Корпус украинской эфирной речи
Вступление
Речевые корпуса играют большую роль при разработке речевых информационных техноло- гий. Информация, которая содержится в таких корпусах, используется для построения акустических и лингвистических моделей для построения как систем наговаривания речи, так и моделей диалога человека с машиной, а также моделей предметных об- ластей для смысловой интерпретации речи. Особые требования предъявляются к кор- пусам, которые разрабатываются для высококачественных систем автоматического распознавания речи и озвучивания текстов. Каждый корпус создаётся с определённой целью, которая учитывает определённую специфику научных исследований или разра- батываемых прикладных систем. Создание данного корпуса длится уже около двух лет. Результат этой работы — пилотная версия корпуса эфирной речи. Цель данной работы — описание структуры корпуса, средств формирования корпуса, первых конкретных результатов анализа и использования речевого материала, а также перспек- тив дальнейших исследований.
Опыт создания речевых корпусов в Украине
Речевой корпус состоит из структурированного множества речевых фрагментов, описания этих фрагментов, а также компьютерных средств для оперирования со всем множест- вом данных корпуса.
Речевой фрагмент как базовая единица корпуса — это оцифрованный фрагмент речевого сигнала, который сопровождается ассоциированной информацией определённого типа (типов). Такая информация называется аннотацией речевого фрагмента [1]. Создание акустических корпусов — достаточно сложная научная и технологическая задача, которая требует значительных ресурсов. В 90-е гг. ХХ в. во многих странах были созда- ны координационные центры для сбора, хранения и распространения общедоступных и стандартизированных корпусов, в том числе и речевых [2]. Создание акустических корпусов становится самостоятельным направлением речевых технологий. В Украине первые корпуса речи были созданы в 70-е гг. прошлого столетия для тестиро- вания и оценки показателей систем распознавания речи на одинаковом стандартном речевом материале. Корпус из 1 тыс. отдельных слов использовался для тестирования системы распознавания на основе ЭВМ БЭСМ-6, при этом была достигнута точность распознавания в 96% при словаре в 1 тыс. слов [3]. Также для тестирования кооператив- ной (многодикторной) системы распознавания была накоплена выборка из 1600 реали- заций из словаря в 100 слов для 6 дикторов. Было показано, что метод кооперативного обучения позволяет достичь 92% точности распознавания речи диктора, не входящего в кооператив [4].
В 90-е гг. ХХ в. для тестирования распознавания ключевых слов была записана английская слитная речь 11 дикторов длительностью в 3500 слов и размечена экспертами на от- дельные слова, а часть материала — для обучения на отдельные фонемы [5]. Толчком в развитии пофонемного распознавания украинской речи послужил однодикторный корпус, содержащий более 6 тыс. изолированных слов, в значительной мере покрыва- ющих фонетическое разнообразие языка. Акустическая модель, созданная на основе этого корпуса, позволила превысить надёжность 95% на словаре 3 тыс. слов. Также, начиная с 2004 года, успешно демонстрировалась базовая технология фонетического стенографа, как одно из достижений Государственной научно-технической программы «Образный компьютер».
Создание алгоритма распознавания речи из сверхбольших словарей (до 2 млн слов) по- требовало накопление корпуса речи в 14 тыс. слов и сочетаний слов. Была достигнута точность распознавания в 99,9% для словаря в 1 тыс. слов, а также точ- ность в 85% для словаря в 2 млн слов при среднем времени распознавания в 7 сек. [6].
Многодикторный корпус «UkReco» содержит более 30 тыс. реализаций фонети- чески сбалансированных слов и фраз, записанных от около 100 дикторов из разных регионов Украины. Этот корпус используется для распознавания изолированных слов, адаптации на голос диктора, а также для построения акустических моделей для словаря-переводчика [7]. Другой размеченный корпус речи, записанной через телевизионную сеть, состо- ит из выступлений около 330 депутатов Верховной Рады Украины. Речь де- путатов отличается быстрым темпом, спонтанностью и эмоциональностью. Объём обучающей выборки — 54 часов речи, контрольной — 11 часов речи. Средняя точность распознавания для контрольной выборки составила 71% [8].
Для исследования методов послогового и морфемного распознавания речи был накоплен корпус из более 35 часов читаемой речи одного диктора [9]. Интересное направление использования корпусов речи — их использование для синтеза речи. Такие корпуса предъявляют особые требования к каче- ству записи и подробности описания речевого сигнала. Для озвучивания украиноязычных текстов был записан женский голос профессионального диктора в студийных условиях [10].
