Дослідження алгоритмічного забезпечення інтелектуальної системи
класифікації політематичних гіпертекстових документів
Зміст
- Мета і завдання
- Актуальність теми роботи
- Передбачувана наукова новизна
- Плановані практичні результати
- Глобальний рівень досліджень і розробок по темі
- Національний рівень досліджень і розробок по темі
- Локальний огляд досліджень і розробок
- Власні результати
- Висновки
- Література
1 Мета і завдання
Метою роботи є розробка і дослідження
алгоритмічного забезпечення інтелектуальної системи класифікації
політематичних гіпертекстових документів зі змінюваною безліччю категорій
Для досягнення поставленої мети потрібно рішення наступних завдань :
- Провести аналіз існуючих методів класифікації політематичних документів
- Вибрати і модифікувати моделі представлення документів і гіперпосилань вних
- Вибрати критерії оцінки ефективності алгоритмів класифікації
- Модифікувати алгоритми класифікації шляхом поєднання методів бінарної класифікації і ранжирування з пороговою функцією
- Оцінити ефективність запропонованих модифікованих алгоритмів
Об'єктом цього дослідження є системи аналізу
утримуваного Internet трафіку і великих колекцій електронних гіпертекстових документів.
Предметом дослідження виступає алгоритмічне
забезпечення класифікації гіпертекстових документів, заснованої на машинному
навчанні, в умовах істотно пересічних класів, коли документ може
бути віднесений до деякої безлічі доречних для нього класів.
2 Актуальність теми роботи
Всесвітня павутина, поза сумнівом, є найбільшою базою даних, створеною
людством. Величезна кількість даних створює в результаті багато нових
проблем по їх використанню. Основними проблемами є систематизація, в цілях
полегшення ручного перегляду і створення інструментів ефективного пошуку по
запитам. Для вирішення цих проблем створюються каталоги веб-сторінок [1]. Спочатку каталоги будувалися вручну, потім були
розроблені засоби для автоматизації цього процесу. Проте, важко
представити як, наприклад, найбільший www.dmoz.org, який містить більше п'яти
мільйонів сторінок відсортованих у більш ніж мільйон категорій, ми можемо проглянути
на домашній сторінці Open Directory Project [2].
Другий підхід полягає у використанні повнотекстового пошуку. Він починався із
звичайного пошуку відповідності слів, тепер складається з багатьох спеціалізованих
компонентів, які виконують переформулировку запиту, на основі з'ясування його
семантики [3].
Окрім категоризації і пошуку є ще одне завдання, яке включає знання
утримуваного документу – фільтрація веб-сторінок. Вона може бути використана для
різних цілей: фільтрації матеріалів для дорослих і дітей, забезпечення контролю
використання інтернет ресурсів в офісах, запобігання витоку
конфіденційної інформації, здійснення моніторингу забороненої активності
користувачів або навіть блокування незручних сторінок тоталітарних держав. Проблема з фільтрацією веб-сторінок може вирішуватися як завдання класифікації, яка характерна для Data Mining і використовує методи машинного
навчання. Основною відмінністю такого завдання класифікації від традиційної є
те, що класи в ній не є взаємовиключними [4].
Класифікація політематичних текстових документів не є тривіальним завданням,
оскільки в невеликому фрагменті тексту може міститися дуже цінна
інформація, і віднесення до відповідного класу не можна ігнорувати, а близько
розташовані класи можуть перетинатися і/або зливатися. До такого роду
документам можуть відноситися так само новинні потоки в мережі Інтернет, огляди,
формовані новинними агентствами, наукові публікації, присвячені декільком
областям досліджень, причому як близьким, так і далеким(наприклад,
штучний інтелект і інформаційні технології, онтологічні інжиніринг
і автоматична обробка текстів, медико-біологічні, фізико-хімічні). Специфіка
перерахованих прикладних завдань така, що набір тематик, що цікавлять
класифікації може динамічно змінюватися. Прикладів подібного роду стає
все більше. Таким чином, надзвичайно актуальним напрямом досліджень
являється розробка методів класифікації політематичних документів.
