Аннотация
В этой работе мы предлагаем новый подход к оценке претендентов на вакансии в онлайн-системе подбора персонала с использованием алгоритмов машинного обучения для решения проблемы расчета рейтинга кандидата и проведения семантических методов сопоставления. Предлагаемый подход реализован в виде прототипа системы, функциональность которой продемонстрирована и оценена реальными наборами сценариев. Предлагаемая система извлекает набор объективных критериев из профиля LinkedIn кандидата, и сравнивает их семантически с предъявляемыми требованиями. Он также выводит их личностные характеристики на основе лингвистического анализа их блога. Наша система постоянно сравнивалась с рекрутерами, ее можно использовать для автоматизации расчета рейтинга кандидатов и изучения личностных характеристик.
Ключевые слова: элетронный найм, изучение личностных характеристик, системы поддержки принятия решений, интеллектуальные методы анализа данных.
1 Введение
В последние годы все большее число людей используют интернет для поиска работы и карьерного роста в то время как многие компании применяют интернет-системы управления знаниями, чтобы нанимать работников, используя преимущества всемирной сети интернет [1]. Информационные системы, используемые для поддержки этих задач называют системами электронного найма, они автоматизируют процесс публикации вакансий и получения заявителем резюме, что позволяет кадровым агентствам охватить очень широкую аудитории за небольшую плату. В то же время эта ситуация может также привести к тому, что кадровые агентства вынуждены выделять резюме кандидатов для оценивания вручную и определять соответствие заявленных позиций с имеющимися. Автоматизация процесса анализа резюме кандидатов, позволяет определить те, которые лучше соответствуют требованиям к данной должности, что может дать значительное усиление с точки зрения эффективности. Так, например, показательно, что SAT Telekom India, сэкономил 44% затрат и снизил среднее время, необходимое для заполнения вакансий, от 70 до 37 дней [2] после развертывания системы электронного найма.
Несколько систем электронного найма были предложены с целью ускорения процесса набора персонала, что привело к улучшению общего пользовательского опыта. Система E-Gen [3] выполняет задачи анализа и рубрикации неструктурированных предложений работы (т.е. в виде неструктурированных текстовых документов), а также анализ и актуальность рейтинга кандидатов. В отличие от свободного текстового описания, использование общего «языка» в виде набора контролируемых словарей для описания деталей вакансии облегчает обмен между всеми заинтересованными сторонами и открыло бы возможности автоматизации различных задач в этом процессе [4]. Еще одно преимущество от наличия связи с термами из контролируемого словаря является то, что условия могут быть объединены с базовыми знаниями о промышленной области. Порталы для поиска работы могли бы предложить возможность семантического соответствия, которая будет рассчитывать семантическое сходство между вакансиями и резюме кандидатов на основе базовых знаний о том, как различные термины связаны между собой. Например, если у кандидата имеются навыки программирования на языке Java, необходимые для определенной работы и есть опыт в Delphi, алгоритм сопоставления будет рассматривать профиль этого человека как более подходящий, чем тот, у которого имеется навык SQL, так как Delphi и Java более тесно связаны, чем SQL и Java. Такой подход позволяет сравнивать требования к должностям и профили кандидатов с использованием подготовленных знаний, а не просто полагаться на наличие ключевых слов, как делают традиционные поисковые системы.
Общая технология [5] применяется семантическими веб-технологиями в области управления персоналом, в то время как HR-XML может отчасти служить дл "стандартизированного" представления профессиональных качеств [6]. В этой технологии личностные характеристики кандидата, определяемые через онлайн анкету, которая заполняется кандидатом, рассматриваются при приеме на работу. Для того, чтобы определять соответствие кандидатов с должностями в этих системах обычно сочетают методы классических IR систем и рекомендательных, такие как значимость обратной связи [3], семантические соответствия в найденной работе и поставленных задачах [7], анализ иерархий [8,9] и НЛП технология, используемая для автоматического представления резюме на стандартном языке моделирования [10]. Эти методы, хотя и полезны, ухудшаются из-за расхождения, связанного с несовместимостью форматов резюме, структуры и контекстной информации. Кроме того подходы, которые включают онтологическую информацию для определения степени соответствия кандидата, имеют ряд значительных проблем, касающихся развития необходимой онтологической структуры и объединения. Эта проблема возникает даже при попытке повторного использования доступных онтологий (онтология исследования через оценку интеграции онтологии и слияния), задача, которая требует значительной ручной работы [11]. Более того, эти методы не в состоянии оценить некоторые вторичные характеристики, связанные с резюме, такие как стиль и согласованность, которые очень важны в оценке резюме.
