
Кісніченко Катерина Олександрівна
Факультет комп'ютерних наук та технологій
Кафедра систем штучного інтелекту
Спеціальність Системи штучного інтелекту
Розробка і дослідження алгоритму формування семантичного ядра веб–сайту на основі методів Data Mining
Науковий керівник: д.ф.–м.н., проф. Шелепов Владислав Юрійович
Реферат за темою випускної роботи
Вступ
1. Актуальність теми
2. Мета і задачі дослідження
3. Очікувана наукова новизна
4. Огляд досліджень та розробок по темі
4.1 Глобальний рівень
4.2 Національний рівень
4.3 Локальний рівень
5. Аналіз роботи пошукових систем і традиційного підходу до розробки семантичного ядра сайту
6.Алгоритм формування семантичного ядра для сайтів з динамічним контентом
7. Напрями подальших досліджень
Висновки
Список джерел
Вступ
Інтернет – це велике інформаційне поле, величезна база знань, що містить докладні відомості наукового, історичного, політичного, повсякденного характеру. Інтернет можна порівняти з величезним словником, що описує нашу планету і всі процеси, що супроводжують розвиток людської цивілізації, які відбувалися, відбуваються і можуть відбутися в майбутньому.
На сьогоднішній день практично вся інформація, яка доступна у Інтернет не містить семантики і тому її пошук, релевантний запитам користувача, а також інтеграція в рамках конкретної предметної області ускладнені. Для забезпечення ефективного пошуку, веб–програма повиненна чітко розуміти семантику документів, представлених в мережі. У зв'язку з цим, можна спостерігати бурхливий ріст і розвиток технологій Semantic Web, що відбувається в даний час. Консорціумом W3C була розроблена концепція, яка базується на активному використанні метаданих, мові розмітки XML, мові RDF (Resource Definition Framework – Середа Опису Ресурсу) і онтологічному підході. Всі запропоновані засоби дозволяють здійснювати обмін даними та їх багаторазове використання.
1.Актуальність теми
У століття інформаційних технологій успіх бізнесу значною мірою залежить від способів віртуального представлення фірми в мережі Інтернет. При цьому метою розробки контенту веб-ресурсу фірми є надання інформації, яка була б здатна змусити користувача думати і вести себе в напрямку, вигідному реальному бізнесу. З іншого боку, відомо, що частка "пошукового трафіку" будь–якого сайту (відношення числа відвідувачів, що прийшли від пошукових видач, до загальної відвідуваності сайту) є переважаючою. Тому при розробці контенту сайту велика увага приділяється пошукової оптимізації (seo – search engine optimization) – комплексу заходів, спрямованих на просування веб–ресурсу до верхніх позиціях пошукової системи (ПС) з метою збільшення його відвідуваності. Одним з ключових етапів SEO є розробка семантичного ядра (СЯ) сайту, яка, як правило, виконується фахівцями вручну і вимагає великих тимчасових витрат [1,2].
Семантичне ядро – такий набір ключових слів і словосполучень, які запитують користувачі в пошукових системах, на етапі пошуку інформації, безпосередньо пов'язаної з вмістом ресурсу. Дане ядро ключів – основа внутрішньої оптимізації сайту: мета–описів, текстів, тегів заголовків і тегів акцентування.
Ручний підхід неприйнятний при створенні семантичного ядра для сайтів з динамічним контентом через велику тимчасового запізнювання в оновленні СЯ SEO–фахівцями, складності обліку переваг і дій користувачів. Тому актуальним є створення алгоритму та методики розробки СЯ, застосування яких дозволило б скоротити час на досягнення і підтримку лідируючих позицій сайту в пошукових ведучих.
2.Мета і задачі дослідження
Мета роботи полягає у розробці та дослідженні алгоритму формування семантичного ядра сайтів з динамічним контентом на основі методів Data Mining.
Для досягнення поставленої мети необхідно вирішити такі завдання:
– проаналізувати роботу пошукових систем та встановити зв'язок між етапами і процедурами роботи ПС і розробкою СЯС;
– розглянути традиційні алгоритми формування СЯ;
– визначити вимоги до формування транзакционной бази даних в термінах аналізу зв'язків і розробити базу даних для пошукових транзакцій;
– розробити алгоритм створення та оновлення СЯ на основі застосування аналізу зв'язків у транзакционной базі пошукових запитів.
3.Очікувана наукова новизна
Модифікований алгоритм розробки та оновлення семантичного ядра сайту, на основі створення асоціативних правил за допомогою алгоритму пошуку популярних наборів в транзакционной базі даних пошукових запитів методами Data Mining.
