
РЕФЕРАТ ЗА ТЕМОЮ ВИПУСКНОЇ РОБОТИ
Зміст
- Мета та задачi
- Актуальність теми
- Передбачувана наукова новизна
- Плановані практичні результати
- Огляд досліджень і розробок за темою. Глобальний рівень
- Огляд досліджень і розробок за темою. Національний рівень
- Огляд досліджень і розробок за темою. Локальний рівень
- Підвищення ефективності вилучення знань з мережевих джерел на основі методів Web і Text Mining
- Підходи до витягання даних і знань з Web
- Витяг значимої інформації і фільтрація
шуму
- Організація системи вилучення об'єктів із спеціалізованих текстів
- Пропоновані напрямки вдосконалення алгоритмів вилучення знань
- Висновки
- Перелік посилань
Мета та задачi
Метою цієї роботи є розробка та дослідження алгоритмів інтелектуального аналізу вмісту сайтів для вилучення та верифікації знань у заданій предметній області.
Для досягнення поставленої мети необхідне рішення наступних задач:
- Аналіз існуючих підходів до вилучення даних та знань з Web.
- Розробка алгоритмів вилучення значущої інформації та фільтрації
шуму
. - Розробка алгоритмів витягання об’єктів з текстових документів.
- Розробка алгоритмів формування шаблонів та верифікації витягнутих знань.
- Аналіз ефективності запропонованих алгоритмів.
Актуальність теми
Розвиток Internet в глобальну інформаційну інфраструктуру дозволило звичайним користувачам бути не тільки споживачами інформації, але її творцями і розповсюджувачами. Це призвело до лавиноподібного зростання та постійного поповнення хаотично організованої інформації мережі. В Інтернеті міститься невимірне безліч знань та інформації, і така велика кількість часто створює складності при пошуку необхідної інформації. Все це призводить до необхідності використання якихось спеціальних технологій для вилучення корисних знань з мережі Інтернет.Особливу важливість набувають програмні інтелектуальні засоби автоматичного вилучення релевантної інформації, достовірність якої можнаформально перевірити або верифікувати.
Розроблені досі підходи до верифікації знань використовують переважно статистичні та синтаксичні методи перевірки цілісності і несуперечності, розміщених в окремій базі знань, що обумовлює нездатність існуючих методів верифікації впоратися з різнорідністю, неструктурованістю і суперечливістю інформації, представленої в Web.
У Web представлений широкий спектр даних: текст, графіка, аудіо, відео. Так як в документах традиційно більше міститься даних у текстовому вигляді, актуально вдосконалення методів вилучення знань з текстової інформації. Текстова інформація в Web може бути неструктурованою у вигляді вільного тексту, полуструктурованою у вигляді HTML-сторінок або структурованою у вигляді документів з БД.
Новий напрям у методології аналізу даних – Web Mining може успішно служити цим цілям. Web Mining розвивається на перетинітаких дисциплін як виявлення знань у базах даних, ефективний пошук інформації, штучний інтелект, машинне навчання і обробка природних мов. Напрямок Web Mining, зване Web Content Mining, охоплює методи, які здатні на основі даних сайту виявити нові, раніше невідомі знання, які в подальшому можна буде використовувати на практиці. Іншими словами, технологія Web Content Mining застосовує технологію Data Mining для аналізу неструктурованої, неоднорідної, розподіленої і значної за обсягом інформації, що міститься на Web-вузлах.
У зв’язку з цим актуальним є завдання розробки алгоритмів вилучення знань з розподілених різнорідних джерел, моделі і методів семантичної верифікації отриманих знань, які нададуть можливість інтелектуальним програмам або агентам автоматично переконуватися в достовірності в певному контексті наданої системою інформації.
Передбачувана наукова новизна
Алгоритми вилучення знань з локальних і розподілених джерел шаблонними методами навчання та їх семантичної верифікації за допомогою модифікованої онтології предметних областей.
Плановані практичні результати
Алгоритмічне забезпечення може використовуватися для побудови інтелектуальної системи вилучення та верифікації знань.
Огляд досліджень і розробок за темою. Глобальний рівень
На сьогоднішній день існує безліч систем аналізу текстового Web контенту і його інтелектуального аналізу. Розробкою таких систем займаються як невеликі приватні компанії, групи вчених і програмістів, так і гіганти комп’ютерної індустрії.