Такие подходы пытаются сопоставить термины, встречающиеся в описаниях резюме на должностные позиции. В этой работе предлагаемый подход адаптирован в том смысле, что семантическое соответствие кандидата в первую очередь касается навыков, которые обозначены в соответствующем описании в профиле LinkedIn. Навыки кандидата семантически связываются с эквивалентными понятиями из должностных инструкций, как указано у рекрутера, который формирует список необходимых должностных навыков, используя предопределенные иерархии ИТ-навыков.
Система, описанная в этой работе, пытается решить проблему рейтинга кандидатов, применяя набор алгоритмов обучения с учителем в сочетании с навыками семантического механизм сопоставления, для автоматизированного электронного набора. Это интегрированная, ориентированная на компанию система электронного найма, которая автоматизирует предварительный отбор кандидатов и процесс ранжирования. Оценка кандидата основана на заранее определенном наборе объективных критериев, которые непосредственно извлекаются из профиля LinkedIn кандидата. Более того, личностные характеристики кандидата, которые автоматически извлекаются из его социального присутствия [12], учитываются при его оценке. Наша цель заключается в ограничении и интервьюировании на фоне рассмотрения кандидатов исключительно первых кандидатов, отобранных из системы, с тем, чтобы повысить эффективность процесса набора персонала. Система разработана с целью интеграции с инфраструктурой фирм для управления персоналом, и оказания помощи в принятии решений, а не замены рекрутеров в процессе принятия решений.
2 Обзор системы
В этой работе, мы внедрили интегрированную ориентированную на компании систему электронного найма, которая автоматизирует оценку кандидата и процесс предварительного отбора. Ее цель заключается в расчете актуальных оценок кандидатов, которые отражают, насколько хорошо их профиль соответствует требованиям к должности. В этом разделе мы представляем обзор архитектуры предлагаемой системы и схемы рейтинга кандидатов.
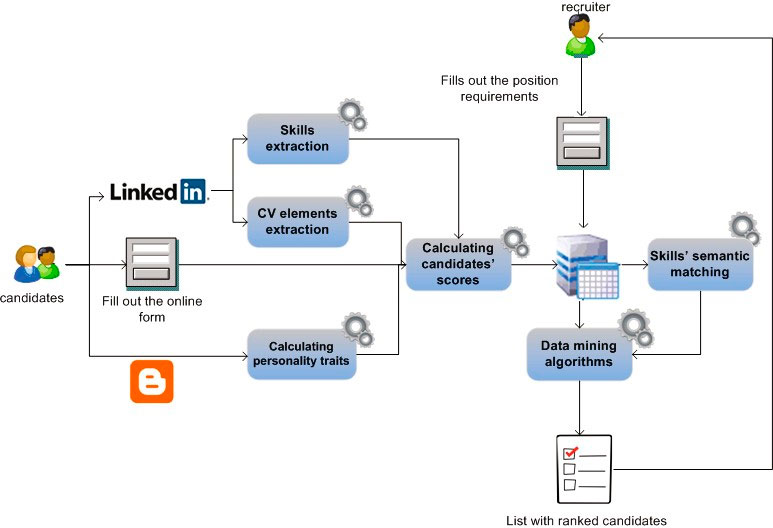
Рисунок 1 – Архитектура системы
2.1 Архитектура и реализация
Предлагаемая система электронного найма реализует автоматизированный расчет рейтинга кандидатов на основе набора надежных критериев, которые будет легко для компаний интегрировать с существующей инфраструктурой кадров. В этом исследовании мы ориентируемся на 5 дополнительных критериев отбора, а именно: образование (в годах формальной академической подготовки), опыт работы (в месяцах соответствующего опыта), лояльность (среднее число лет, проведенных за работой), экстраверсии и навыки. Архитектура системы, которая показана на рисунке 1, состоит из следующих компонентов:
– Модуль поиска вакансий: Реализует формы ввода, которые позволяют кандидатам подать заявку на должность.
– Модуль изучения личностных характеристик: Если у кандидата имеется блог, то лингвистический анализ применяется с помощью функции, отражающей личность автора.