3 Передбачувана наукова новизна
Розробка і дослідження нових і модифікація відомих алгоритмів класифікації політематичних
документів шляхом визначення безлічі релевантних класів.
4 Плановані практичні результати
Практична значущість дослідження полягає в підвищенні ефективності класифікації
політематичних гіпертекстових документів.
Розроблене алгоритмічне забезпечення може використовуватися при програмній реалізації
інтелектуальної системи класифікації, орієнтованої на рішення завдань аналізу
контенту Internet трафіку і корпоративних колекцій
електронних гіпертекстових документів.
5 Глобальний рівень досліджень і розробок по темі
Розробка підходів і алгоритмів рішення задачі класифікації документів змішаної
тематичній спрямованості – цей відносно новий напрям досліджень,
яке нині активно розвивається за кордоном і в Росії. Більшість
існуючих підходів є альтернативою безпосереднього зведення даної
завдання до традиційного завдання класифікації Сучасні методи
класифікаційного пошуку, фільтрації Internet-трафіку
засновані на механізмі автоматичної класифікації текстів. Цей підхід, як
правило, має на увазі застосування методів категоризації, які розподіляють
документи по зумовленому набору рубрик на основі знання, отриманого з
повчальної множини. Розробці і тестуванню алгоритмів цього виду, а
також пов'язаним з ними алгоритмам представлення текстів присвячені праці таких
авторів як Bezdek J.C., Kohonen T., Krishnapuram R., Keller J., Desjardins G., Zhang C., T. Joachims, D.D. Lewis, R.E. Schapire, H. Schutze, F. Sebastiani,
Y. Yang, I. Dagan, S.T. Dumais.
Серед російських дослідників слід виділити роботи Айвазян С. А., Загоруйко М. Г. М. С. Агеев, И. Е. Кураленок, И. С. Некрестьянов, В. И. Шабанов, Глазковой В. В.
У роботі [5] розглянута технологія(архітектура, алгоритми і програмні
засоби) побудови системи фільтрації Інтернет-трафіку локальних мереж на
основі методів машинного навчання. Запропонована оригінальна архітектура,
що використовує методи машинного навчання для вирішення завдання багатотемного
класифікації Інтернет-ресурсів. Описані основні модулі системи, їх алгоритми
роботи і спосіб організації бази знань. Розроблена архітектура
експериментально протестована на еталонних тестових наборах даних,
результати експериментів показали досить високу точність і швидкість
роботи.
6 Національний рівень досліджень і розробок по темі
Теоретичні алгоритмічні і практичні питання розробки
програмних засобів для завдань класифікації багатотемних документів вирішуються ученими Харківського
національного університету радіоелектроніки з використанням тих, що самоорганизующихся
нейронних мереж і генетичних алгоритмів.
У роботі [6] запропонована адаптивна нечітка нейронна мережа, що самоорганизующаяся, а
також модель системи кластеризації політематичних текстових документів на
основі розробленої нейронної мережі, що відрізняються від існуючих моделей своїй
архітектурою і методами навчання. Розроблений метод автоматичної кластеризації
політематичних текстових документів на основі генетичного алгоритму з
штучним відбором. На відміну від існуючих генетичних алгоритмів, в даному
методі в процедури генетичної оптимізації вводяться елементи штучного
відбору – оператори розтягування, стискування і відображення.
У статті [7] розглядається проблема інтелектуальної обробки текстової
інформації. Представлена архітектура нечіткої нейромережевої системи для
класифікації текстових документів і on-line алгоритм навчання мережі адаптивного
нечіткого векторного квантування
7 Локальний огляд досліджень і розробок
У роботі [8] розглядається класифікація документів заснована
на знаннях. Пропонується механізм рубрикації текстів на основі побудови семантичних мереж. Рубрикації великих
текстових колекцій здійснюється по безлічі рубрик, що заздалегідь фіксується.
