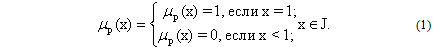Аннотация
Гиль М. В., Фонотов А. М. Методика отбора персонала на вакансию на основе нечетких показателей.
Задачей статьи является разработка концепции оптимизации отбора кандидатов из ограниченного количества претендентов на вакантную должность для собеседования с работодателем с помощью методов нечёткой логики, определение «критериев важности» для каждого атрибута анкеты соискателей, кодирование информации из анкет соискателей, формирование списка кандидатов» с помощью методов Data Mining.
Ключевые слова: оптимизация отбора кандидатов из ограниченного числа претендентов, методы нечеткой логики, методы Data Mining.
Постановка проблемы
Сегодня очень актуальной является проблема поиска работодателями квалифицированных кадров для повышения эффективности работы предприятия. Для решения этой проблемы нужно отобрать ограниченное число «лучших» претендентов на собеседование с работодателем [1]. Для обработки большого объёма данных целесообразно использовать методы интеллектуального анализа данных. Необходимо разработать систему отбора кандидатов, которая составит рейтинг претендентов. Исходные данные для расчета рейтинга – данные анкет соискателей.
Цель статьи – разработка концепции построения интеллектуальной системы отбора ограниченного числа претендентов на собеседование с работодателем.
Исследования
Известны способы решения задачи отбора претендентов с использованием нейронных сетей [2] и дерева решений [3]. Недостатком данных методов является то, что они не позволяют в полной мере оценить профессиональные качества соискателей в соответствии с требованиями работодателей. Они дают возможность анализировать только данные из анкет соискателей. Поэтому, для решения задачи отбора претендентов на вакантную должность будем использовать методы нечеткой логики, которые формализируют знания экспертов при формировании требований [4].
Предполагается использование следующих данных в качестве лингвистических переменных для формирования рейтинга претендентов с помощью нечеткого вывода:
Вид деятельности (анализируется на этапе выборки кандидатов из базы данных агентства); дата рождения (на основании которой будет рассчитан возраст); общий трудовой стаж работы; стаж работы на вакантной должности; пол; образование; специальность и квалификация; занимаемые должности; причины увольнения; наличие опыта работы на руководящих должностях; опыт работы с компьютером; языковые навыки и т.д.
Возраст (рассчитывается на основании даты рождения):
- От 18 до 24 лет: юный;
- От 22 до 29 лет: молодой;
- От 27 до 39 лет: средний;
- От 36 до 54 лет: выше среднего;
- От 50 до 65 лет: старческий;
- Больше 60 лет: преклонный.
На рисунке представлен вид функции принадлежности для возраста.
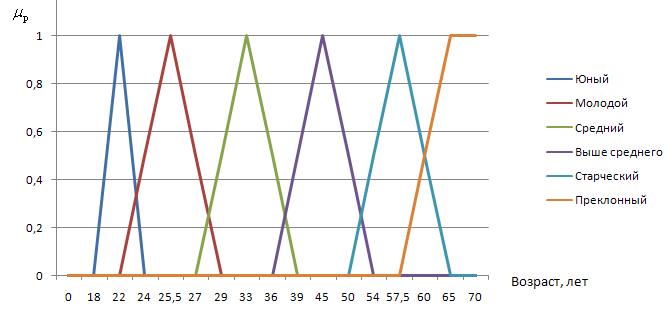
Рисунок 1 – График функции принадлежности для лингвистической переменной «Возраст»
Аналогичным образом можно представить остальные лингвистические переменные.
Общий трудовой стаж работы (в годах):
- [0; 3]: начальный;
- [2; 6]: небольшой;
- [5; 10]: средний;
- [8; 20]: высокий;
- >=15: очень высокий.
Стаж работы на вакантной должности (в годах):
- [0; 3]: начальный;
- [2; 6]: небольшой;
- [5; 10]: средний;
- [8; 20]: высокий;
- >=15: очень высокий.
Наличие опыта работы на руководящих должностях:
- От 0 до 1: отсутствует;
- От 0,5 до 3 лет: небольшой;
- Свыше 2-х лет: большой.
Пол:
Образование:
- Среднее;
- Среднее специальное;
- Неполное высшее;
- Высшее.
Специальность:
- Соответствует требуемой;
- Не соответствует требуемой.
Квалификация:
- Соответствует требуемой.
- Не соответствует требуемой.
Занимаемые должности:
- Хотя бы одна соответствует требуемой.
- Ни одна не соответствует требуемой.
Причины увольнения:
- По инициативе работника;
- По инициативе собственника (администрации) предприятия;
- По обоюдному согласию работника и администрации;
- Другое.
Опыт работы с компьютером:
Языковые и другие навыки:
При составлении списка требований работодателю необходимо задать значение для каждого навыка. При этом должна быть возможность задавать неограниченное количество требований, с возможностью редактирования перечня возможных навыков.