Так, IBM пропонує свою розробку Intelligent Miner for Text [1], яка, по суті, є набором окремих утиліт. Language Identification Tool – утиліта визначення мови – для автоматичного визначення мови, на якому складено документ. Categorisation Tool – утиліта класифікації – автоматичного віднесення тексту до деякої категорії (вхідною інформацією на навчальній фазі роботи цього інструменту може служити результат роботи наступної утиліти – Clusterisation Tool). Clusterisation Tool – утиліта кластеризації – розбиття великої множини документів на групи за близькостю стилю, форми, різних частотних характеристик виявляємих ключових слів. Feature Extraction Tool – утиліта визначення нового – виявлення в документі нових ключових слів (власні імена, назви, скорочення) на основі аналізу заданого заздалегідь словника. Annotation Tool – утиліта «виявлення змісту» текстів і складання рефератів – анотацій до вихідних текстів.
Серед розробок на пострадянському просторі варто виділити системи GALAKTIKA-ZOOM і «Медиалогия». Програмний комплекс GALAKTIKA-ZOOM призначено для аналітичної обробки великих масивів (до десятків мільйонів) текстових документів, що динамічно поповнюються, перебуваючих у підключаємих неструктурованих і структурованих електронних базах даних [2].
Система «Медиалогия» не передбачає передачі програми замовникам, виробляючи обслуговування клієнтів в онлайновому режимі. «Медиалогия» – це web-додаток, що представляє собою потужне рішення зі складною архітектурою і забезпечує безперервну обробку інформації, що надходить, структуроване зберігання даних, розрахунок аналітичних параметрів, проведення аналізу за запитами користувача і зберігання налаштувань і звітів.
Огляд досліджень і розробок за темою. Національний рівень
У роботі [3] розроблено метод верифікації онтологічних знань, який полягає в генерації деревовидних структур пояснення для автоматичного гібридного виведення знань на основі інформації, яка витягується з розподілених різнорідних джерел. Доведено, що верифікація знань зводиться до верифікації безлічі тверджень, представлених у вигляді триплетів. Для інтерпретації результатів верифікації запропонован метод визначення еквівалентності деревовидних структур, який відрізняється від існуючих можливістю обліку семантики вузлів дерева і характеризується використанням декількох незалежних оцінок подібності онтологічних об’єктів.
Огляд досліджень і розробок за темою. Локальний рівень
У [4] розглядаються основні підходи до вилучення знань з розподілених інформаційних ресурсів:інтелектуальний аналіз текстів і попереднє структурування інформації. Розглядаються підходи і описуються тенденції розвитку інформаційного простору і засобів його аналізу. Пропонується структура системи здобуття знань з інформаційних ресурсів з неструктурованою і структурованою інформацією.
Запропонований у [5] метод використовує 11 характеристик інтернет сторінок, у тому числі Google Page Rank, рейтинг Yandex, Alexa Trafic Rank, рейтинг закладок Delicious і кількість посилань у Twitter за останній місяць. Між показниками проводиться пошук та аналіз взаємозалежностей. При цьому визначається вплив окремих характеристик і їх груп на загальний рейтинг інтернет сторінки. Метод реалізований на мові R. Наведені результати аналізу характеристик 46 інтернет сторінок запропонованим методом. Виявлено сильний вплив на рейтинг закладок Delicious групою двох показників: кількістю посилань в Twitter і рейтингом відвідуваності інтернет сторінки.
Підвищення ефективності вилучення знань з мережевих джерел на основі методів Web і Text Mining
Підходи до витягання даних і знань з Web
Активні дослідження в області роботи зі слабоструктурованою інформацією призвели до появи великої кількості альтернативних інструментів, що використовуються для створення програм-посередників [6]. Пропоновані підходи в дослідженні проблеми вилучення даних з Web використовують методи, запозичені з таких областей як: обробка даних на природній мові, мови та граматики, машинне самонавчання, інформаційний пошук, бази даних і онтологія. В результаті, вони надають самі різні можливості, тому суворих критеріїв для їх порівняння поки не вироблено.