8 Вибір методу і критеріїв оцінки ефективності рішення задачі класифікації політематичних
гіпертекстових документів
8.1 Традиційна постановка завдання
класифікації текстових документів
Об'єкти класифікації текстові і гіпертекстові
документи і їх фрагменти є слабо структурованими різнорідними
даними. Запропоновані багато методів для вирішення завдання класифікації за допомогою
автоматичних процедур. Їх можна розділити на два принципово різних
класу: методи машинного навчання(МО) і методи, засновані на знаннях(також
іноді іменовані „інженерний підхід”). Предметом розгляду
справжньої роботи являються методи машинного навчання.
Постановка завдання класифікації. Нехай 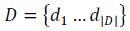 – безліч документів,
– безліч документів, 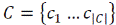 – безліч тематик,
Φ: D × C→{0,1} – невідома цільова функція, яка для пари <Di, Cj> говорить, принадлежитли
документ Di тематиці Cj. Завдання полягає в побудові функції Φ′, максимально близькою до Φ.
– безліч тематик,
Φ: D × C→{0,1} – невідома цільова функція, яка для пари <Di, Cj> говорить, принадлежитли
документ Di тематиці Cj. Завдання полягає в побудові функції Φ′, максимально близькою до Φ.
При машинному навчанні класифікатора передбачається ще наявність колекції
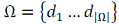 – заздалегідь класифікованих
документів, тобто з відомим значенням цільової функції. Зазвичай в
якості повчальної вибірки виступає масив текстових документів,
класифікований експертами. Алгоритм машинного навчання будує процедуру
класифікації документів на основі автоматичного аналізу заданої великої кількості
досліджених текстів. Для перевірки придатності використання побудованого
класифікатора слід оцінити точність пророцтва. Для цього необхідно
мати тестову вибірку.
– заздалегідь класифікованих
документів, тобто з відомим значенням цільової функції. Зазвичай в
якості повчальної вибірки виступає масив текстових документів,
класифікований експертами. Алгоритм машинного навчання будує процедуру
класифікації документів на основі автоматичного аналізу заданої великої кількості
досліджених текстів. Для перевірки придатності використання побудованого
класифікатора слід оцінити точність пророцтва. Для цього необхідно
мати тестову вибірку.
Таким чином, наявні дані розділяють на дві
групи – повчальну і тестову вибірки. Перша використовується для побудови
моделі, друга – для оцінки ефективності
8.2 Характеристика методів, заснованих на машинному навчанні
Машинне навчання грунтується на наявності початкового корпусу
документів, класифікація яких була проведена заздалегідь. Т. е. значення
функції F : D х C – > {T, F} відомо для кожної пари(d, c) з W Í C. Документ dj – позитивний
приклад ci, якщо F=T, і негативний інакше.
В процесі машинного навчання деякий попередній
процес(що називається навчанням) автоматично будує класифікатор для категорії
ci, спостерігаючи за характеристиками документів, яким була присвоєна експертом категорія
ci чи 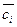 . З їх
характеристик вибираються ті, які повинен мати документ, що класифікується,
щоб йому була присвоєна категорія ci. В термінах машинного навчання – це процес контрольованого навчання, оскільки в процесі навчання відомо до яких категорій відносяться усі документи з
тренувальній колекції. Методи в яких розглядається тільки два класи ci чи
називаються бінарними(малюнок 1).
. З їх
характеристик вибираються ті, які повинен мати документ, що класифікується,
щоб йому була присвоєна категорія ci. В термінах машинного навчання – це процес контрольованого навчання, оскільки в процесі навчання відомо до яких категорій відносяться усі документи з
тренувальній колекції. Методи в яких розглядається тільки два класи ci чи
називаються бінарними(малюнок 1).
