
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Наукова новизна
- 4. Огляд досліджень і розробок
- 4.1 Нейронні мережі
- 4.2 Використання нейронних мереж та генетичних алгоритмів
- 4.3 Генетичні алгоритми
- 5. Розробка алгоритму відбору оптимальної регресійної моделі за допомогою методу групового обліку аргументів
- Висновки
- Перелік посилань
Вступ
Нині в медицині особливе значення придбаває напрям, пов'язаний зі зниженням перинатальної смертності. Перинатальним періодом називається період, що розпочинається з 28-го тижня внутріутробного розвитку, коли маса плоду досягає 1000 г і більше, і що триває до 8-го дня(168 ч) життя новонародженого. При усій своїй відносній нетривалості перинатальний період є найважливішим етапом в житті людини, оскільки смертність в цей період така ж, як смертність у віці людини від 8 днів і до 40 років, а небезпека важких неврологічних порушень в цей період навіть перевищує таку в подальші десятиліття життя людини.
Найбільш дієвий шлях в зниженні смертей лежить в розробці програм прогнозування. Складність їх розробки полягає в необхідності наукового аналізу великої кількості клінічних і лабораторних показників, які знаходяться в складній залежності один від одного і не завжди піддаються кількісній оцінці. Тому не менш важливим є завдання визначення чинників ризику, оскільки аналіз усієї доступної інформації, як правило, викликає істотні утруднення при розробці і реалізації методів прогнозування при створенні аналітичної системи.
1. Актуальність теми
Останні десятиліття XX і початок XXI століття ознаменувалися чіткою тенденцією зниження основних показників, як в демографії, так і в родопомочі практично у всьому світі. На тлі зниження інтенсивності приросту населення збільшуються показники материнської, перинатальної, дитячої і дитячої смертності.
Можливість прогнозування перинатального ризику напередодні пологів дозволить своєчасно знизити материнську захворюваність і смертність новонароджених, а також зробити адекватну терапію із залученням висококваліфікованих
2. Мета і задачі дослідження та заплановані результати
Метою даної роботи є отримання корисної інформації з набору параметрів (факторів ризику) та розробка аналітичної системи для прогнозування перинатального ризику.
Для розробки аналітичної системи прогнозування перинатального ризику необхідно вирішити наступні задачі:
- Розробка структури системи.
- Розробка методів прогнозування на основі МГУА.
- Реалізація методів прогнозування на основі МГУА.
Об'єкт дослідження: процес проектування і розробки методів вилучення знань для медичних аналітичних систем.
Предмет дослідження: методи розробки вилучення знань для аналітичної системи прогнозування перинатального ризику.
3. Наукова новизна
Наукова новизна полягає в застосуванні методу групового обліку аргументів для відбору оптимальної регресійної моделі, а також вирішується супутнє завдання відбору факторів ризику, що впливають на перинатальний ризик у жінок.
4. Огляд досліджень і розробок
4.1 Нейронні мережі
Нейронні мережі можна розглядати як сучасні обчислювальні системи, які перетворюють інформацію за образом процесів, що відбуваються в мозку людини. Оброблювана інформація має чисельний характер, що дозволяє використовувати нейронну мережу, наприклад, в якості моделі об'єкта з абсолютно невідомими характеристиками. Інші типові програми нейронних мереж охоплюють задачі розпізнавання, класифікації, аналізу та стиснення образів.
У самому спрощеному вигляді нейронну мережу можна розглядати як спосіб моделювання в технічних системах принципів організації та механізмів функціонування головного мозку людини. Відповідно до сучасних уявлень, кора головного мозку людини являє собою безліч взаємопов'язаних найпростіших осередків – нейронів, кількість яких оцінюється числом порядку 1010. Технічні системи, в яких робиться спроба відтворити, нехай і в обмежених масштабах, подібну структуру (апаратно або програмно), отримали найменування нейронні мережі.
Даний метод складно реалізуємо, оскільки практично важко відстежити правильність роботи даного методу на етапі налагодження. А так само неможливість інтерпретації проміжних даних і складність роз'яснення результатів роботи мережі робить даний метод вкрай незручним для застосування в даному випадку.
4.2 Використання нейронних мереж та генетичних алгоритмів
Відбір інформативних параметрів виконується за допомогою нейронних мереж [1-2] і генетичних алгоритмів [3-4]. Такий підхід (спільне використання) дозволить не просто виконати відбір факторів ризику, а вибрати інформативний набір даних, зберігши взаємопов'язані змінні.