– Семантическое соответствие: Рассчитывает семантическое расстояние между навыками и опытом работы кандидата, извлеченными из соответствующего профиля LinkedIn, и требованиями к должности.
– Модуль классификации кандидатов: Объединяет выбранные кандидатом критерии для получения актуальных оценок кандидата согласно выбранной должности. Функция классификация определяется путем применения обучающих алгоритмов.
Предлагаемая система электронного найма была полностью реализована в виде веб-приложения в среде разработки Microsoft.NET. Претендентам на рабочие места предоставляется возможность аутентификации с использованием своих учетных данных LinkedIn, чтобы подать заявку на одно или несколько доступных рабочих мест. Это позволяет системе автоматически извлекать критерии отбора необходимые для предварительного отбора кандидатов из их профилей LinkedIn, упорядочивая пользовательские навыки. В рамках этого процесса получения работы, кандидатам предлагается указать URI их личного блога. Это позволяет нашей системе синдицировать содержание блога и рассчитывать экстраверсию значений личностных характеристик, представленных в разделе 2.3.
На стороне рекрутера, система после аутентификации обеспечивает доступ с правами на размещение новых рабочих мест и оценку соискателей. В меню «ранг кандидатов», рекрутеру предложен список всех имеющихся рабочих мест и кандидатов, которые подали заявки на каждое из них. По запросу рекрутера, система оценивает кандидатов и ранжирует их соответствующим образом. Это достигается путем использования соответствующего классификатора Weka, через вызов API, предоставленный программным обеспечением Weka [13]. Рекрутер может изменить рейтинг кандидатов, назначив новые оценки навыков кандидатов. Это позволит повысить производительность будущей системы, предложения рекрутера включаются в обучающую выборку системы и модель ранжирования обновляется. Следует отметить, что модель ранжирования инициализируется как простая линейная комбинация из критериев отбора, пока не было введено достаточно информации от рекрутеров для создания обучающего множества.
2.2 Семантическое соответствие
В предыдущей версии системы [14] было установлено, что кроме руководящих должностей, необходимые навыки и квалификация, наша система определяет последовательно с корреляцией Пирсона до 0,85. Существующая расширенная версия системы посвящена проблеме конкретной квалификации и опыта работы на руководящих должностях и демонстрирует повышенную точность (как будет представлено в разделе 3) путем развертывания технологий семантического соответствия.
Обмен информацией между работодателями, кандидатами и сайтами для поиска работы в Web-ориентированных семантических сценариях основан на множестве словарей, которые предусматривают общие термины для описания профессий, отраслей промышленности и профессиональных навыков [15]. Семантическое соответствие это метод, который сочетает в себе использование аннотаций контролируемых словарей с базовыми знаниями об определенной предметной области. В нашем случае домен конкретных знаний представлена систематика ИТ-навыков (рис. 2). Таксономия определяется как набор категорий или терминов организованных в иерархию – родитель-потомок и подразумевает наследование, это означает, что ребенок термина (т.е., C) имеет все характеристики своего родителя термина (т.е. структурированного). Таксономия содержит только широкие и узкие отношения.
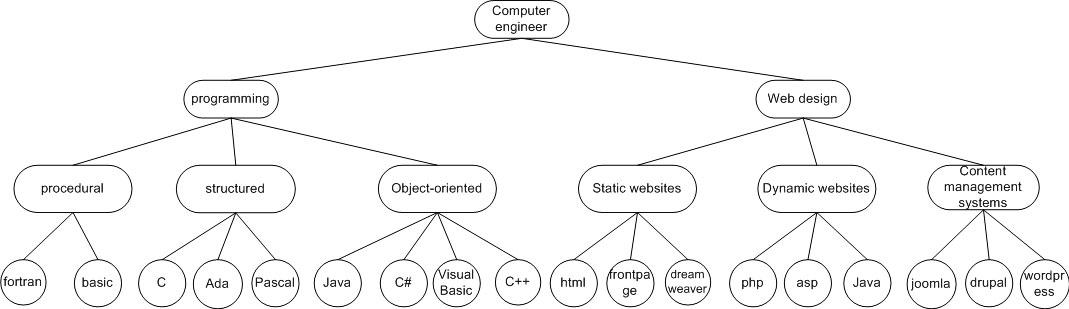
Рисунок 2 – Часть реализации таксономии ИТ навыков
Реализованная таксономия выполняет двойную роль:
1. Проверка соответствия навыков кандидатов, указанных в соответствующем профиле LinkedIn, должностным требованиям, указанных в описании вакансии, исключение всех кандидатов, которые не соответствуют требованиям.