Пример базы правил для общих требований к претенденту:
d1: "Если кандидат имеет требуемые квалификацию, образование и опыт работы, то он — удовлетворяющий (отвечающий требованиям)";
d2: "Если он вдобавок к вышеописанным требованиям имеет опыт работы на занимаемой должности, то он — более чем удовлетворяющий";
d3: "Если он дополнительно к условиям d2 имеет высокий стаж работы на занимаемой должности, то он — безупречный";
d4: "Если он имеет все оговоренное в d3, но опыт работы с компьютером средний, то он — очень удовлетворяющий;
d5: "Если кандидат имеет необходимую квалификацию, имеет опыт работы на требуемой должности, но не имеет высшего образования, он все же будет удовлетворяющим";
d6: "Если он не имеет квалификации и не имеет опыта работы на занимаемой должности, то он — неудовлетворяющий".
Анализ приведенных информационных фрагментов позволяет выявить шесть критериев, используемых для принятия решения:
Х1 — квалификация; Х2 — образование; Х3, — опыт работы; Х4, — опыт работы с компьютером; Х5 — опыт работы на требуемой должности, Y— удовлетворительность
Для формулирования правил следует определить возможные значения лингвистических переменных Xi и Y, которые будут использоваться для оценки кандидатов:
d1: "Если Х1 = ПОДХОДЯЩЯЯ и X2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ. то Y = УДОВЛЕТВОРЯЮЩИЙ";
d2: "Если Х1 = ПОДХОДЯЩАЯ и X2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X4 = СПОСОБЕН, то Y = БОЛЕЕ ЧЕМ УДОВЛЕТВОРЯЮЩИЙ";
d3: "Если Х1 = ПОДХОДЯЩАЯ и Х2 = ВЫСШЕЕ, и X3 = ДОСТАТОЧНЫЙ, и Х4 = СПОСОБЕН, и X5 = ОБЛАДАЕТ, то Y = БЕЗУПРЕЧНЫЙ";
d4: "Если Х1 = ПОДХОДЯЩАЯ и Х2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X4 = ОБЛАДАЕТ, то Y = ОЧЕНЬ УДОВЛЕТВОРЯЮЩИЙ";
d5: "Если Х1 = ПОДХОДЯЩАЯ и X2 = НЕ ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X5 = ОБЛАДАЕТ, то Y = УДОВЛЕТВОРЯЮЩИЙ";
d6: "Если Х1 = НЕ ИМЕЕТ и Х3 = НЕДОСТАТОЧНЫЙ, то Y = НЕУДОВЛЕТВОРЯЮЩИЙ".
Переменная Y задана на множестве J = {0; 0,1; 0,2; ...; 1}.
Значения переменной Y заданы с помощью следующих функций принадлежности:
S = УДОВЛЕТВОРЯЮЩИЙ определено как S(х) = х, х Є J;
MS = БОЛЕЕ ЧЕМ УДОВЛЕТВОРЯЮЩИЙ — как MS(x)=sqrt(x); x Є J;
P = БЕЗУПРЕЧНЫЙ – как:
VS = ОЧЕНЬ УДОВЛЕТВОРЯЮЩИЙ — как VS(x) = х2, x Є J,
US = НЕУДОВЛЕТВОРЯЮЩИЙ — как VS(x) = 1 - х, х Є J.
С учетом введенных обозначений правила d1, ...,d6 принимают вид:
d1 : “Если Х= А и В, и С, то Y =S”;
d2: "Если Х= А и В, и С, и D, то Y = MS";
d3: “Если X= А и В, и С, и D, и E, то Y = P”;
d4: “Если X = А и B, и С, и Е, то Y = VS”;
d5: “Если X = A, и не В, и С, и E, то Y = S”;
d6: “Если Х = не A и не С, то Y = US”.
Каждому правилу можно присвоить приоритет путём экспертного назначения весов – «критериев важности» в виде числового значения от 0 до 1.
На основании составленной базы правил можно сформировать рейтинг претендентов, с помощью методов нечёткого вывода.
Выводы
В данной статье описана концепция системы предварительного отбора кандидатов на основе методов интеллектуального анализа данных с использованием нечеткой логики. Использование нечетких показателей и нечёткого вывода позволит учесть все требования, предъявляемые работодателями, и отобрать лучших кандидатов на собеседование.
Список использованной литературы
1. Гиль М.В., Фонотов А.М., Разработка системы предварительного отбора кандидатов на собеседование на основе методов интеллектуального анализа данных, научно-технический журнал ВАК Украины «Искусственный интеллект» № 2 – 2013.
2. Т.В. Азарнова, И.Н. Терновых, Применение нейросетей в процессе подбора персонала, Вестник ВГУ, серия: системный анализ и информационные технологии. 2009. № 2.
3. Qasem A. Al-Radaideh, Eman Al Nagi, Using Data Mining Techniques to Build a Classification Model for Predicting Employees Performance, (IJACSA) International Journal of Advanced Computer Science and Applications, № 3, № 2, 2012.
4. F. Herrera, E. Lopez, C. Mendana and M.A., Rodriguez, A linguistic decision model for personnel management solved with a linguistic biobjective genetic algorithm, Fuzzy Sets and Systems, 2001, № 118, Issue 1, pp. 47-64.