Пропонований алгоритм може бути впроваджений в системи адміністрування сайтів або в засоби підтримки роботи seo фахівців для підвищення повноти, точності і зниження часу розробки СЯ сайтів з динамічним контентом.
4.Огляд досліджень та розробок по темі
4.1 Глобальний рівень
На ранніх стадіях еволюції пошукових систем враховувалося мала кількість факторів, що впливають на ранжирування у видачі результатів пошуку, тому, знаючи базові принципи роботи пошукових систем, можна було досить легко маніпулювати результатами. При подальшій еволюції число таких факторів зростала в геометричній прогресії, постійно збільшувався рівень конкуренції і, в деякий момент часу, етап розвитку технології просування сайтів вийшов на новий виток – початок автоматизації процесів.
Дослідження роботи пошукових систем [3] і питання підвищення релевантності документів запитам користувачів проводилися В. Д. Байковим [4], Д.Н. Колісниченко, Н.В. Євдокимовим [5, 6, 7, 8], І.С.Ашмановим, AA Івановим, A.A. [9], Яковлєвим [10,11]. У них розглядалися чинники, що впливають на ранжирування в пошукових системах. Формули ранжирування пошукових систем зазнали значних змін за останні 2–3 роки, і результати робіт перелічених вище авторів неактуальні.
У роботах зарубіжних авторів Agrawal R., Srikant R. [12], Aizawa A. [13], Теро Ш. [14] детально розглянуті тонкощі оптимізації сайтів та блогів, а також динамічних сайтів, які забезпечують пошукову видимість в інтернеті текстів, відео та аудіофайлів. Велику увагу приділено проблемі нечистих методів розкрутки сайту, а також рекомендаціям, як, не використовуючи дані методи, розкрутити сайт .
Для побудови семантичного ядра існує ряд програмних інструментів.
Найпростіша, але цілком прийнятна програма для підбору практично всіх наявних запитів в Яндекс.Вордстате – Key Collector (http://www.key-collector.ru/). Вона , за словами розробників, має більше 70 параметрів для оцінки ключових фраз, 4 способи роботи з Яндекс.Вордстатом, а також можливість проведення експрес–аналізу сайту на відповідність семантичному ядру, інтеграції зі посилальними брокерами та багато іншого. За допомогою неї можна вивантажити всі запити, що містять введене вами слово, а також пошукові підказки й запити з правої колонки вордстат. Є докладна інструкція з описом всіх функцій. Програма постійно оновлюється і вдосконалюється.
Другим інструментом для складання семантичного ядра є "Бази Пастухова". Це архів, що складається з ключових слів, які запитують користувачі в Google, Яндексі, Rambler. Тут містяться домени з докладною інформацією про кожного з них. Тобто це не програма, яка парсит Вордстат або пошукові підказки, а база даних ключових слів, які запрошувалися в певний період. Перевагою "Баз Пастухова" є можливість побачити практично всі унікальні користувача запити, яких немає в Яндекс.Вордстате .
4.2 Національний рівень
На національному рівні роботи з розробки семантичних ядер сайтів ведуться в Одеському національному політехнічному університеті авторами Е.А. Арсірій, О.А. Ігнатенко, А.А. Леус [15]. Авторами запропонована методика розробки семантичного ядра сайту на основі створення асоціативних правил за допомогою алгоритму пошуку популярних наборів Apriori в базі даних пошукових запитів.
4.3 Локальний рівень
У Донецькому Національному Технічному Університеті вивченням факторів просування інтернет-магазину за допомогою апарата мультимножин займався Павленко Антон Ігорович [16]. Розробкою методики просування сайту в пошуковій системі Google займався Халигов Артем Азімовіч [17].
