
Kate Kisnichenko
Faculty of computer science and technology (CST)
Department of artificial intelligence systems
Speciality Artificial Intelligence Systems
Development and research of algorithm of forming of semantic kernel of web site on the basis of methods of Data Mining
Scientific adviser: d.f.-m.s., prof. Vladislav Shelepov
Abstract
Introduction
1. Relevance of the topic
2. The purpose and tasks of the research
3. Analysis of the search engines and the traditional approach to the development of semantic site
4.The algorithm for generating a semantic core for sites with dynamic content
Conclusion
References
Introduction
The Internet represents an extensive information field, the huge knowledge base containing detailed data of scientific, historical, political, daily character. The Internet can be compared to the huge dictionary describing our planet and all processes, accompanying development of a human civilization which occurred, occur and can occur in the future.
Today practically all information available in a world wide web doesn't contain semantics and consequently its search, relevant to inquiries of the user, and also integration within concrete subject domain are complicated. For ensuring effective search, the Web application should understand accurately semantics of the documents presented in a network. In this regard, it is possible to observe rapid growth and development of the Semantic Web technologies, occurring now. The consortium W3C developed the concept which is based on active use of metadata, language of a marking of XML, the RDF language (by Resource Definition Framework – the Environment of the Description of the Resource) and an ontologic approach. All offered means allow carrying out data exchange and their repeated use.
1. Relevance of the topic
In the age of information technology business success largely depends on the way the virtual representation of the company on the Internet. At the same time to develop content for the Web resource firm is to provide information that would be able to force the user to think and behave in a direction favorable to the real business. On the other hand, it is known that the proportion of "search traffic" any website (the number of visitors coming from the SERP to the total site traffic) is predominant. Therefore, when developing the site content a lot of attention is paid to the search engine optimization (seo – search engine optimization) – a package of measures aimed at the promotion of a web resource to the top positions of search engines (SEs) in order to increase its attendance. One of the key stages of SEO is to develop a semantic core (SC) of the site, which is typically performed manually by experts and is time–consuming [1,2].
Semantic core – a set of keywords and phrases that users request in the search engines for finding information directly related to the content of the resource. This kernel key – the basis of internal optimization of website: a meta–descriptions, text, header tags and tag accent.
Manual approach is unacceptable to create a semantic core for sites with dynamic content because of the large time lag in updating SC SEO–specialists preferences and the complexity of user actions. Therefore, the actual algorithm is the creation and development practices SC, the use of which would reduce the time to achieve and maintain a leading site positions in search results.
2. The purpose and tasks of the research
Objective is to develop and study formation algorithm semantic core sites with dynamic content based on Data Mining.
For achievement of a goal it is necessary to solve the following problems:
– to consider appointments and classifications of ontologies;
– analyze the application of ontologies;
– to consider languages of the description of ontologies;
– to carry out the analysis of existing methods of automatic creation of ontologies;
– to realize automatic creation of ontology on the basis of results of a preliminary clustering of a collection of text documents.
3. Analysis of the search engines and the traditional approach to the development of semantic site
PC is a site consisting of a web interface for the user and the search engine, which is the engine that provides the functionality of the PC. The search engine consists of a module indexing database (DB) of indexed documents and search engine, to analyze and process user requests. Indexing module consists of three auxiliary programs (robots) – spider (spide), crawler (spider traveling) and indexer (indexer). Spider downloads web documents using the HTTP protocol, extracts links and redirects, and saves the text in the following format: URL, date, download, http–server response header, the body page (html–code). Crawler processes found spider links and provides further direction spider. Indexer parses the html-code of the page into its component parts, such as titles (title), subtitles (subtitles), meta tags (meta tags), text, links, structural and stylistic features, etc., analyzes them based on various lexical and morphological algorithms for the subsequent rank of importance. Thus the found words and phrases are assigned weighting factors depending on how many times, and where they meet (in the page header to the beginning or end of the page to link to the meta tag, etc.). As a result, a file containing code which can be quite large. To reduce its size resort to minimize the amount of data compression and file, as well as solve the problem of determining duplicates and "almost duplicates". Indexing results stored in the database (DB) of indexed documents (Pic.1).
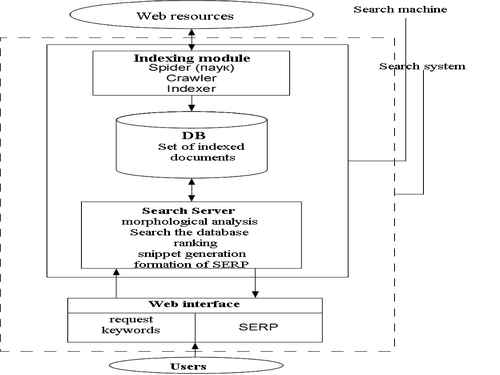
Picture 1 – Stages of the search engine
The first step is to determine the main directions of the site, select its type (online shop, a news blog, online business card, etc.), themes, structure, target audience and the need for user feedback. The next step is to create the initial list of queries that will be set keyword list.