Опыт, накопленный в предыдущих разработках, стал неоценимым при создании концепции данного корпуса эфирной речи.
Структура и состав акустического корпуса
Акустический корпус украинской эфирной речи (Акустичний корпус українського ефірного мовлення — АКУЕМ) — общий по цели своего применения акусти- ческий корпус, который содержит читаемую, подготовленную и спонтанную речь (последнее составляет самую большую часть корпуса). Все материалы корпуса по типу речевого сигнала разделяются на телеи радиовещание, также присутствуют небольшие вкрапления записи публичной речи и речи в естественной среде. Основные языки материалов корпуса — украинский и русский.
В АКУЕМ вошли материалы разной тематики и жанров, но основу корпуса со- ставили звуковые записи рубрик: новости и интервью (политика, культура, образование, общество и т.д.), телепередачи и телетрансляции (судебные заседания, политические дебаты, публичные выступления и др.). В целом корпус должен отображать полную картину речи украинского телеи ради- оэфира, поэтому работы над его пополнением будут вестись и в дальней- шем. В настоящее время количественное распределение звуковых записей по жанрам неравномерно. Это связано с первоочерёдностью отбора рече- вого материала определённой тематики, необходимой для работ по созда- нию системы распознавания речи (см. рис. 1).
На данный момент корпус украинской эфирной речи характеризуется следую- щими количественными показателями: более 260 часов аннотированной речи, словарь корпуса содержит почти 45 000 слов украинского языка и по- чти 50 000 слов русского языка, более 1500 тыс. дикторов. Среди записей встречается речь дикторов разного возраста, пола, социального положения и профессий, что отражает состав дикторов телевизионного эфира. Кроме общеупотребительных слов, был создан словарь суржика (более 1700 слов), словарь территориальных и социальных диалектов (более 800 слов).
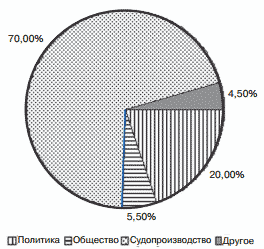 Рисунок 1 – Cоотношение записей разных тематик (по продолжительности)
Рисунок 1 – Cоотношение записей разных тематик (по продолжительности)
Разметка корпуса
Одна из основных черт, которые отличают акустический корпус от обычной коллекции зву- ковых записей или текстов, его разметка (аннотирование) — описание дополнительной информации о речевом сигнале.
Разметка АКУЕМ проводилась экспертами на основании предварительной автоматической разметки. Фактически, эксперт перепроверяет предварительную аннотацию, исправляя ошибки, делая необходимые дополнения, а также добавляя информацию о дикторах.
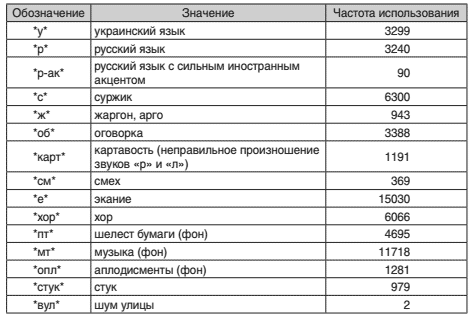
Разметка заключается в сегментировании речевого материала и детальном описании опре- делённых лингвистических и экстралингвистических явлений в речевых фрагментах. Для внесения дополнительной информации в текст используются специфицированные теги, которые отделяются от текста знаком *. На данный момент используется 74 таких метаобозначения.
Все обозначения можно разделить на несколько групп: • обозначения языка; • обозначения нелитературных слов; • обозначения способа произношения слов; • обозначения фона; • обозначения неинформативных слов и звуков, которые произносит диктор; • обозначения диалогов и хоров; • обозначения шума.
Обозначения языка касаются всех последующих слов до альтернативного обозначения, и ставятся перед первым словом соответствующего языка. В АКУЕМ в настоящее вре- мя встречаются записи девяти языков, хотя основной объём (более 97%) составляет украинский и русский языки.