Основним завданням отримання даних з Web є: отримання певних фрагментів інформації (поля) із зазначених HTML документів в зазначений час. Вона близька до задачі автоматичної кластеризації і полягає в пошуку розкладання безлічі HTML-документів D {d1, … , dn} на класи C1, … , Ck, які містять документи зі схожою структурою.
Завдання відображення прикладних об’єктів в точки багатовимірного простору полягає у визначенні базису ознак {ei},
що формують багатовимірний простір, і методу розкладання документа з цього базису (тобто обчислення координат {wi}).
Для визначення координат документа {wi} в просторі базисних ознак {ei} використовуються різні підходи.
Зокрема, в роботі [7] пропонується використовувати підхід, популярний при обчисленні ваг термів в пошукових системах,
що використовують векторну модель подання документів. При цьому: wi=tfi/(logN/ki), де tfi – це
частота зустрічаємості i-ї ознаки, ki – кількість документів, в яких він зустрічається, а N – загальна кількість
розглянутих документів. Для оцінки якості кластеризації пропонується використовувати ентропійну міру. На підставі обчислення загальної ентропії
та ентропії кластера автори роботи [8] вводять критерій хорошого
кластера,
який може бути оброблений автоматично. Потім вводиться ще одна міра, що відображає можливість побудови багаторівневої ієрархії кластерів.
Існує цілий ряд інших підходів до формалізації задачі вилучення слабоструктурованої інформації з Інтернет-джерел.У них використовується логіка ранжируваних або неранжируванних дерев першого або вищого порядку (як правило, другого порядку) [9], [10], а також логіка на графах [11]. Ці методи відносяться до перспективного напрямку сучасної математичної логіки, який в даний час активно формується і розвивається. Ефективна реалізація таких методів вимагає розробки нових способів подання та зберігання документів у вигляді деревовидних (а в самому загальному випадку – графових) структур, а також мов запитів до них, що вимагає великих зусиль на етапі розробки. З точки зору простоти реалізації було вирішено використовувати стандартні засоби представлення документів і мови запитів, тому далі ця група методів не розглядається.
Для систематизації існуючих підходів можна використовувати класифікацію, запропоновану в роботі [8], яка виділяє наступні групи методів і засобів їх реалізації: декларативні мови; використання HTML структури; системи, що здійснюють обробку даних на природній мові; системи на основі індуктивних логічних міркувань; засоби моделювання; засоби, засновані на онтології. Ця класифікація не сувора і деякі інструменти можуть відноситися відразу до декількох груп.
Виходячи з виконаного аналізу існуючих методів вилучення, можна зробити висновок, що сторінки HTML навряд чи можуть бути оброблені за допомогою звичайного граматичного розбору, зважаючи на низку причин. Основні з них полягають у тому, що розробники HTML-сторінок користуються необмеженою свободою при нестачі засобів синтаксичного контролю. Наслідком цього є різноманітність способів структурування даних у сторінці, так що два логічно однорідних елемента даних можуть бути форматовані абсолютно різним чином, або навіть містити помилки, тобто частини коду можуть не відповідати граматиці HTML (відсутність закриваючих тегів є поширеним прикладом).
Витяг значимої інформації і фільтрація шуму
При витяганні знань з Web-контенту, на початковому етапі необхідно отримати значиму інформацію з певного джерела. Для цього необхідно встановити тип документа і вибрати алгоритм роботи залежно структури даних його подання.
За способом упорядкування даних у різних типах документів їх можна розділити на три види: неструктуровані, частково-структурованіі структуровані [12]. Електронні документи складені в довільній формі на природній мові і містять неструктуровані дані. Прикладом такого документа може бути стаття з довільною тематикою (txt, doc, pdf). Частково-структуровані дані містять електронні Web-документи різних розширень (php, aspx, jsp, htm и т.д.), оформлені у текстовому форматі HTML, де вони описуються за допомогою спеціальних тегів. Cтруктуровані дані містять ХML-документи та бази даних [13]. Їх відносять до даного типу завдяки наявності специфічних інструментів. У разі XML – це DTD (преамбула документа, де визначаються його компоненти і структура) і XML schema (мова опису структури XML документа) [13].
До основних критеріїв значимості інформації відносять: актуальність, достовірність, повноту і чистоту
даних, що її представляють.