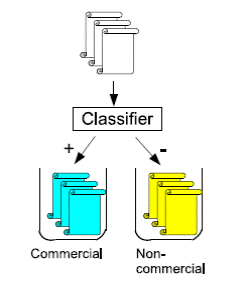
Малюнок 1. Бінарна класифікація
Тексти не можуть безпосередньо інтерпретуватися алгоритмами
класифікації, оскільки вони оперують числовими даними, а текст це усього лише
послідовність символів. Тому потрібно процес індексації, в результаті
якого виходить компактне представлення документу dj,
зручне для подальшої обробки. Вибір представлення тексту залежить від того,
що вважається частинами тексту, що несуть сенс, і які правила обробки
природного тексту допустимо застосовувати до цих частин.
Більшість алгоритмів класифікації
працюють з формальним описом об'єктів на основі векторної моделі
представлення документу [10]. У цій моделі документ описується
числовим вектором a фіксованої довжини п, де п – число ознак,
а i-я компонента вектору визначає вагу i-го ознаки. Для реалізації моделі представлення
необхідно вибрати признаковое простір і визначити алгоритм
обчислення вагів.
Якість вибраної моделі представлення
при фіксованому алгоритмі класифікації і фіксованому еталонному тестовому
наборі документів можна оцінити за наступними критеріями:
точність класифікації : основний
критерій(залежить також від алгоритму класифікації);
розмірність признакового простору : при
однаковій точності прийнятніше признаковое простір меншої
розмірність;
розмір отримуваної моделі класифікації :
при однаковій точності прийнятніше компактні моделі;
час навчання і класифікації : важливий критерій, залежний, у тому числі, від двох
попередніх;
підтримка
морфології мови : цей критерій тісно пов'язаний з усіма попередніми, в
частковості, підтримка морфології веде до точніших і компактніших моделей
класифікації.
Усі алгоритми МО використовують представлення документу dj у вигляді вектору вагів
термів dj= <wj, 1,., wj,|T|>, де T –
безліч усіх термів, які враховуються в тексті. wj, k – вага k-го терма в документі
dj, показує, наскільки велику смислову
навантаження несе k-й терм в документі. Є два основних
відмінності в підходах до представлення текстів :
- що вважається термом;
- як визначається вага терма.
Як правило, в якості термів вибирають окремі слова або
їх основи. Ця модель носить назву „bag-of-words”, оскільки вона не зберігає
інформації про порядок входження слів в документ.
Найпоширенішим способом формування признакового простору є метод
ключових слів [1, 2]. В якості ознак в цьому методі використовуються
лексеми, що входять в документи, а розмірність признакового простору рівна
розмірність словника. Проте цей метод, наприклад, не враховує морфологію
мови, а також семантичні зв'язки між словами. Підтримку морфології можна
реалізувати за допомогою методів стемминга [2], заснованого на наведенні слів до
їх базовій словоформі. Але тоді для кожної мови потрібний морфологічний
аналізатор, що, веде до додаткового обчислювального навантаження і до завдання визначення мови документу(якщо такий
не вказаний у властивостях документу) і, по-третє, для деяких мов побудова
морфологічного аналізатора є досить складним завданням.
Проблему
залежності моделі представлення від мови вирішує метод N-грам [3]. У цьому методі в якості ознак беруться букводрукувальні фіксованої довжини N, що підряд йдуть. При цьому кожне слово розбивається на набір
ознак, а однокорінні слова утворюють схожий набір ознак. Основним
гідністю цього методу представлення є відсутність необхідності
додаткової лінгвістичної обробки тексту і незалежність від конкретного
мови. Розбиття на N-грами набагато простіші, ніж
виділення базової словоформи, а через обмеженість алфавіту в усіх мовах
максимальне число різних ознак також обмежене. В якості недоліків
методу N-грам можна вказати збільшення числа непорожніх
ознак у документу, а також те, що в моделі не враховуються семантичніие
зв'язки між ознаками.