Для реалізації такого підходу спочатку необхідно розробити НС для визначення ризику розвитку акушерських кровотеч. Для практики найважливішим є визначення ризику втрати крові при пологах більш ніж 0,5% від маси тіла, з метою вживання відповідних заходів. У цьому випадку, по суті, виконується класифікація на два класи: патологічна кровотеча і допустима. Для реалізації поставленого завдання в такій формі доцільно використовувати багатошарову НС прямого поширення. Такий тип НС показує гарні результати при навчанні з вчителем, так як є навчальна вибірка з реальними медичними даними, то виберемо багатошарову НС для класифікації на патологічну і звичайну втрату крові при пологах. Таким чином, на першому етапі необхідно вибрати архітектуру нейронної мережі та навчити її. Враховуючи те, що в подальшому (при відборі факторів ризику) на кожному кроці виконання ГА буде відбуватися навчання НС, доцільно вибирати архітектуру мережі з мінімальною складністю, що дозволить зменшити час виконання програми. Під складністю мережі будемо припускати обчислювальну складність алгоритму навчання НС. Під обчислювальною складністю алгоритму навчання будемо розуміти кількість операцій за один крок навчання. Відомо, що для алгоритму зворотнього поширення кількість операцій пов'язано лінійною залежністю з синаптичними вагами (включаючи пороги) [5]. Тобто обчислювальну складність визначає число прихованих шарів і число нейронів на кожному з них. В результаті була обрана архітектура НС, представлена на мал. 1. Кількість входів обумовлена максимальною кількістю чинників ризику (після кодування їх отримали 99). Вибрані активаційні функції – гіперболічний тангенс і лінійна функція.
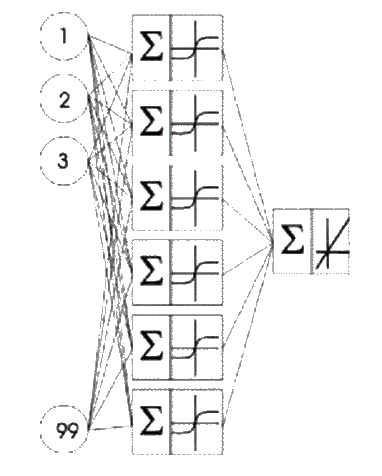
Малюнок 1 – Архітектура нейронної мережі
Після того як визначена і успішно навчена НС, виконується ГА, який подає різні комбінації факторів ризику на входи НС і потім виконується спроба навчити мережу при такій комбінації відібраних факторів ризику. Принцип реалізації кодування хромосоми представлений на мал. 2. Кожна хромосома являє собою послідовність певної кількості бітів (визначається максимальною кількістю чинників ризику). Значення кожного біта дорівнює 1, якщо фактор з відповідним номером присутній в даному наборі, і 0, якщо цей фактор відсутній.
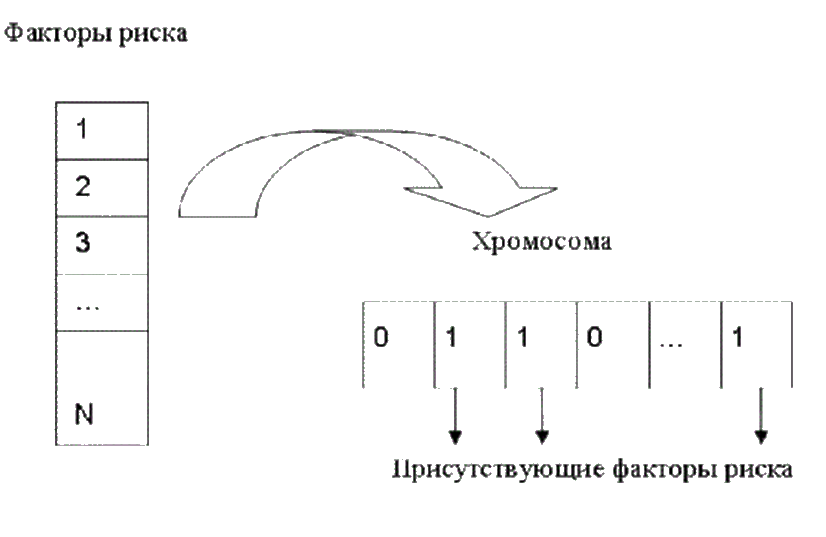
Малюнок 2 – Кодування хромосоми
У пропонованому підході для виділення ознак використаний генетичний алгоритм, який має модифіковану схему реалізації стосовно до задачі багатокритеріальної оптимізації. У той час як більшість подібних методів, використовуваних для вирішення таких завдань, використовує єдиний, складовий оптимізуємий критерій [1].Вирішенням задачі в даному випадку є кілька недомінуючих підмножин ознак. Розроблена фітнес-функція (1), яка передбачає пошук рішення, що є оптимальним згідно з двома критеріями – враховується точність класифікації і кількість факторів ризику. До того ж ця фітнес-функція дозволяє задавати бажане співвідношення точності класифікації та кількості факторів ризику.