5. Аналіз роботи пошукових систем і традиційного підходу до розробки семантичного ядра сайту
ПС являє собою сайт, що складається з веб–інтерфейсу для користувача і пошукової машини, яка є двигуном, що забезпечує функціональність ПС. Пошукова машина складається з модуля індексування, бази даних (БД) проіндексованих документів і пошукового сервера, що займається аналізом і обробкою запитів користувачів. Модуль індексування складається з трьох допоміжних програм (роботів) – spider (павук), crawler (мандрівний павук) і indexer (індексатор). Павук викачує веб – документи за допомогою протоколу НТТР, витягує посилання і перенаправлення і зберігає текст в наступному форматі: URL, дата скачування, http – заголовок відповіді сервера, тіло сторінки (html–код). Crawler обробляє знайдені павуком посилання і здійснює подальший напрямок павука. Indexer розбирає html – код сторінки на складові частини, такі як заголовки (title), підзаголовки (subtitles), метатега (meta tags), текст, посилання, структурні та стильові особливості і т.д., аналізує їх на основі різних лексичних і морфологічних алгоритмів з метою подальшого ранжирування за ступенем важливості. При цьому знайденим словами і словосполученнями присвоюються вагові коефіцієнти залежно від того, скільки разів і де вони зустрічаються (в заголовку сторінки, на початку або в кінці сторінки, на засланні, в метатега тощо). В результаті формується файл, що містить індекс, який може бути досить великим. Для зменшення його розмірів вдаються до мінімізації обсягу інформації та стисненню файлу, а також вирішують завдання визначення дублікатів і "майже дублікатів". Результати індексування записуються в базу даних (БД) проіндексованих документів (рис.1).
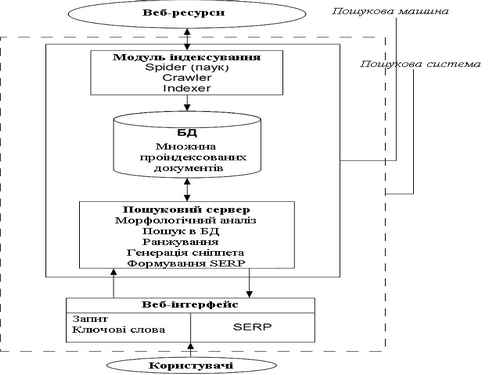
Розробка СЯС складається з ряду інтелектуальних, трудноформалізуемих етапів і процедур, для реалізації яких необхідні великі часові та людські ресурси. Етапи традиційного підходу до створення СЯ представлені на рис 2.
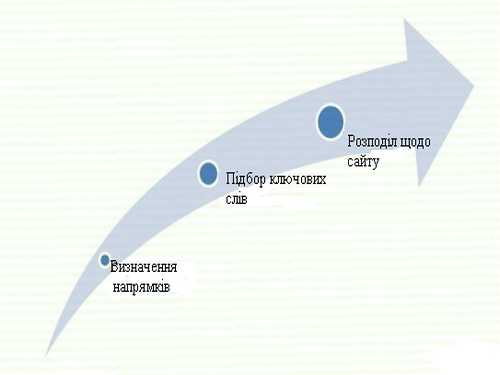
Рисунок 2 – Етапи створення семантичного ядра
На першому етапі необхідно визначитися з основними напрямками сайту, вибрати його тип (інтернет–магазин, новинний блог, сайт – візитка та ін), тематику, структуру, цільову аудиторію і необхідність зворотного зв'язку з користувачами. Наступним етапом буде створення первинного списку запитів, за якими буде встановлюватися список ключових слів.
Другий етап найбільш трудомісткий. Всі запити, що вводяться користувачами в пошукові системи, можна умовно розділити на:
• високочастотні (ВЧ);
• середньочастотні (СЧ);
• низькочастотні (НЧ).
Запит відносять в ту чи іншу групу залежно від того, як часто користувачі набирають його в пошукових системах. Певних рамок і кордонів, що відокремлюють ВЧ від СЧ, а СЧ від НЧ запитів, не існує. Вони сильно залежать від тематики, але зазвичай вважають низькочастотними ті запити, які набирають до 500-700 разів на місяць; середньочастотними – до 1–2 тисяч разів на місяць; високочастотними – понад 2 тисяч разів на місяць [18].
При складанні семантичного ядра сайту не можна використовувати тільки частотність того чи іншого слова. Необхідно також визначити, наскільки важко буде конкурувати при просуванні по даному запиту. Тому варто ввести ще три групи запитів:
• висококонкурентні (ВК);
• середньо–конкурентних (СК);
• низькоконкурентних (НК).
Якщо визначити частотність слів досить просто, то ступінь їх конкурентності оцінити найчастіше вкрай важко. Виходячи з цього часто вважають високочастотні і висококонкурентними запитами, середньочастотні – середньо конкурентних, а низькочастотні – нізкоконкурентним. Однак це не завжди вірно, тому що в деяких тематиках навіть НЧ запити бувають сильно затребувані, і буває зворотна ситуація (але набагато рідше) – по СЧ, за якими дуже легко вийти в ТОП. Найчастіше це слова, написані з помилками, або дуже специфічні запити, що представляють собою URL – адресу відомого ресурсу (наприклад, yandex.ru).