2. Поиск в тексте должности и должностной инструкции в разделе опыт работы в профиле LinkedIn кандидата и идентифицирует членов, соответствующих навыкам, необходимых рекрутеру. Таким образом, в текущей версии системы, при расчете критерия опыта работы учитывается только опыт работы, относящийся к данной компетенции.
Важно уточнить, что в обоих случаях мы не используем простой поиск по ключевым словам, но используем концепцию поиска. Во-первых, для определённой должности поиск навыков применяется к навыкам кандидатов, которые указаны в соответствующем профиле LinkedIn (рис. 3). В большинстве случаев рекрутер не требует специализированных компетенций, но прибегает к более общей квалификации, такие как объектно-ориентированное программирование (а не Java или C#). В этом случае предложенный алгоритм ищет в дереве иерархии и определяет листья с узлом квалификации, требуемой от рекрутера, как их ближайшего общего предка (например, объектно-ориентированное программирование). Далее, выявленные узлы исследуются, чтобы определить, есть ли совпадения с навыками, заявленными кандидатом. В случае, если они не совпадают, то кандидат исключается из процесса ранжирования.
Для тех кандидатов, у которых были найдены необходимые навыки, второй поиск ведется для определения одной или нескольких должностей прошлого опыта работы кандидата, который ринадлежит к той же области компетентности, что и интересующая должность. Алгоритм, применяющийся для этой цели, может быть кратко описан следующим образом: Пусть S1 будет навыками, соответствующими прошлой должности, указанными в разделе опыта работы (название или описание) соответствующего профиля LinkedIn. Кроме того, пусть S – навыки, требуемые для текущей должности, соответствующей домену должностей и может быть найдена на любом уровне иерархии.
Если есть пересечение между S и S1 (S П S1 * = O), то прошлая должность E1 считается релевантной и, следовательно, учитывается в соответствующих расчетах опыта работы.
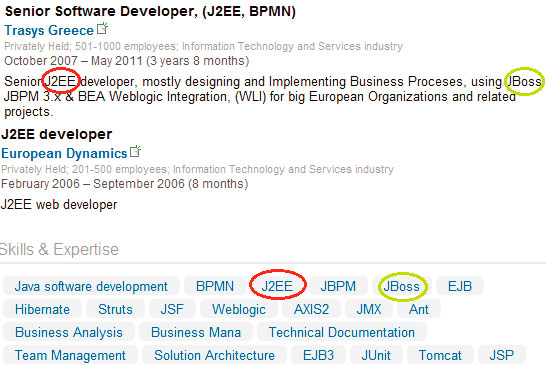
Рисунок 3 – Пример навыков в LinkedIn
2.3 Извлечение личностных характеристик
Предыдущие работы показали, что путем применения лингвистического анализа к сообщениям блога могут быть получены личностные характеристики автора [16], а также его настроение и эмоции [17]. Анализ текста в этих работах осуществляется с LIWC (лингвистический анализ и количество слов), которые анализирует образцы письменного текста и извлекают языковые особенности, которые выступают в качестве маркеров личности автора. Пенебакер и Kинг [18] обнаружили, что существует сильная корреляция между этими частотностями, а личностные характеристики автора, измеряются Big-пяти измерений личности.
В этой работе, мы ориентируемся на черту личности – экстраверсию, из-за её важности в отборе кандидатов. Экстраверсия является важнейшей характеристикой личности для должностей, которые взаимодействуют с клиентами, а социальные навыки важны для работы в команде. В частности, положительные эмоции и социальные ориентации CAN-кандидатов, которые непосредственно извлекаются из LIWC частых совпадений, которые могут выступать в качестве предпосылок черты экстраверсии [12]. Мы измерили экстраверсию, используя сообщения из блога кандидатов, которые вводятся в инструмент TreeTagger [19] для лексического анализа и лемматизации. Затем, используя LIWC словарь, наша система классифицирует канонические формы выходных слов от TreeTagger в одном из слов категорий интересов (то есть положительные эмоции, отрицательные эмоции и социальные слова) и вычисляет LIWC баллы. Наконец, система оценки экстраверсии оценивает заявителя. Эксперт-рекрутер присвоил баллы экстраверсии каждому из 100 претендентов на работу с личными блогами, которые были частью крупномасштабного сценария по набору персонала. Оценки рекрутера были использованы для обучения регрессионной модели, которая предсказывает экстраверсию кандидатов от их LIWC баллов для позитивных эмоций, негативных эмоций, социальных категорий. В дальнейшем модель линейной регрессии, была выбрана в качестве предиктора E оценки экстраверсии, как предложено в [20], в связи с его повышенной точностью и низкой сложностью. Уравнение 1 соответствует линейной модели, которая сводит к минимуму среднеквадратичную ошибку между фактическими значениями оценки, присвоенной рекрутером и прогнозируемой моделью:
E = S + 1.335 * P - 2.250 *N (1)
где S – частота социальных слова (например, друг, приятель, коллега) возвращаемых из LIWC, P – частота работы положительных эмоций и N-частота работы негативных слов, эмоций.