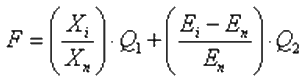 , , |
(1) |
где Xi – кількість присутніх факторів ризику в i-ій хромосомі, Xn – максимальна кількість факторів ризику, Ei – помилка навчання НС для i-ї хромосоми, En – помилка навчання НС при використанні максимальної кількості факторів, Q1 і Q2 – коефіцієнти, за допомогою яких регулюється співвідношення між точністю класифікації і числом факторів ризику. Рекомендується вибирати діапазон значень (2), і дотримуватися умови (3).
| |
(2) |
| |
(3) |
Після етапу підготовки даних отримали навчаючий масив розміром 99 х 100, де 99 вхідних параметрів і 100 навчальних прикладів. Дана вибірка розділена на дві – по 50 прикладів у кожній. По першій вибірці проводилося навчання нейронної мережі та відбір ознак за допомогою генетичних алгоритмів. В результаті кількість факторів зменшилася практично у два рази. Потім, на другий вибірці успішно протестована нейронна мережа, з використанням тільки виділених факторів.
4.3 Генетичні алгоритми
Генетичні алгоритми (ГА) використовують принципи і термінологію, запозичені у біологічної науки – генетики. У ГА кожна особина представляє потенційне рішення деякої проблеми. У класичному ГА особина кодується рядком двійкових символів – хромосомою, кожен біт якої називається геном. Безліч особин - потенційних рішень складає популяцію. Пошук (суб) оптимального рішення проблеми виконується в процесі еволюції популяції – послідовного перетворення однієї кінцевої множени рішень в іншу за допомогою генетичних операторів репродукції, кросинговеру та мутації.
ГА бере безліч параметрів оптимізаційної проблеми і кодує їх послідовностями кінцевої довжини в деякому кінцевому алфавіті (у простому випадку двійковий алфавіт «0» і «1»).
Попередньо простий ГА випадковим чином генерує початкову популяцію стрінгів (хромосом). Потім алгоритм генерує наступне покоління (популяцію), за допомогою трьох основних генетичних операторів:
- Оператор репродукції (ОР).
- Оператор кросинговеру (ОК).
- Оператор мутації (ОМ).
Генетичні оператори є математичної формалізацією наведених вище трьох основоположних принципів Дарвіна, Менделя і де Вре природної еволюції.
ГА працює до тих пір, доки не буде виконано задану кількість поколінь (ітерацій) процесу еволюції або на деякій генерації буде отримано задану якість або внаслідок передчасної збіжності при попаданні в деякий локальний оптимум.
Вперше подібний алгоритм був запропонований в 1975 році Джоном Холландом (John Holland) в Мічиганському університеті. Він отримав назву «репродуктивний план Холланда» і ліг в основу практично всіх варіантів генетичних алгоритмів [6]. Стандартний ГА [4] передбачає наступну послідовність, (мал.3).
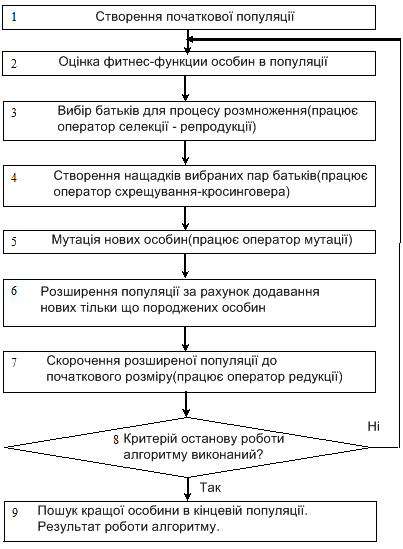
Малюнок 3 – Простий генетичний алгоритм
У кожному поколінні безліч штучних особин створюється з використанням старих і додаванням нових з гарними властивостями. Генетичні алгоритми – не просто випадковий пошук, вони ефективно використовують інформацію, накопичену в процесі еволюції.
На відміну від інших методів оптимізації ГА оптимізують різні області простору рішень одночасно і більш пристосовані до знаходження нових областей з кращими значеннями цільової функції за рахунок об'єднання квазіоптимальних рішень з різних популяцій.
5. Розробка алгоритму відбору оптимальної регресійної моделі за допомогою методу групового обліку аргументів
У більшості випадків, в медичних завданнях, результат прогнозування залежить від великої кількості неоднакових за важливістю факторів, які до того ж можуть бути взаємопов'язані. Цей факт значно ускладнює етап відбору даних, виключаючи можливість використовувати велику частину відомих методів.