Следующая группа обозначений предназначена для слов, отсутствующих в литературных словарях: • суржик — смесь украинского и русского языков; • социальные диалекты (жаргон, арго) — языки людей, связанных определённой об- щностью профессиональных или социальных интересов; • территориальные диалекты — языки лиц, связанных между собой территориальной общностью; • аббревиатуры и сокращения.Обозначения способа произношения слов включают обозначения дефектов речи (заикание, картавость и др.), речевых сбоев (обрывы и оговорки), специ- фического произношения слов (например, послогового, с редуцированием или с растягиванием). Все эти обозначения касаются только одного слова и ставятся перед соответствующим словом.
Обозначения неинформативных слов и звуков, которые произносит диктор, включают обозначения заполненных пауз, звуков-паразитов и подобных явлений. К этой же группе относятся неинформативные звуки, например покашливание, шмыганье носом, смех, плач, громкий вдох или выдох дик- тора. Такие обозначения ставятся на месте соответствующего звука и обо- значают соответствующие звуки в записи, которые произносит диктор. Эта группа обозначений самая большая.
Обозначения диалогов соответствуют местам в звуковых записях, где так или иначе сливается речь нескольких дикторов. Диалог — места, где во вре- мя разговора двух дикторов конец фразы первого диктора накладывается на начало фразы другого диктора. Хор — полное наложение речи несколь- ких дикторов.
Важная группа обозначений, которые описывают звуковые сегменты корпуса, — обозначения фона, на котором говорит диктор, и разнообразных шумов, которые присутствуют в сегментах. Такие обозначения касаются целого сегмента речи.
Примеры обозначений и частота их использования приведены в таблице 1.
Целевая аудитория АКУЕМ
Целевая аудитория проекта в первую очередь — разработчики систем автомати- ческого распознавания украинской и русской речи. АКУЕМ предназначен для обучения и тестирования таких систем распознавания речи. Современным статистическим системам распознавания речи необходим большой объём акусти- ческих материалов для построения акустических и лингвистических моделей (далее АМ и ЛМ) речи, а также для тестирования надёжности распознавания речи.
На материалах корпуса проводятся многочисленные научные эксперименты в области рас- познавания речи, например, выявление и классификация экстралингвистических рече- вых явлений, исследование реальных акустических условий речи, исследование раз- личных вариантов произношения дикторов, изучение специфики устной спонтанной речи на разных уровнях и много других.
АКУЕМ отображает современную языковую ситуацию в Украине, включает как литературный, так и разговорный стиль речи. Поэтому корпус может служить основой для широкого спектра исследований в области лингвистики, диалектологии, речевой акустики, психо- акустики, фонетики, фонологии и других областях науки.
Программное обеспечение корпуса
Эффективное создание корпуса невозможно без развитого инструментария. К этому инстру- ментарию относятся программные средства для стенографирования звуковых записей, дальнейшего их сегментирования и аннотирования (транскрибирования), автоматиче- ского исправления транскрипций, статистического анализа результатов сегментирова- ния, а также подготовки материала к обучению распознавания.
Средства стенографирования звукозаписей
Стенографирование производится средствами протоколирования событий SRS-Femi da [11]. Стенографист создаёт транскрипцию звукозаписи с уровнем детализации, которая вклю- чает признаки языка и говорящего. С помощью ножной педали осуществляется предварительное разделение на речевые сегменты, которые отвечают смене гово рящего. Видеоряд, который сопровождает звукозаписи, облегчает определение дик- тора. Кроме этого, указываются участки сигнала, где речь неразборчивая, перекрывается шумами или отсутствует. Для обеспечения орфографической правильности набранного текста используются стан- дартные средства проверки орфографии, адаптированные к специфике стенограмм: учитываются обозначения языковых признаков и добавляются признаки отклонения от нормативов литературного языка для соответствующих слов.
Средства сегментирования
Сегментирование выполняется средствами программного обеспечения с открытым кодом Transcriber 1.5.1 [12] (см. рис.2), адаптированного к кириллице. Подготовленный спе- циалист с соответствующим уровнем лингвистического и компьютерного образования углубляет детализацию транскрипции, полученной в результате стенографирования звукозаписей. Проводится тщательное разбиение по паузам речевых сегментов, син- хронизация их с соответствующим текстом. Кроме этого, в текст вставляются деталь- ные признаки-теги, которые касаются как отдельных слов и звуков, так и речевого сег- мента в целом. Дальнейший анализ сегментирования состоит в выявлении и исправлении типичных оши- бок и внесении некоторых регулярных изменений, обусловленных как непрерыв- ным развитием концепции корпуса, так и появлением различных версий использова- ния корпуса.