2.4 Оценивание кандидатов
Предлагаемая система использует алгоритмы машинного обучения для автоматического построения моделей оценивания претендентов. Этот подход требует достаточной подготовки входных данных, которые основаны на предыдущем решении отбора кандидатов. Методы, изучающие, как совместить предопределенные функции для ранжирования с помощью алгоритмов обучения с учителем называют методом "обучения ранжированию". В типичном процессе "обучения ранжированию" обучающая выборка, которая состоит из прошлых анкет кандидатов, представленных в виде векторов-признаков, обозначается как Х (К), а также суждения эксперта-рекрутера о релевантности кандидатов, обозначаемой как Yi. Обучающая выборка подается в алгоритм обучения который конструирует модель ранжирования, так что на выходе прогнозируется решение рекрутера, вектор навыков кандидата подается на вход. В заключительной фазе обучающая модель применяется для сортировки анкет кандидатов и возвращает конечный ранжированный список кандидатов.
В нашей задаче оценочная функция Н(х) выводит оценку актуальности кандидата, которая отражает, насколько хорошо профиль кандидата соответствует требованиям данной должности. Затем система выводит окончательный ранжированный список, применяя выученные функции для сортировки кандидатов. Истинность функций оценивания, как правило, неизвестна и приблизительно известна из обучающего множества D. В предлагаемой системе обучающая выборка состоит из N наборов предыдущего отбора кандидатов, представленных на вход системы (уравнение 2):
D = {(xi, yi)|xi Є Rm, yi Є R)}N (2)
3 Экспериментальная оценка
Предлагаемая система, которая была испытана на реальных наборах данных, может эффективно оценивать рейтинг претендентов на рабочие места. Оценка эффективности системы основана на сравнении баллов присвоенных каждому кандидату по сравнению с теми, которые присвоил рекрутер.
В сценариях приёма на работу, используемых в наших тестах, мы составили список из 100 претендентов с учетной записью LinkedIn и личным блогом, так как они являются ключевыми требованиями предлагаемой системы. Тот же список был использован в предыдущей версии системы [14] для сравнения причин. Претенденты были выбраны случайным образом с помощью поиска по блогам Google API с единственным требованием – наличие технического образования, которые указаны в метаданных блога (списке интересов), а также в профиле LinkedIn. Наш список соискателей был сформирован путём выбора первых 100 блогов, возвращённых API поиска профилей, которые соответствовали нашим предварительным условиям. Мы также выбрали три представительные технические вакансии, объявленные неназванными ИТ-компаниями с разными требованиями, то есть должность продавца техники, должность младшего программиста и должность старшего программиста.
Для должности продавца техники предпочтительнее высокая степень экстраверсии, в то время как опыт является наиболее важным навыком для старших программистов. О начинающих программистах в основном судят по лояльности (компания не будет вкладывать средства в подготовку отдельных специалистов, склонных к частой смене работы), а также образованию. Более того, каждая позиция имеет свой желаемый набор навыков, который семантически соответствует набору навыков, указанным пользователем в своем профиле LinkedIn. В частности, должность младшего программиста требует навыков разработки на языках программирования C++ или Java, в то время должность старшего программиста требует 5-летнего опыта работы с технологией J2EE. Использование различных требований к должности необходимо для того, чтобы проверить способность нашей системы сопоставлять профили кандидатов с соответствующей вакансией.