При відборі запитів також необхідно враховувати їх категорію:
1. Первинні запити – запити, що характеризують ресурс "загалом", які є найбільш загальними в тематиці сайту. Наприклад для блогу по seo первинними запитами є: створення сайту, просування сайту, розкрутка сайту, заробіток на сайті, заробіток в інтернеті і т.д.;
2. Основні запити – запити, які будуть входити в список СЯ, ті, за якими доцільно просування. Для попереднього випадку: як розкрутити блог, як створити блог, який створити сайт для заробітку, обмін постовими і т.д.;
3. Асоціативні (допоміжні) запити – запити, які також набиралися людьми, що вводять основні запити. Вони найчастіше бувають схожі з основними запитами. Наприклад, для запиту семантичне ядро сайту асоціативними будуть просування сайту в пошукових системах, внутрішня оптимізація, сео.
Запити джерела ключових слів для створення семантичного ядра наведені на рис.3.
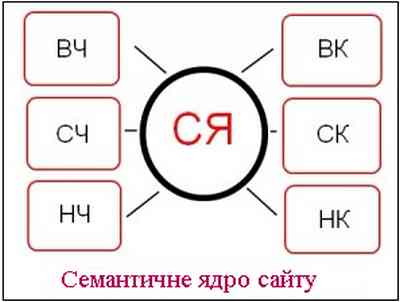
Рисунок 3 – Джерела ключових слів для семантичного ядра
Для початку можна обмежитися 100-200 запитами. Далі виробляється відсів невідповідних слів. Потрібно видалити ті слова, за якими точно не буде просуватися сайт. Як правило таких слів більше половини. Також проводиться відсів висококонкурентних запитів, за якими просування нереально. У підсумку відсіюється три слова з чотирьох, якщо не більше.
На третьому етапі проводиться розподіл списку запитів по сторінках сайту. Ключові слова з найбільшою частотою поміщають в метатега keywords, з меншою – розподіляють по контенту сайту. Більш конкурентні запити краще залишити на головній сторінці сайту, а менш конкурентні потрібно згрупувати за змістом і розподілити по інших сторінок ресурсу. Доцільно створити документ в Exel, розбити ключові слова по сторінках, підібрати асоціативні слова. Для блогу можна дотримуватися схеми: 5–12 середньо конкурентних слів – на головну; 1 СЧ + 2-3 НЧ + 2-3 допоміжних (асоціативних) – на внутрішню.
Загальноприйнятий алгоритм побудови семантичного ядра наведено на рис.4.

Рисунок 4 – Традиційний алгоритм створення семантичного ядра сайту
(анімація: 7 кадрів, 7 циклів повторення, 123 Кб)
6.Алгоритм формування семантичного ядра для сайтів з динамічним контентом
Для скорочення часу розробки та оновлення СЯС з динамічним контентом без втрати повноти і точності можна використовувати аналіз зв'язків (link analysis), що дозволяє згенерувати правила кількісного опису взаємного зв'язку між двома і більше ключовими словами, об'єднаними в одному семантичному запиті. Такі правила в термінах аналізу зв'язків називаються асоціативними, а запит являє собою деяке безліч подій, що відбуваються спільно, і утворює транзакцію.
Для пошуку закономірності між подіями, тобто запитами користувачів використовується база пошукових транзакцій (БПТ), БПТ являє собою таблицю, кожен запис якої містить номер транзакції і список ключових слів, що склали запит під час цієї транзакції.
Алгоритм автоматизації розробки та оновлення СЯ на основі застосування аналізу зв'язків до бази пошукових транзакцій можна представити у вигляді послідовності наступних кроків:
1. Оцінка контенту сайту і дослідження пошукових тенденцій для визначення первинного списку пошукових транзакцій;
2. За допомогою засобів статистики пошукових систем формування списку асоційованих запитів з вказаною частотою ключових слів;
3. Формування бази пошукових транзакцій (БПТ) заданого виду на підставі списку асоційованих запитів;
4. Пошук популярних наборів в БПТ і формування бази популярних пошукових транзакцій (БПТ);
5. На основі БПТ формування бази можливих імплікацій типу "умова > слідство", розрахунок їх підтримки та достовірності та формування бази асоціативних правил;
6. Формування МЕТА–тегів (Title, Description, Keywords) і модифікація контенту.