При класифікації текстів, як правило, відомо декілька зумовлених
категорій до яких мають бути віднесені документи. В цьому випадку класифікація
називається мультикласовою(малюнок 2)
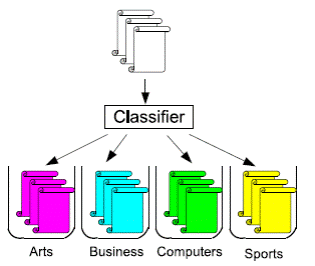
Малюнок 2. Мультикласова класифікація
Окрім представлення вмісту документів, важливим моментом є облік в моделі
наявність гіперпосилань між документами. Одним з найбільш ефективних
сучасних підходів до цієї проблеми являється метод учeта
посилальної структури документів, запропонований в [11]. У цьому методі спочатку
класифікуються документи-сусіди даного документу, а потім кожна
гіперпосилання в початковому документі замінюється ідентифікатором класу
документу-сусіда, на якого вона вказує. Таким чином, гіперпосилання
замінюються на спеціальні ідентифікатори(чи спеціальні лексеми), які
характеризують теми документів, на які вони посилаються. Таке представлення
документів грунтується на інформації, яка являється як локальною, так і
нелокальною по відношенню до цього документу. Важливим недоліком даного
підходу являється необхідність отримання і класифікації вмісту
документів-сусідів, що вносить додаткове обчислювальне навантаження, а іноді
виявляється неможливим, якщо документ, на який вказує посилання
недоступний.
8.3 Методів класифікації політематичних документів
Постановка завдання політематичної(multi-label) класифікації.
У повчальній сукупності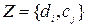 для кожного прикладу
для кожного прикладу 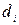 – задана безліч релевантних
класів
– задана безліч релевантних
класів 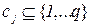 . Метою
алгоритму машинного навчання являється побудова класифікатора ФZ : D® 2, що передбачає все
релевантні класи, де D початковий простір ознак і q число класів.
. Метою
алгоритму машинного навчання являється побудова класифікатора ФZ : D® 2, що передбачає все
релевантні класи, де D початковий простір ознак і q число класів.
Існуючі методи класифікації політематичних документів базуються, в основному, на трьох
підходах:
- оптимізаційному
- декомпозиції в набір бінарних проблем
- ранжируванні.
На мал. 3 показані два типи політематичної класифікації :
груба класифікація(встановлюється тільки список класів до яких можна
віднести документ) і м'яка класифікація(визначається вірогідність віднесення
документу до кожного з класів)
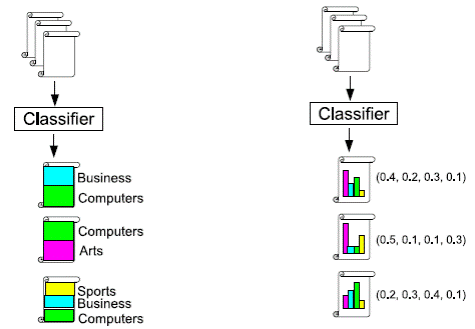
Малюнок 3. Типи політематичної класифікації
До методів класифікації, заснованих на оптимізаційному
підході, можна віднести наступні методи: AdaBoost.MH, ADTBoost.MH(мінімізується функція Hamming Loss для оцінки втрат multi-label класифікації), метод Multi-Label-kNN(максимізовувалася апостеріорна вірогідність приналежності класам) і метод на основі моделі
змішування, навченою за допомогою методу EM(параметри моделі оцінюються на основі принципу
максимізації математичного очікування).
Методи, засновані на декомпозиції multi,-label проблеми в набір незалежних бінарних проблем
(„каждый-против-остальных”)створюють одну бінарну проблему для кожного з
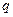 класів. У бінарній проблемі для
класу
класів. У бінарній проблемі для
класу 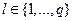 все
повчальні приклади, помічені цим класом, вважаються позитивними, а все
інші повчальні приклади вважаються негативними. При класифікації на
основі декомпозиції „каждый-против-остальных” рішення про приналежність об'єкту
конкретному класу приймається незалежно від інших класів. Зважаючи на таке
підходу декомпозиції методи цієї групи мають можливість додавання і видалення
класів без необхідності навчання моделі класифікації „з нуля”. На
сьогоднішній день декомпозиція „каждый-против-остальных” являється найбільш
популярним підходом при рішенні задачі класифікації політематичних
документів в сучасних практичних застосуваннях. Недоліком методів цій
групи являється те, що будуються незалежні класифікатори, які не
враховують кореляції між класами.