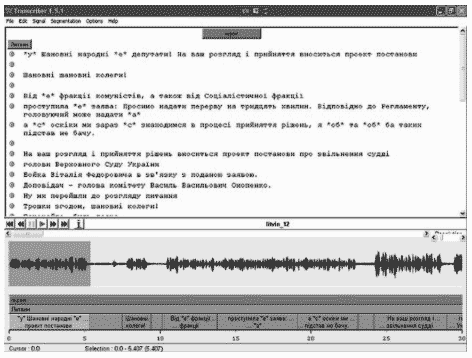 Рисунок 2 – Диалоговое окно эксперта в программе Transcriber
Рисунок 2 – Диалоговое окно эксперта в программе Transcriber
Средства статистического анализа
ля анализа накопленного материала производится подсчёт различных стати- стик, в частности формируются: • частотные словари для разных языков, которые встречаются в корпусе; • частотные словари суржика, социальных и региональных диалектов, аб- бревиатур, редуцированных слов и др.; • статистика длин речевых сегментов для каждого звукового файла, а так- же общая статистика; • статистика длин речевых сегментов для каждого диктора в отдельности.
Средства подготовки к обучению распознавания речи
Кроме указанного выше, производится формирование звуковых файлов, приме- нимых для обучения и распознавания речи. При этом каждому звуковому фрагменту соответствует текстовая запись и имя диктора. Словарь системы распознавания дополнен словами, которые отвечают неинфор- мативным звукам (например, заполненные паузы) и, соответственно, во время формирования текста фразы эти звуки рассматриваются как отдель- ные слова. Были проведены эксперименты по обучению таким звукам-сло- вам, и результаты показали высокую точность их определения (около 80%). Обозначения, которые характеризуют целый сегмент, например, *стук*, *вул*, предлагается использовать для построения моделей гауссовских смесей (GMM) для того, чтобы система распознавания определяла такие сегменты и относила их к соответствующему классу.
Информацию о дикторе предлагается использовать для настраивания системы распознавания на кластеры дикторов. Это позволит повысить точность распознавания за счёт предварительного определения кластера дикторов и использования индивидуальной акустической модели для данного кластера.
Предварительные эксперименты по распознаванию слитной речи
1. Речевой материал
Для экспериментов по распознаванию речи, относящейся к судебной тематике, использова- лась только часть аудиофайлов. Это в основном записи телепередач «Судові справи» («Судебные дела»). Речь, звучащую в этих телепередачах, можно назвать спонтанной по форме, но не по содержанию, поскольку дикторы говорили в рамках соответствую- щих ролей. Кроме этого, часть аудиофайлов содержит записи реальных судебных засе- даний, в которых присутствует как спонтанная речь судьи, так и неподготовленное (и, таким образом, приближенное к спонтанному) чтение протоколов.
Речевой материал, использованный для построения АМ, состоял из аудиозаписей (длитель- ностью около 52 часов), в которых содержится речь около 1500 дикторов. Распределе- ние неравномерное: большинство дикторов представлено короткими записями, однако, у 150 дикторов длительность записей составляет более 10 минут.
2. Текстовый материал
Текстовый материал, использованный для построения лингвистических моделей, состоит из текстов, загруженных из Интернета (400 Mбайт). Загруженный текст был модифици- рован для того, чтобы убрать служебную информацию, записать числа в текстовом виде, а также отделить тексты на разных языках. В дополнение к этим текстам использова- лись также расшифровки звукового материала из обучающей выборки АКУЕМ.
3. Контрольная выборка
Для распознавания использовались записи длительностью 3,74 часа, в которых встретилось 29 500 слов. Всего в контрольной выборке присутствовала речь 34 дикторов. Темп про- изнесения — средний и быстрый.