В наших экспериментах, мы предполагаем, что каждый кандидат в списке подал заявку на все три доступных рабочих места. Для каждой должности, кандидаты были ранжированы в соответствии с их пригодностью для работы на должности как системой (автоматизированное оценивание) так и экспертом-рекрутером. Рекрутер имел доступ к той же информации, что и система, т.е. блог кандидата и профиль LinkedIn. Следует отметить, однако, что, несмотря на то, что критерии отбора системы известны, интерпретация данных рекрутером и точный процесс принятия решения им неизвестны и должны быть изучены.
Таблица 1. Коэффициенты корреляции для кандидатов для оценки релевантности различных моделей машинного обучения
| Коэффициент корреляции | LR | M5' Tree | REP Tree | SVR, poly | SVR, PUK |
| TE | RE | TE | RE | TE | RE | TE | RE | TE | RE |
| Продавец техники | 0.74 | 0.74 | 0.81 | 0.81 | 0.81 | 0.81 | 0.61 | 0.61 | 0.81 | 0.81 |
| Младший программист | 0.79 | 0.81 | 0.85 | 0.85 | 0.84 | 0.86 | 0.81 | 0.81 | 0.84 | 0.86 |
| Старший программист | 0.64 | 0.73 | 0.63 | 0.71 | 0.68 | 0.80 | 0.62 | 0.68 | 0.73 | 0.82 |
В нашем первом эксперименте, мы используем Weka для оценки моделей обучения ранжированию. В частности, мы проверяем корреляции выводимых значений, полученный системой (т.е. предсказания модели) с фактическими значениями, определенными рекрутерами, используя коэффициент корреляции Пирсона. В таблице 1 приведены коэффициенты корреляции или 4 различных видов машинного обучения модели, а именно: линейная регрессия (LR), «дерево модели (M5'), дерево решений (REP) и опорных векторов регрессии (СВР) с двумя нелинейными ядрами (то есть ядра полиномиальные и PUK универсальные ядра). Для каждой модели машинного обучения мы показываем результаты, полученные с использованием суммарного опыта кандидата (TE) и те, которые получены с использованием только соответствующего опыта (RE).
Как можно увидеть, модели деревьев и СВР модели с ядром PUK дали наилучшие результаты. С другой стороны линейная регрессия работает плохо, предполагая, что критерии отбора линейно неразделимы. Следует отметить здесь, что все значения представляют собой средние значения, полученные техникой 10-кратной перекрестной проверки. Для должности продавца, в решениях рекрутеров преобладают весьма субъективные оценки экстраверсии, тем самым увеличивая неопределенность общей оценки. Тем не менее, система смогла достичь коэффициента корреляции до 0,81, в зависимости от используемой модели регрессии. С другой стороны, отбор кандидатов на младшего программиста основан на более объективных критериях, таких как лояльность и образование, в результате чего несколько выше коэффициент корреляции – до 0,86. Наконец, должность старшего программиста показала высокие консистенции, с корреляцией Пирсона до 0,82.
Что касается первой должности (т.е. продавец техники), то не было никакой разницы в результатах двух подходов, так как соответствующий опыт не имеет никакого влияния на расчет результата. Для этой должности кандидат может иметь опыт работы в любой области или отрасли (от программиста до продавца) и, следовательно, производная модель в точности совпадает с моделью, основанной на общем опыте кандидата. В случае со второй должностью, где учитывается только соответствующий опыт, существует небольшое различие в последовательности из двух подходов из-за небольшого влияния опыта на общий балл. Для последней должности, для которой удельный вес влияния опыта увеличивается, отчетливо наблюдается разность коэффициента корреляции. В частности, значения коэффициента корреляции значительно улучшены (доходят до 0,82 в случае опорных векторов регрессии с ядром PUK), в результате последовательность значений сравнима с двумя другими должностями.
3 Выводы
В этой работе мы представляем новый подход к оценке претендентов на вакансии в онлайн-системе подбора персонала, используя алгоритмы машинного обучения, чтобы решить проблему рейтинга кандидатов и использования методов семантического сопоставления. Предложенная схема основана на объективных критериях, полученных из профилей LinkedIn кандидатов и субъективных критериев, полученных из их социального присутствия, оценивает релевантность кандидатов и делает вывод об их личностных характеристиках. Кандидаты, которые не обладают необходимыми навыками, отфильтровываются в процессе отбора и для тех, кто остался, рассчитывается соответствующий опыт работы с использованием методов семантического соответствия, которые позволяют значительно улучшить результаты. Внедренная система была использована в крупномасштабных сценариях набора персонала, в который вошли три различные должности, и предлагалось 100 претендентов на рабочие места. Применение подхода в реальных условиях показало, что он эффективен при расчете соответствия кандидатов заданной должности и ранжирования их соответствующим образом.
