definition language – to automatically determine the language in which the document is made.
Categorisation Tool – utility classification – automatically classifying text to a certain category (input information on the training phase of
the operation of this tool can serve as a result of the following utilities – Clusterisation Tool). Clusterisation Tool – utility
clustering – partitioning a large set of documents into groups based on proximity of style, form, and various frequency characteristics
detected keywords. Feature Extraction Tool – define a new tool – detection of a new document key words (proper names, names,
abbreviations) based on a predetermined analysis dictionary before hand. Annotation Tool – utility detection point
texts and preparation
of abstracts – abstracts to the source.
Among the developments in the post-Soviet space is to provide a system GALAKTIKA-ZOOM and Medialogia
. The software packagecGALAKTIKA-ZOOM
is designed for analytical processing of large volumes of rapidly replenishing (up to tens of millions) of text documents, are connected in
unstructured and structured electronic databases [2].
The system Medialogia
does not provide for the transfer of the program to customers, making customer service online.
Medialogia
– a web-application, which is a powerful solution with sophisticated architecture and provides continuous processing
incoming information, structured data storage, calculation of analytical parameters, the analysis by user queries and storage of
settings and reports.
A review of research and development on the subject. The national level
In [3] developed a method of verification of ontological knowledge, which is to generate tree structures explanations for the automatic withdrawal of the hybrid knowledge-based information, which is extracted from distributed heterogeneous sources. It is proved that the verification of knowledge is reduced to the verification of multiple allegations presented in the form of triplets. To interpret the results verify the proposed method for the determination of equivalence of tree structures, which differs from the existing possibility of integration of semantics tree nodes and characterized by the use of several independent assessments of similarity of ontological objects.
A review of research and development on the subject. The local level
In [4] the basic approaches to the extraction of knowledge from distributed information resources: text mining and pre-structuring of information. The approaches and describes trends information space and the means of analysis. Provides a structure of knowledge extraction of information resources unstructured and structured information.
Proposed in [5] method uses the characteristics of the 11 Internet pages, including Google Page Rank, Rating Yandex, Alexa Trafic Rank, rating Delicious bookmarks and the number of links in Twitter last month. Between indicators searched and analysis of interdependencies. This determines the influence of individual characteristics and their teams on the overall rating of the Internet page. The method is implemented in R. The results of the analysis of the characteristics of 46 internet pages by the proposed method. A strong impact on the rating Delicious bookmarks party of two factors: the number of references to Twitter and internet traffic rating page.
Increasing the efficiency of extracting knowledge from online sources on the basis of methods and Web Text Mining
Approaches to data mining and knowledge from the Web
Active research in the field of work with semistructured information led to the emergence of a large number of alternative instruments used to create programs intermediary [6]. Suggested approaches to study the problem of extracting data from the Web using techniques borrowed from areas such as data processing of natural language, languages and grammars, machine learning, information retrieval, database and ontology. As a result, they provide a variety of opportunities so strict criteria for their comparison is not yet reached.
The main task of extracting data from the Web is: getting certain pieces of information (fields) of the specified HTML documents specified time. It is close to the problem of automatic clustering and consists in finding a decomposition of HTML-documents D {d1, … , dn} to the classes C1, … , Ck, documents that contain a similar structure.
Setting the display of application objects in terms of the multidimensional space is to determine the characteristics of the basis {ei},
forming a multi-dimensional space, and the method of decomposition of the document on that basis (ie, calculate the coordinates {wi}).
To determine the coordinates of the document {wi} in the space of basic signs {ei} different approaches. In particular,
in [7] offered an approach popular in the calculation of the balance of terms in the search enginesusing the vector model
of the documents. In this case: wi=tfi/(logN/ki), where tfi – is frequency of i-th feature,
ki – the number of documents in which it occurs, and N – the total number of the documents in question.
To assess the quality of clustering is proposed to use the entropy measure.On the basis of calculating the total entropy and entropy of
the authors of the cluster [8] placed the criterion of good
cluster which can be processed automatically.
Then introduced another measure that reflects the possibility of constructing a multi-level hierarchy of clusters.
There are a number of other approaches to the formalization of the problem extracting semistructured information from Internet sources. They are ranked, the logic tree or unranked first or higher order (typically second order) [9], [10], as well as the logic on graphs [11]. These methods are promising, actively developing areas of modern mathematical logic, which is currently actively formed. Effective implementation of these techniques requires the development of new ways to present and document storage a tree (and in the general case – graph) structures and query languages thereto, which requires a great effort in step development. From the point of view of ease of implementation, it was decided to use the standard tools of documents and query languages so on this group of methods is not considered.