4. Система распознавания речи
Для исследований использовался инструментарий HTK [13]. На его основе была создана мно- годикторная система распознавания речи. В качестве АМ используются скрытые Марковские модели, обученные на обучающей выбор- ке. 56 украинских контекстно-независимых фонем (включая фонему-паузу) моделируют- ся тремя состояниями Марковской цепи без пропусков. Используется диагональный вид Гауссовских функций плотности вероятности. Редко встречающиеся фонемы моделиру- ются 64 смесями Гауссовских функций плотности вероятности, более часто встречаю- щиеся фонемы моделируются большим числом смесей, наиболее часто встречающиеся фонемы используют 1024 смесей. В качестве лингвистической модели языка использовалась биграммная статистическая мо- дель. Словарь распознавания, используемый наряду с уже обученными ЛМ и АМ, насчитывал 42 598 словоформ. Произнесение каждой словоформы было представлено транскрип- цией, несколько отличающейся от канонической (литературной). А именно, однослож- ные словоформы представлены двумя транскрипциями (ударный и безударный вариан- ты), а также упрощены некоторые сочетания согласных в соответствии со спонтанным произнесением (например, «дч» → «чч» вместо канонического «джч»). Результаты распознавания приведены в таблице 2. Заметим, что в контрольной выборке на- ряду с записями телепередач присутствуют записи реального судьи Ш.
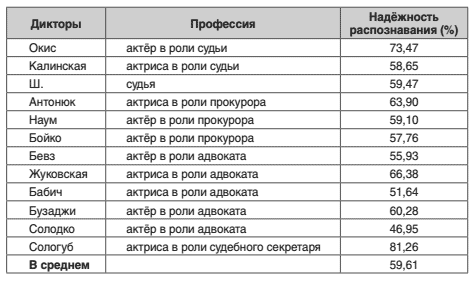 Таблица 2 – Результаты распознавания речи
Таблица 2 – Результаты распознавания речи
Выводы
Разработанная пилотная версия АКУЕМ позволяет строить акустические и до- полнять лингвистические модели для исследования по автоматическому транскрибированию звуковых сигналов, для поиска ключевых слов, а также для распознавания дикторов.
Дальнейшие исследования предусматривают построение информационно-пои- сковой системы на основе веб-интерфейса, который позволит пользовате- лям ориентироваться в речевом материале и находить в нём нужную ин- формацию более эффективно. Также полезными могут оказаться средства для синхронизации текстовых и речевых материалов.
Несмотря на сложность и трудоёмкость, мы надеемся создать полноценный ре- сурс, который станет основой для многих речевых технологий и систем, которые могут использоваться во многих сферах экономики, образования, права и повседневной жизни. Материал корпуса состоит из разнообразных звуковых записей вместе с их расшифровкой и может стать частью Нацио- нального корпуса украинского языка.
Литература
1. Кривнова О.Ф. Речевые корпуса на новом технологическом витке // Ре- чевые технологии. 2008. № 2. С. 13–24. 2. К ривнова О.Ф., Захаров Л.М., Строкин Г.С. Речевые корпусы (опыт раз- работки и использование) // Труды семинара Диалог’2001. Mосква, 2001. 3. Винцюк Т.К., Шинкаж А.Г. Распознавание 1000 слов // Автоматическое распознавание слуховых образов. Тбилиси, Мецниереба, 1978. 4. Винцюк Т.К., Куляс А.И., Людовик Е.К., Шинкаж А.Г. Кооперативная система распознавания речи // Автоматическое распознавание слуховых образов. Ереван, 1980. 5. Вінцюк Т., Біднюк С., Куляс А., Пилипенко В., Дослідження з розпізнаван- ня ключових слів у потоці зв'язного мовлення // Праці першої всеукраїнської конференції УкрОБРАЗ 92. Київ, 1992. С. 125–128. 6. Pylypenko V. Information Retrieval Based Algorithm for Extra Large Vocabulary Speech Recognition // Proc. of the 13th International Confe 7. Сажок М., Селюх Р., Юхименко Ю. Адаптація акустичних моделей фонем до голосу диктора для пофонемного розпізнавання ізольованих слів української мови // Штучний інтелект. Донецьк, 2009. № 4. С. 230–233. 8. Васильєва Н., Сажок М. Порівняння пофонемного та поскладового розпізнавання мовленнєвого сигналу для української мови // Праці десятої всеукраїнської міжнародної конференції УкрОБРАЗ, Київ, 2010. С 49–54. 9. Радуцький О. , Богданов Л. Технічна фіксація судових процесів: системний підхід до розвитку комп’ютерних технологій та інформаційних ресурсів // Юридичний журнал. 2002. № 2. http://www.justinian.com.ua/article.php?id=431 10. Young S. et al. The HTK Book (for HTK Version 3.4) // Cambridge University Engineering Department: Cambridge, UK, 2009. http://htk.eng.cam.ac.uk/