Проте виділення факторів ризику є не єдиним завданням, так само необхідно оцінити роль кожного з них. З цього випливає, що значимість кожного фактора на ризик розвитку різних акушерських ускладнень буде різна [1]. Однак, відбір факторів ризику є одним з найважливіших етапів побудови прогнозуючої моделі і в значній мірі визначає її якість. Таким чином, при побудові оптимальної моделі виконаємо і відбір факторів перинатального ризику, з параметрів спочатку запропонованих лікарями, при цьому будемо враховувати взаємопов'язані між собою змінні.
Повний перебір регресійних моделей, навіть у межах заданої опорної функції, при досить великому наборі вхідних параметрів на практиці реалізувати не представляється можливим. Для досить складних задач моделювання (наприклад, великий набір навчальних даних) застосовуються багаторядні алгоритми методу групового обліку аргументів (МГУА) [7]. Багаторядний алгоритм МГУА виключає з перебору деякі моделі завдяки наявності порогів.
Попередньо в багаторядному (пороговому) алгоритмі МГУА на вхід подається деякий вектор вхідних змінних x = x1, x2,..., xn. На першому ряду селекції утворюються «приватні описи» (4) – (6), що об'єднують вхідні змінні по дві:
| |
(4) |
| |
(5) |
...
| |
(6) |
З них вибирається деяке число моделей, що найбільш задовольняють зовнішнім критерієм селекції. У нашому випадку в якості такого критерію буде середньоквадратична помилка (7) на перевіряючих даних.
| |
(7) |
де М – кількість навчальних прикладів, F – отриманий результат, Y – дійсний результат.
На другому ряду утворюються «приватні описи» другого ряду:
| |
(8) |
...
| |
(9) |
...
| |
(10) |
З них також вибирається деяка кількість найкращих для використання в наступному, третьому ряду і т.д. Для кожного ряду знаходиться найкраща (за критерієм селекції) модель (мал. 3). Ряди селекції нарощуються, доки оцінка критерію зменшується («правило останову»). На останньому ряду краща модель буде оптимальною. Коефіцієнти в регресійних моделях розраховуються методом найменших квадратів (МНК).

Малюнок 3 – Многорядний МГУА
(анімація: 6 кадрів, 5 циклів повторення, 32,1 кілобайт)
Висновки
На основі поставлених цілей і задач була розглянута актуальна задача відбору оптимальної регресійної моделі, для прогнозування перинатального ризику включаючи задачу відбору факторів ризику. Надалі планується реалізувати розглянутий математичний апарат і протестувати на реальних медичних даних, наданих співробітниками центру материнства і дитинства. Також планується розробка і впровадження системи прогнозування перинатального ризику.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2013 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Т.А. Васяева Анализ методов отбора факторов риска развития патологий в акушерстве и гинекологии / Т. А. Васяева, Д.Е. Иванов, И.В. Соков, А.С. Сокова // Збірка матеріалів ІІ Всеукраїнської науково-технічної конферен.
- Т.А. Васяева Отбор факторов риска потери крови при родах / Т.А. Васяева, Д.Е. Иванов, И.В. Соков. // Інтелектуальні системи прийняття рішень і проблеми обчислювального інтелекту: Матеріали міжнародної наукової конференції. – Херсон: ХНТУ, 2011. – № 1. – 472 с.
- Д. Рутковская Нейронные сети, генетические алгоритмы и нечеткие системы / Д. Рутковская М. Пилиньский, Л. Рутковский. – М.: 2004. – 452 c.
- Ю.О. Скобцов Основи еволюційних обчислень / Ю. О. Скобцов. – Донецьк: ДонНТУ, 2009. – 316 с.
- Саймон Хайкин Нейронные сети: полный курс, 2-е издание. : Пер. с англ. – М. : Издательский дом «Вильямс», 2006. – 1104 с.
- Г.К. Вороновский Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / Г.К. Вороновский, К.В. Махотило, С.Н. Петрашев, С.А. Сергеев // заказное. – Х.: ОСНОВА, 1997. – 112 с.
- Радзинский В.Е. Акушерский риск. Максимум информации минимум опасности для матери и младенца. / В.Е. Радзинский, С.А. Князев, И.Н. Костин. - Изд: Эксмо.. - 2009 г. - С. 285
- Ивахненко А.Г. Самоорганизация прогнозирующих моделей / Ивахненко А.Г., Мюллер И.А. - К: Техника, 1985.. - 223 с.
- МГУА [Электронный ресурс]. – Режим доступа: http://www.gmdh.net/gmdh.htm.
- Метод наименьших квадратов [Электронный ресурс]. – Режим доступа: http://users.kpi.kharkov.ua/fmp/biblio/book1/2-3.html.