все
повчальні приклади, помічені цим класом, вважаються позитивними, а все
інші повчальні приклади вважаються негативними. При класифікації на
основі декомпозиції „каждый-против-остальных” рішення про приналежність об'єкту
конкретному класу приймається незалежно від інших класів. Зважаючи на таке
підходу декомпозиції методи цієї групи мають можливість додавання і видалення
класів без необхідності навчання моделі класифікації „з нуля”. На
сьогоднішній день декомпозиція „каждый-против-остальных” являється найбільш
популярним підходом при рішенні задачі класифікації політематичних
документів в сучасних практичних застосуваннях. Недоліком методів цій
групи являється те, що будуються незалежні класифікатори, які не
враховують кореляції між класами.
Рішення задачі multi-label класифікації на основі
ранжирування включає два етапи. Перший етап полягає в навчанні алгоритму
ранжирування, який упорядковує усі класи по мірі їх релевантности для
заданого об'єкту, що класифікується. Для ранжирування класів політематичних
об'єктів застосовуються наступні алгоритми: ММР, k-NN, RankSVM. Другий етап полягає
у побудові порогової функції, що відділяє релевантні класи від нерелевантних.
8.4 Методика виміру характеристик класифікатора
При дослідженні і порівнянні алгоритмів, після того, як класифікатор F був побудований, необхідно якимсь чином
виміряти його ефективність. Для цього, перед початком створення класифікатора,
початковий корпус, на якому проводиться тестування, ділиться на дві частини (не
обов'язково однакового розміру) :
- Тренувальна(і перевірочна) колекція TV. Класифікатор F будується на основі огляду характеристик цих документів.
- Тестова колекція Te, використовується для перевірки ефективності класифікатора. Кожен документ dj
з Te подається на вхід класифікатора і відповіді класифікатора F(dj, ci) порівнюються
з експертними оцінками F(dj, ci). Ефективність класифікатора визначається на основі того, наскільки часто ціи
оцінки співпадають.
Документи з Te ні в якому вигляді не повинні брати участь в побудові класифікатора. Якщо це
умова не дотримується, то спостережувані при тестуванні результати будуть
занадто хороші [9]. При практичному застосуванні класифікатора, після того, як
його характеристики були виміряні, можна провести навчання, використовуючи увесь
початковий корпус, для підвищення ефективності. В цьому випадку результати
попередніх вимірів можна розглядати як песимістичну оцінку реальної
ефективності, оскільки отриманий зрештою класифікатор навчався на
більшій кількості даних, ніж класифікатор, що використався при
тестуванні.
Підхід з розділенням початкової колекції носить назву
„обучение-и-тестирование”, альтернативою йому являється метод „кросс-валидации” [9],
при якому будується k різних класифікаторів F1,., Fk, при
розділенні початкової колекції на k частин Te, що не перетинаються>1, ., Tek і застосуванні
„обучения-и-тестирования” на парах (TVi = W-Tei, Tei}. Кінцева
ефективність визначається за допомогою усереднювання показників окремих класифікаторів F1, ., Fk.
При обох підходах в процесі навчання може виникнути необхідність перевірити,
як позначиться зміна якого-небудь параметра на ефективності. В цьому випадку
тренувальна і перевірочна колекція TV = d1, ., d| TV | розділяється
на дві колекції:
- Тренувальна колекція Tr = d1, ., d|Tr|, на основі якої будується класифікатор.
- Перевірочна колекція Va = d|Tr|+1, ., d |TV|, на якій проводяться тести, що повторюються
з метою оптимізації параметрів класифікатора.
8.5 Використовуваних метрик
Точність і повнота. Ефективність класифікації, як правило, вимірюється в класичних метриках інформаційного
пошуку – точність(precision) і облиште(recall), адаптованих до випадку ТК [13].
Точність pi-категории ci
визначається як умовна вірогідність P(F = T | F = T),
тобто вірогідність того, що випадковий документ dx буде коректно віднесений до категорії ci.