Останній критерій є об’єктивною характеристикою, так як відповідає за змістовну частину інформації [14] і
відображає її якість, сигналізує про зашумленності (відсутні дані, які не несуть змістовного навантаження в рамках заданої тематики).
На мал. 1. представлені основні етапи аналізу web-сторінок при витяганні значущою текстової інформації та фільтрації шуму
.
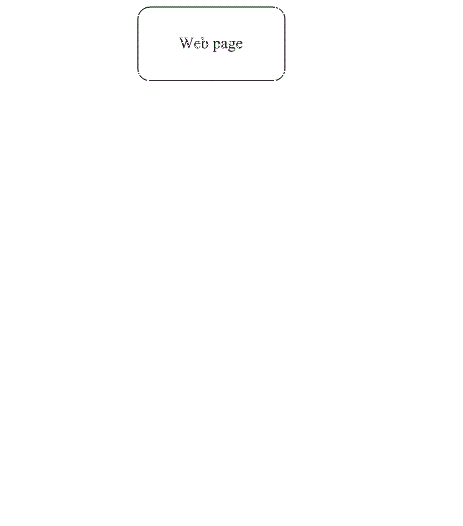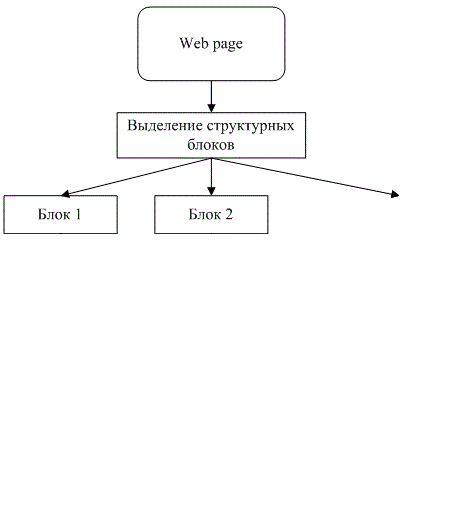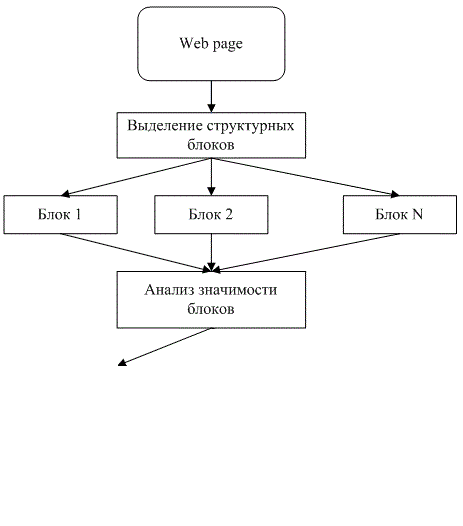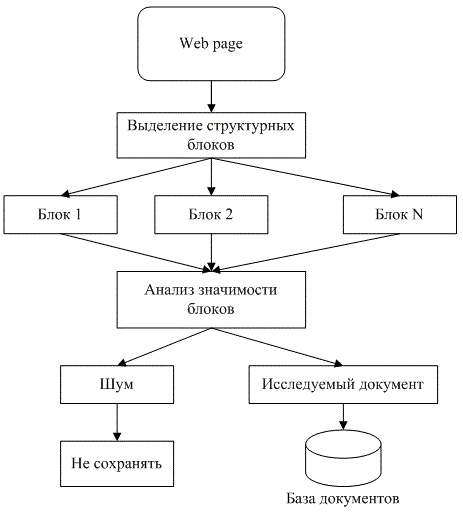
Малюнок 1 – Етапи вилучення значущої інформації
(анімація: 21 кадр, 8 циклів повторення, 137,4 кілобайт)
Організація системи вилучення об'єктів із спеціалізованих текстів
У системах електронної торгівлі, документообігу підприємств є велика кількість значущих текстових документів з обмеженою лексикою (характеристики продукції, комплектуючих та сировини, звіти про поломки, результати опитувань і т.д.).