The second stage of the most time–consuming. All queries users enter into search engines, can be divided into:
• High Frequency (HF);
• medium frequency (MF);
• low–frequency (LF)
Request referred to one group or another, depending on how often users type it in the search engines. Certain limits and boundaries separating HF from MF and MF from LF query does not exist. They strongly depend on the topic, but is generally considered low–frequency queries that are gaining up to 500–700 times per month; midranges – 1–2 thousand times per month; high frequency – more than two thousand times a month [18].
In compiling semantic site can not be used only frequency of a word. They should also determine how hard it will be to compete fee for this request. Therefore it is necessary to introduce three more groups of queries:
• highlycompetitive (HC);
• mediumcompetitive (MK);
• lowcompetitive (LC).
If we define the word frequency is quite simply, the degree of competition is often difficult to assess. Based on this is often considered highly competitive and high demands, mid – mediumcompetitive and bass – lowcompetitive.
4. The algorithm for generating a semantic core for sites with dynamic content
To reduce the time for developing and updating the SCS with dynamic content without loss of completeness and accuracy, you can use the analysis of the relationship (link analysis), allows you to generate a quantitative description of the rules of interconnection between two or more keywords are combined into a single semantic query. Such rules in terms of analysis of the links are called associative, and the request is a certain set of events occurring together, and forms a transaction.
Algorithm development and updating automation SC by applying analysis of the links to search the database transactions can be represented as a sequence of the following steps:
1. Evaluation of the site content and search trends study to determine the initial list of search transactions;
2. With the tools of statistics compiling a list of search engines queries associated with the specified frequency keywords;
3. Formation of a database search transactions of a given species based on a list of associated queries;
4. Search popular sets in BPT and establishment of popular search transactions;
5. On the basis of the formation of base TCAP possible implications of the "ondition–investigation", the calculation of their support and confidence and establishment of association rules;
6. Formation of meta tags (Title, Description, Keywords) and modification of the site content.
Conclusion
As algorithm of a clustering the algorithm of LSA/LSI is offered. The algorithm of LSA/LSI is a realization of the basic principles of the factorial analysis applicable to a set of documents. This method of a clustering allows to overcome successfully the sinonimiya and homonymy problems inherent in the text case being based only on statistical information on a set of documents/terms.
References
1 Паклин Н.Б. Бизнес-аналитика: от данных к знаниям/Н.Б. Паклин, В.И. Орешков. – СПб.: Питер, 2009. – 624 с.
2. Chung D. Suchmaschinen-Optimierung: Der schnell Einstieg/D. Chung, A. Klunder. – Heidelberg: REDLINE/mitp, 2007. – 224 S.
3. Сирович Дж., Дари Кр. Поисковая оптимизация на PHP для профессионалов. Руководство разработчика по SEO. Professional Search Engine Optimization with PHP: A Developer's Guide to SEO. M.: Диалектика, Вильяме, 2008. - 352 с.
4. Байков В. Д. Интернет. Поиск информации. Продвижение сайтов. — СПб.: БХВ-Петербург, 2000. 288 с.
5. Колисниченко Д. Н. Поисковые системы и продвижение сайтов в Интернете. М.: Диалектика, 2007. - 272 с.
6. Евдокимов Н. В. Раскрутка Web-сайтов. Эффективная Интернет-коммерция. М.: Вильяме, 2007. - 160 с.
7. Евдокимов Н., Лебединский И. Раскрутка веб-сайта. Практическое руководство. М.: Вильяме, 2011. - 288 с.
8. Евдокимов Н.В. Основы контентной оптимизации. Эффективная интернет-коммерция и продвижение сайтов в интернет. М: Вильяме, 2007. - 160 с.
9. Ашманов И.С., Иванов A.A. Оптимизация и продвижение сайтов в поисковых системах. СПб.: Питер, 2009. - 400 с.
10. Яковлев А. А. Раскрутка и продвижение сайтов: основы, секреты,трюки. СПб.: БХВ-Петербург, 2007. - 336 с.ч
11. Яковлев А., Ткачев В. Раскрутка сайтов. Основы, секреты, трюки. -СПб.: БХВ-Петербург, 2010. 352 с.
12. Agrawal R., Srikant R. Searching with numbers // In Proceedings of the eleventh international conference on World Wide. ACM Press, 2002.
13. Aizawa A. The feature quantity: an information theoretic perspective of tfldf-like measures // In Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval.
14. Тероу Ш. Видимость в Интернете. Поисковая оптимизация сайтов. = Search Engine Visibility. Б. м.: Символ-Плюс, 2009. - 288 с.
15. Арсирий Е.А., Игнатенко О.А., А.А. Леус Разработка семантического ядра сайта с динамическим контентом на основе ассоциативных правил // 2012, Том 2, №1
16. Павленко А. И. Ранжирование факторов продвижения интернет-магазина с помощью аппарата мультимножеств// реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2009.
17. Халыгов А. А. Методы повышения скорости ранжирования сайтов в поисковой системе Google// реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2013.
18. Как составить семантическое ядро сайта [Electronic resource]. – Аccess mode: great-world.ru
19. Deductor Academic [Electronic resource].– Аccess mode: basegroup.ru
Important note
This master's work is not completed yet. Final completion: December 2014. The full text of the work and materials on the topic can be obtained from the author or his head after this date.