Аналогічно повнота ri категорії ci
визначається, як P(F = T | F = T), тобто вірогідність
того, що документ dx, який має бути віднесений до категорією ci, буде класифікований під нею.
Вірогідність pi і ri можуть бути оцінені за допомогою таблиці
збігів Таблиця 1. Ця таблиця містить інформацію про збіги рішень класифікатора і експертів. Стовпці
відповідають оцінкам експертів, рядка – оцінкам класифікатора. На їх
перетинах знаходяться чотири значення:
- FPi< (false positives)число документів
некоректно віднесених класифікатором до категорії ci;
- TPi (true positives)число документів коректне віднесених до категорії;
- TNi (true negatives)число документів коректне не віднесених до категорії;
- FNi (false negatives)число документів некоректне не віднесених до категорії.
|
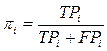
|
(1)
|
|
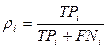
|
(2)
|
Таблиця 1. Таблиця збігів для категорії ci
|
|
Оцінки експертів
|
|
Так
|
Ні
|
|
Оцінки класифікатора
|
Так
|
TPi
|
FPi
|
|
Ні
|
FNi
|
TNi
|
Ці значення відносно категорії можуть бути усереднені,
для отримання точності p і
повнота r на усьому наборі категорій. Існує
дві методики усереднювання :
- Макроусереднювання – спочатку обчислюються точність pi і повнота r
i для кожної категорії окремо і потім усереднюються по формулах(3) і(4).
|
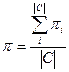
|
(3)
|
|
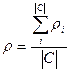
|
(4)
|
- Мікроусереднювання – обчислюється глобальна таблиця збігів(Таблиця 2), p
і r обчислюються по формулах аналогічних для pi і ri.
|
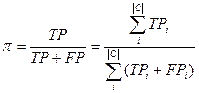
|
(5)
|
|
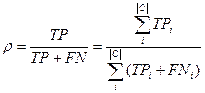
|
(6)
|
Ці методи дають результати, що значно розрізняються. При
мікроусереднюванні вклад категорії в кінцевий результат тим більше, чим більше
документів належать до категорії. При макроусереднюванні усі категорії в рівних
пропорціях впливають на кінцевий результат. Вибір того або іншого усереднювання
залежить від сфери застосування класифікатора.
Таблиця 2. Глобальна таблиця збігів
|
|
Оцінки експертів
|
|
Так
|
Ні
|
|
Оцінки класифікатора
|
Так
|
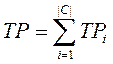
|
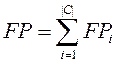
|
|
Ні
|
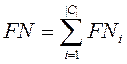
|
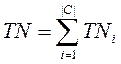
|
8.6 Пропонованих напрямів вдосконалення алгоритмів класифікації
Для підвищення ефективності класифікації планується
використати поєднання методів бінарної класифікації для класів і
ранжирування з пороговою функцією для виділення релевантних для документу
класів.
Планується реалізувати облік гіперпосилань на етапі
побудови векторної моделі представлення документу. При цьому гіперпосилання
аналізуються як текстові рядки і визначаються їх класи, які
враховуються при представленні поточного документу. При формуванні
представлення документу, кожне гіперпосилання замінюється набором спеціальних
ідентифікаторів, що відповідають ідентифікаторам передбачених класів. Це
дозволить враховувати гіперпосилання, що зустрічаються в документах, без необхідності
отримання і аналізу вмісту документів-сусідів.