Для таких текстів спрощується створення алгоритмів перетворення їх до стандартизованого структурованого вигляду. Стандартизовану інформацію простіше обробляти і можна використовувати в різних виробничих цілях.
Наприклад, опис маніпулятора миша: комп’ютерна мишка Genius, модель DX-7010, колір Black, датчик оптичний, радіо інтерфейс, 2 стандартні клавіші, колесо прокручування з функцією натискання, Windows-сумісна.
Данный текст требуется преобразовать к виду:
| Поле | Значення |
| Тип пристрою | маніпулятор миша |
| Торгівельна марка | Genius |
| Модель | DX-7010 |
| Тип датчика | оптичний |
| Інтерфейс | радіо |
| Кількість кнопок | 2 стандартні клавіші |
| Колір | Black |
| Сумісність | Windows |
Такі тексти об’єднує спрощена мова, правила побудови простіше пропозицій природної мови, описи практично завжди схожіо дин з одним за структурою, найчастіше використовуються один і той же відносно невеликий, якщо порівнювати з природною промовою, набір слів, дуже часто зустрічаються абревіатури та скорочення. Тому істотно спрощується система розбору таких текстів.
У запропонованій системі будемо використовувати шаблонний метод з навчанням. Склад системи зображений на малюнку.
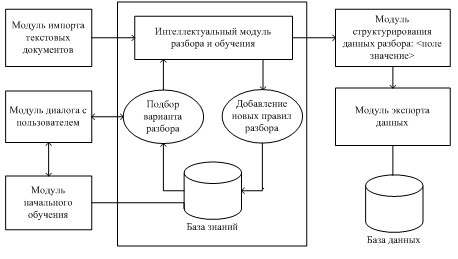
Малюнок 2 – Структура системи вилучення об’єктів із спеціалізованих текстів
Перед початком роботи користувачем і модулем початкового навчання формуються шаблони розбору для предметних областей системи документів і правила розбору текстів за допомогою шаблонів. Шаблони, наприклад, для периферійних пристроїв ПК представляються фреймом наступного виду:
| Периферійні пристрої ПК |
| Тип пристрою |
| Торгівельна марка |
| Виробник |
| Сумісність |
| Інтерфейс |
| Колір |
Значення слотів накопичуються при навчанні. Складений вручну шаблон, володіє високою точністю і низькою повнотою для вилучення іменованих сутностей з тексту. Застосовуючи цей шаблон, на початковому етапі в режимі діалогу з системою, отримуємо навчальну множину для машинного навчання.
Якщо розглянути кластер, що поєднує кілька тематично близьких документів, то в ньому часто виявляється достатня кількість близьких за змістом реченнь, які включають як речення, в яких деякий фрейм розпізнано цілком успішно, так і речення, в яких цей же фрейм не розпізнано зовсім або розпізнаний частково. Цю другу групу речень можна використовувати для нарощування шаблонів для розпізнавання даного кадру. Для забезпечення додаткової навчальної множини, необхідно виділити пропозицію, в якої знайдено деякий фрейм об’єкту,а потім знайти безліч речень кластера, схожих на вихідне, але в яких потрібний фрейм не знайдений. Речення, що містять шаблони витягуваної інформації, служать центрами для кластерів схожих речень, в яких такі шаблони не виявлені.
При своїй роботі система вилучення даних визначає наявність в текстовому фрагменті деякого об’єкта (фрейму) і виділяє пов’язану з цим об’єктом інформацію (слоти фрейму та їх значення). В алгоритмах спочатку проводиться обробка текстів кластера за допомогою наявного шаблону і витягується інформація про об’єкт з тексту. Далі проводиться пошук витягнутої інформації в кожному реченні кластера, в якому не вдалося встановити наявність витягуваного об’єкта і підраховується кількість знайдених слотів.