In order to systematize the existing approaches can be used classification proposed in the [8], which identifies the following groups of methods and means of implementation: declarative languages, the use of HTML structures, systems, asking for processing natural language; based systems inductive reasoning, modeling tools, means based on the ontology. This classification is not strict and some tools can relate to more than one group.
Based on the analysis performed by the existing methods of extraction, one can conclude that the HTML page can hardly be processed by a conventional parse due to a number of reasons. Key among them is the fact that the developers of HTML-pagesen joy unrestricted freedom of the shortage of funds for parsing. The result is a variety of methods structuring data in a page, so the two are logically homogeneous data item can be formatted very differently,or even wrong, that is, parts of the code may not be identical to the grammar HTML (no closing tags is a common example).
Extracting meaningful information and noise
filtering
When extracting knowledge from a Web-content, the initial step is to get meaningful information from a particular source. To do this, set the type of document, and select algorithm depending on the structure of the data presentation.
By way of arranging the data in different types of documents can be divided into three types: unstructured, structured partially and structured [12]. Electronic documents are written in any form of natural language and contain unstructured data. An example of such a document could be an article with any theme (txt, doc, pdf). The semi-structured data contain electronic Web-documents of different extensions (php, aspx, jsp, htm, etc.), decorated in text format HTML, where they are described using special tags. Structured data contains an XML-documentsand databases [13]. They refer to this type due to the presence of specific tools. In the case of XML – is DTD (the preamble of the document, which defines the components and structure) and XML schema (XML language for describing the structure of the document) [13].
The main criteria of relevance of information include: the topicality, correctness, completeness and purity
representing its data.
The last criterion is the objective characteristic, as is responsible for a substantial part of the information [14]
and reflects its quality, noise signals (no data that do not bear the burden of meaning within a given subject).
Organization of extracting objects from specialized texts
In electronic commerce systems, document management companies have a large number of important text documents limited vocabulary (product specifications, components and raw materials, reports of breakages, polls, etc.).
For such texts easier to build algorithms that convert them to a standardized structured form. Standardized information easier to handle and can be used in various industrial purposes.
For example, the description of the manipulator Mouse: computer mouse Genius, model DX-7010, color Black, an optical sensor, a radio interface, 2 standard keys, scroll wheel click, Windows-compatible.
This text is to be converted to the form:
| Field | Value |
| Device type | mouse |
| Trademark | Genius |
| Model | DX-7010 |
| Sensor Type | optical |
| Interface | radio |
| Number of buttons | 2 standard keys |
| Color | Black |
| Compatibility | Windows |
Such texts combines simplified language, the rules for constructing simple sentences of natural language descriptions are almost always similar with each other in structure are most commonly used one and the same relatively small when compared with natural speech of words, very common abbreviations and acronyms. Therefore, the system is greatly simplified analysis of such texts.
Before you begin, the user module and the initial training of the template parsing for the subject areas of documents and text parsing rules using templates. Templates, such as PC peripherals to display frames of the following form:
| PC peripherals |
| Тип устройства |
| Trademark |
| Manufacturer |
| Compatibility |
| Interface |
| Color |
Slot values are accumulated in teaching. Manually compiled template, high accuracy and low efficiency of extractionnamed entities from text. Using this template, initially in a dialogue with the system, we get a training set for machinelearning.
If we consider a cluster containing multiple thematically similar documents, it often turns out to be close enough within the meaning of the proposals, including a proposal in which some frame recognized quite well, and the sentences in which the same frame is not recognized at all or partially recognized. This second group of sentences can be used to build templates for recognition current frame. To provide additional training set, you must select a sentence in which some found object frame, and then find a lot of suggestions of the cluster, similar to the original, but in which the desired frame not found. Proposals that contain patterns retrievable information, serve as centers for clusters of similar sentences in which these patterns were found.
In its work, the system detects the presence of retrieving data in a text fragment of an object (frame) and highlights the associated with the object information (frame slots and their values). In algorithms originally made word processing cluster using the available and pattern information of the object is extracted from the text. Next, the extracted information is searched in each sentence cluster in which failed to establish the existence of the object to retrieve and count the number of slots found.