Литература
1. Meo, P.D., Quattrone, G., Terracina, G., Ursino, D.: An xml-based multiagent system for supporting online recruitment services. IEEE Transactions on Systems, Man, and Cybernetics, Part A 37(4), 464–480 (2007)
2. Pande, S.: E-recruitment creates order out of chaos at SAT telecom: System cuts costs and improves efficiency. Human Resource Management International Digest 19(3), 21–23 (2011)
3. Kessler, R., Torres-Moreno, J.M., El-B`eze, M.: E-gen: automatic job offer processing system for human resources. In: Proc. Mexican International Conference on Advances in Artifficial Intelligence, pp. 985–995 (2007)
4. Bizer, C., Heese, R., Mochol, M., Oldakowski, R., Tolksdorf, R., Eckstein, R.: The impact of semantic web technologies on job recruitment processes. In: Proc. Internationale Tagung Wirtschaftsinformatik (2005)
5. Radevski, V., Trichet, F.: Ontology-based systems dedicated to human resources management: An application in e-recruitment. In: OTM Workshops, vol. (2), pp. 1068–1077 (2006)
6. Dorn, J., Naz, T., Pichlmair, M.: Ontology development for human resource management. In: Proc. International Conference on Knowledge Management, pp. 109– 120 (2007)
7. Mochol, M., Wache, H., Nixon, L.J.B.: Improving the Accuracy of Job Search with Semantic Techniques. In: Abramowicz, W. (ed.) BIS 2007. LNCS, vol. 4439, pp. 301–313. Springer, Heidelberg (2007)
8. Faliagka, E., Ramantas, K., Tsakalidis, A.K., Viennas, M., Kafeza, E., Tzimas, G.: An integrated e-recruitment system for cv ranking based on ahp. In: WEBIST, pp. 147–150 (2011)
9. Faliagka, E., Tsakalidis, A., Tzimas, G.: An integrated e-recruitment system for automated personality mining and applicant ranking. Internet Research (2012)
10. Amdouni, S., Ben Abdessalem Karaa, W.: Web-based recruiting. In: Proc. ACS/IEEE International Conference on Computer Systems and Applications, pp. 1–7 (2010)
11. Mochol, M., Paslaru, E., Simperl, B.: Practical guidelines for building semantic erecruitment applications. In: Proc. International Conference on Knowledge Man- agement, Special Track: Advanced Semantic Technologies (2006)
12. Faliagka, E., Kozanidis, L., Stamou, S., Tsakalidis, A., Tzimas, G.: A Personality Mining System for Automated Applicant Ranking in Online Recruitment Systems. In: Auer, S., Diaz, O., Papadopoulos, G.A. (eds.) ICWE 2011. LNCS, vol. 6757, pp. 379–382. Springer, Heidelberg (2011)
13. Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., Witten, I.H.: The weka data mining software: an update. SIGKDD Explor. Newsl. 11(1), 10–18 (2009)
14. Faliagka, E., Ramantas, K., Tsakalidis, A., Tzimas, G.: Application of machine learning algorithms to an online recruitment system. In: Proc. International Conference on Internet and Web Applications and Services (2012)
15. Liu, T.Y.: Learning to rank for information retrieval. Found. Trends Inf. Retr. 3(3), 225–331 (2009)
16. Gill, A., Nowson, S., Oberlander, J.: What are they blogging about personality, topic and motivation in blogs (2009)
17. Mishne, G.: Experiments with mood classiffication in blog posts. In: Proc. Workshop on Stylistic Analysis of Text For Information Access (2005)
18. Pennebaker, J.W., King, L.A.: Linguistic styles: language use as an individual difference. Journal of Personality and Social Psychology 77(6), 1296–1312 (1999)
19. Schmid, H.: Improvements in part-of-speech tagging with an application to german. In: Lexikon und Text, pp. 47–50 (1995)
20. Mairesse, F., Walker, M.A., Mehl, M.R., Moore, R.K.: Using linguistic cues for the automatic recognition of personality in conversation and text. Journal of Artificial Intelligence Research 30, 457–500 (2007)