При роботі з предметною областю, відмінною від оброблюваної до цього, але досить близькою до неї, система може використовувати раніше знайдені правила розбору, однак при цьому можуть вилучатись не всі об’єкти або слоти. Для підвищення точності відбору речень передбачається використовувати алгоритми, засновані на обчисленні міри близькості речень за кількістю виділених слотів, по косинусу кута між пропозиціями і за значенням міри TF×IDF слова [15]. Косинус кута між вектором слів даної пропозиції x і вектором слів речення y, в якому аналізатор виявив наявність деякого об’єкту, обчислюється за формулою:
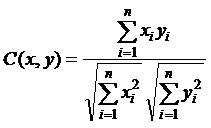
Пропоновані напрямки вдосконалення алгоритмів вилучення знань
Для спрощення та автоматизації процедури формування шаблонів та верифікації витягнутих знань пропонується використовувати онтологію предметної області. За онтологією модуль початкового навчання може формувати шаблони-фрейми для заданої тематики документів. Правильність вилучення значень слотів для об’єктів контролюється за допомогою верифікуючих знань онтології. Ці знання зберігаються в онтології і можуть поповнюватися з розподілених джерел.
Висновки
Проведено аналіз існуючих підходів до вилучення даних та знань з Web, розглянуті етапи вилучення значущих документів з Web-сторінок
і фільтрація шуму
. Розроблено алгоритми вилучення об’єктів з текстових документів на основі шаблонного методу. Пропоноване
алгоритмічне забезпечення може використовуватися в системах інтелектуального аналізу Web-контенту.
При написанні цього реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2013 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Intelligent Miner for Text (IBM). [Электронный ресурс]. – Режим доступа: http://www-3.ibm.com....
Галактика-Zoom
. [Электронный ресурс]. – Режим доступа: http://zoom3.galaktika.ru.- Головянко М. В. Методи і модель верифікації знань для інтелектуалізації Web-контенту; Автореф. дисс. канд. техн. наук. – Х., 2011. – 129 с.
- Бабин Д.В. Повышение эффективности извлечения знаний на основе интеллектуального анализа и структурирования информации/ Д.В. Бабин, С.М. Вороной, Е.В. Малащук//
Штучний інтелект
. – 3’ 2005. – С. 259-264. - Миргород В.С. Метод интеллектуального анализа интернет страниц/ В.С. Миргород, И.С. Личканенко, Д.М. Мазур, Р.А. Родригес Залепинос// Информатика и компьютерные технологии; VIII. – ДонНТУ. – 2012.
- Laender A.H.F., Ribeiro-Neto B.A., Juliana S.Teixeria. A brief survey of web data extraction tools. ACM SIGMOD Record 31(2), 2002. – pp. 84-93.
- Некрестьянов И. Обнаружение структурного подобия HTML-документов/ И. Некрестьянов, Е. Павлова. [Электронный ресурс]. СПГУ. – 2002. – С. 38-54. – Режим доступа: http://rcdl.ru/doc....
- Crescenzi V., Mecca G. Automatic Information Extraction from Large Websites// Journal of the ACM, Vol. 51, No. 5, September 2004. – pp. 731-779.
- Gottlob G., Koch C. Logic-based Web Information Extraction // SIGMOD Record, Vol. 33, No. 2, June 2004. – pp. 87-94].
- Courcelle B. The monadic second-order logic of graphs xvi: canonical graph decompositions//Logical Methods in Computer Science, Vol. 2, 2006, pp. 1-18.
- Logical methods in computer science[Электронный ресурс]. – Режим доступа: www.lmcs-online.org.
- Беленький А. Текстомайнинг. Извлечение информации из неструктурированных текстов. [Электронный ресурс] / А. Беленький // Журн.
КомпьютерПресс
. – 2008. № 10. Режим доступа: http://www.compress.ru/article.aspx?id=19605&iid=905 – 18.09.2011. - Chia-Hui Ch. A survey of Web Information Extraction [Text] / Ch. Chia-Hui, K. Mohammed, R.G. Moheb, F. S. Khaled. // IEEE Transactions on Knowledge and Data Engineering – 2006. № 18/10. – С. 1411-1428.
- Агеев М. С. Извлечение значимой информации из web-страниц для задач информационного поиска [Текст] / М. С. Агеев, И. В. Вершинников, Б. В. Добров // Интернет-математика 2005. Автоматическая обработка веб-данных. – М.:
Яndex
, 2005. – С. 283-301. - Hatzivassiloglou V., Klavans J., Holcombe L., Barzilay R., Min-Yen Kan, McKeown R. SIMFINDER: A Flexible Clustering Tool for Summarization. Proceedings of the NAACL Workshop on Automatic Summarization, 2001.