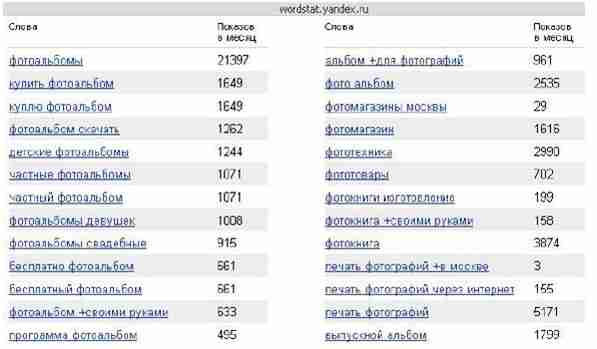
Рисунок 5 – Приклад списку асоційованих запитів з вказаною частотою ключових слів
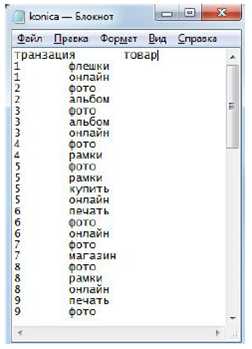
Рисунок 6 – Приклад бази пошукових транзакцій (БПТ)
7. Напрями подальших досліджень
Для реалізації 4 і 5 етапів алгоритму передбачається використовувати методи "Data Mining", реалізовані в аналітичному додатку Deductor Academic [19].
Висновки
Реалізація алгоритму розробки СЯ сайтів з динамічним контентом дозволить підняти позиції в ведучих пошукових систем для різних типів запитів за рахунок автоматизованого формування атрибуту content мета тегів keywords на основі АП, отриманих з транзакционной бази популярних пошукових транзакцій. Алгоритм розробки СЯ є досить універсальним і може бути застосований для ефективного просування сайтів з динамічним контентом фахівцями з SEO.
Список джерел
1 Паклин Н.Б. Бизнес-аналитика: от данных к знаниям/ Н.Б. Паклин, В.И. Орешков. – СПб.: Питер, 2009. – 624 с.
2. Chung D. Suchmaschinen-Optimierung: Der schnell Einstieg / D. Chung, A. Klunder. – Heidelberg: REDLINE/mitp, 2007. – 224 S.
3. Сирович Дж., Дари Кр. Поисковая оптимизация на PHP для профессионалов. Руководство разработчика по SEO. = Professional Search Engine Optimization with PHP: A Developer's Guide to SEO. M.: Диалектика, Вильяме, 2008. - 352 с.
4. Байков В. Д. Интернет. Поиск информации. Продвижение сайтов. — СПб.: БХВ-Петербург, 2000. 288 с.
5. Колисниченко Д. Н. Поисковые системы и продвижение сайтов в Интернете. М.: Диалектика, 2007. - 272 с.
6. Евдокимов Н. В. Раскрутка Web-сайтов. Эффективная Интернет-коммерция. М.: Вильяме, 2007. - 160 с.
7. Евдокимов Н., Лебединский И. Раскрутка веб-сайта. Практическое руководство. М.: Вильяме, 2011. - 288 с.
8. Евдокимов Н.В. Основы контентной оптимизации. Эффективная интернет-коммерция и продвижение сайтов в интернет. М: Вильяме, 2007. - 160 с.
9. Ашманов И.С., Иванов A.A. Оптимизация и продвижение сайтов в поисковых системах. СПб.: Питер, 2009. - 400 с.
10. Яковлев А. А. Раскрутка и продвижение сайтов: основы, секреты,трюки. СПб.: БХВ-Петербург, 2007. - 336 с.ч
11. Яковлев А., Ткачев В. Раскрутка сайтов. Основы, секреты, трюки. -СПб.: БХВ-Петербург, 2010. 352 с.
12. Agrawal R., Srikant R. Searching with numbers // In Proceedings of the eleventh international conference on World Wide. ACM Press, 2002.
13. Aizawa A. The feature quantity: an information theoretic perspective of tfldf-like measures // In Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval.
14. Тероу Ш. Видимость в Интернете. Поисковая оптимизация сайтов. = Search Engine Visibility. Б. м.: Символ-Плюс, 2009. - 288 с.
15. Арсирий Е.А., Игнатенко О.А., А.А. Леус Разработка семантического ядра сайта с динамическим контентом на основе ассоциативных правил // 2012, Том 2, №1
16. Павленко А. И. Ранжирование факторов продвижения интернет-магазина с помощью аппарата мультимножеств// реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2009.
17. Халыгов А. А. Методы повышения скорости ранжирования сайтов в поисковой системе Google// реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2013.
18. Как составить семантическое ядро сайта [Электронный-ресурс]. – Режим доступу: great-world.ru
19. Deductor Academic [Электронный-ресурс]. – Режим доступу: basegroup.ru
Важливе зауваження
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.