Малюнок 4. Спосіб учeта гіперпосилань при представленні
документів
Висновки
Проведений аналіз особливостей класифікації документів у разі, коли класи можуть
перетинатися і документ може бути віднесений до декількох класів. Існуючі
методи забезпечують якість класифікації, недостатню для їх застосування в
сучасних прикладних системах. Розглянута методика виміру характеристик
класифікатора і вибрані метрики для ефективності класифікації. Надалі
планується розробити модель представлення документів з урахуванням гіперпосилань і
алгоритми політематичної класифікації на основі бінарного методу і
ранжирування.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2013 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Література
-
Gerhard K. H. Cataloguing Internet Resources: Practical Issues and Concerns /
K. H. Gerhard // Serials Librarian. — 1997. Vol. 32, № 1/2. — P. 123–137.
-
Open Directory Project. Интернет-ресурс. — Режим доступа: http://www.dmoz.org/
-
Кутовенко А. В. Профессиональный поиск в Интернете / А. В. Кутовенко.
— СПб.: Питер, 2011. — С. 256.
-
Comite F. D. Learning multi-label alternating decision tree from texts and data /
F. D. Comite, R. Gilleron, M. Tommasi // Machine Learning and Data Mining in Pattern Recognition,
MLDM 2003 Proceedings, Lecture Notes in Computer Science 2734. — Berlin, 2003. — P. 35–49.
-
Глазкова В. В. Система фильтрации Интернет-трафика на основе методов машинного обучения /
В. В. Глазкова, В. А. Масляков, И. В. Машечкин, М. И. Петровский // Вопросы
современной науки и практики. Университет им. В. И. Вернадского, серия «Технические науки»,
ассоциация «Объединённый университет им. В. И. Вернадского». — 2008. — том 2,
№2(12). — С. 155–168.
-
Волкова В. В. Методы нечеткой кластеризации политематических текстовых документов:
Автореф. дис. … канд. техн. наук: 05.13.23 «Системы и средства искусственного интеллекта» /
В. В. Волкова; Харьк. нац. ун-т радиоэлектроники. — Х., 2010. — С. 134.
-
Золотухин О. В. Классификация политематических текстовых документов с применением
нейро-фаззи технологий / О. В. Золотухин // Технологический аудит и резервы производства. — 2012.
— № 5/2(7). — C. 30.
-
Охрименко К. С. Рубрикация текстов на основе автоматического построения семантических сетей /
К. С. Охрименко, А. С. Калинин // Информатика и компьютерные технологии. — VIII, ДонНТУ
19-Сен-2012. — Интернет-ресурс. — Режим доступа:
http://ea.donntu.ru/handle/123456789/15560
-
Friedman J. Additive logistic regression: a statistical view of boosting / J. Friedman,
T. Hastie, R. Tibshirani // Annals of Statistics. — 2000. — Vol. 28, № 2. — P. 337–407.
-
Моченов С. В. Применение статистических методов для семантического анализа текста /
С. В. Моченов, А. М. Бледнов, Ю. А. Луговских. — Ижевск: НИЦ
«Регулярная и хаотическая динамика», 2005. — С. 408.
-
Chakrabarti S. Enhanced hypertext categorization using hyperlinks / S. Chakrabarti,
E. Byron, P. Indyk. // Proceedings of the ACM International Conference on Management of Data, SIGMOD.
— 1998. — P. 307–318.
-
Рассел С. Искусственный интеллект: современный подход, 2-е изд..: Пер с англ. /
С. Рассел, П. Норвиг – М.: Издательский дом «Вильямс», 2006. – С. 1408.
-
Baeza Y. Modern Information Retrieval / Y. Baeza, B. Ribeiro-Neto. —
Harlow: Addison-Wesley, 1999. — P. 357.
-
Венков А. Г. Построение и идентификация нечетких математических моделей технологических
процессов в условиях неопределенности: Автореф. дис. … канд. техн. наук. / А. Г. Венков. — Липецк: ЛГТУ, 2002. — С. 20.
-
Tsoumakas G. «Multi-Label Classification: An Overview»,
International Journal of Data Warehousing and Mining / G. Tsoumakas, I. Katakis. — 2007. — Vol. 3, №3 — Р. 1–13.
-
Глазкова В. В. Исследование и разработка методов построения программных средств
классификации многотемных гипертекстовых документов: Автореф. дис. … канд. физическо-мат. наук: 05.13.11 / В. В. Глазкова
— М.: МГУ, 2002. — С. 103.