When dealing with the subject area different from the treated before, but pretty close to it, the system can use the previously point of parsing rules, but it can not retrieve all objects or slots. To improve the accuracy of selection of proposals supposed to use algorithms based on the calculation of proximity proposals for the number of allocated slots in the cosine the angle between the proposals and mean ingfully measure TF×IDF words [15]. The cosine of the angle between the vector of the words of the proposal and the vector xwords of the sentence y, in which the parser detects the presence of an object is given by:
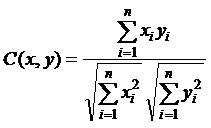
Suggested ways of improving algorithms for knowledge extraction
To simplify and automate the scaffolding and verification of knowledge extraction is proposed to use the ontology subject area. According to the initial training of the ontology module can generate a template-frames for a given subject documents. The correct slots to retrieve the values of the objects is controlled by means of a validating knowledge ontology. This knowledge is stored in the ontology, and can be replenished from distributed sources.
Conclusion
The analysis of existing approaches to data mining and knowledge from the Web, the stages retrieve relevant documents from the Web-pages and
noise
filtering. The algorithms for extracting objects from text documents on the basis of a generic method. The proposed algorithmic
software can be used in systems of mining Web-content.
This master’s work is not completed yet. Final completion: December 2013. The full text of the work and materials on the topic can be obtained from the author or his scientific adviser after this date.
References
- Intelligent Miner for Text (IBM). [Электронный ресурс]. – Режим доступа: http://www-3.ibm.com....
Галактика-Zoom
. [Электронный ресурс]. – Режим доступа: http://zoom3.galaktika.ru.- Головянко М. В. Методи і модель верифікації знань для інтелектуалізації Web-контенту; Автореф. дисс. канд. техн. наук. – Х., 2011. – 129 с.
- Бабин Д.В. Повышение эффективности извлечения знаний на основе интеллектуального анализа и структурирования информации/ Д.В. Бабин, С.М. Вороной, Е.В. Малащук//
Штучний інтелект
. – 3’ 2005. – С. 259-264. - Миргород В.С. Метод интеллектуального анализа интернет страниц/ В.С. Миргород, И.С. Личканенко, Д.М. Мазур, Р.А. Родригес Залепинос// Информатика и компьютерные технологии; VIII. – ДонНТУ. – 2012.
- Laender A.H.F., Ribeiro-Neto B.A., Juliana S.Teixeria. A brief survey of web data extraction tools. ACM SIGMOD Record 31(2), 2002. – pp. 84-93.
- Некрестьянов И. Обнаружение структурного подобия HTML-документов/ И. Некрестьянов, Е. Павлова. [Электронный ресурс]. СПГУ. – 2002. – С. 38-54. – Режим доступа: http://rcdl.ru/doc....
- Crescenzi V., Mecca G. Automatic Information Extraction from Large Websites// Journal of the ACM, Vol. 51, No. 5, September 2004. – pp. 731-779.
- Gottlob G., Koch C. Logic-based Web Information Extraction // SIGMOD Record, Vol. 33, No. 2, June 2004. – pp. 87-94].
- Courcelle B. The monadic second-order logic of graphs xvi: canonical graph decompositions//Logical Methods in Computer Science, Vol. 2, 2006, pp. 1-18.
- Logical methods in computer science[Электронный ресурс]. – Режим доступа: www.lmcs-online.org.
- Беленький А. Текстомайнинг. Извлечение информации из неструктурированных текстов. [Электронный ресурс] / А. Беленький // Журн.
КомпьютерПресс
. – 2008. № 10. Режим доступа: http://www.compress.ru/article.aspx?id=19605&iid=905 – 18.09.2011. - Chia-Hui Ch. A survey of Web Information Extraction [Text] / Ch. Chia-Hui, K. Mohammed, R.G. Moheb, F. S. Khaled. // IEEE Transactions on Knowledge and Data Engineering – 2006. № 18/10. – С. 1411-1428.
- Агеев М. С. Извлечение значимой информации из web-страниц для задач информационного поиска [Текст] / М. С. Агеев, И. В. Вершинников, Б. В. Добров // Интернет-математика 2005. Автоматическая обработка веб-данных. – М.:
Яndex
, 2005. – С. 283-301. - Hatzivassiloglou V., Klavans J., Holcombe L., Barzilay R., Min-Yen Kan, McKeown R. SIMFINDER: A Flexible Clustering Tool for Summarization. Proceedings of the NAACL Workshop on Automatic Summarization, 2001.