
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Классификация архитектур по параллельной обработки данных
- 5. Экстраполяционные алгоритмы
- Выводы
- Список источников
Введение
Современное состояние разработок и исследований в области математического моделирования отличается широким применением параллельных вычислительных систем. Стремительное развитие параллельного моделирования стимулируется необходимостью решения проблем моделирования сложных динамических объектов, описываемых системами обыкновенных дифференциальных уравнений (СОДУ), характеризующиеся высокими размерностями, жесткостью, плохой обусловленностью, учетом большого количества параметров [1].
Несмотря на то, что на современном состоянии развития технического прогресса существует много высокопроизводительных вычислительных систем, есть много задач, в которых остро ощущается проблема нехватки вычислительных ресурсов, при том, что современные высокопроизводительные кластеры преодолели рубеж в петафлопс, а количество ядер, насчитывающих такие системы, десятки и сотни тысяч. Эффективность параллельных приложений на подобных системах по разным оценкам не превышает 15%, а в некоторых случаях, даже 3–5% от пиковой производительности [2].
1. Актуальность темы
На протяжении многих лет численное решение задачи Коши было объектом пристального внимания ученых, поскольку оно широко применяется в различных областях науки и техники. Поэтому и количество разработанных методов очень велико. Одним из важнейших численных методов решения задач Коши является экстраполяционные методы Ричардсона, которые предназначены для получения высокоточного решения задачи Коши и интеграции систем обыкновенных дифференциальных уравнений со сложными правыми частями. Практическое применение экстраполяционных методов затруднено в связи с большой вычислительной сложностью их последовательных реализаций. Кроме того, использование технологии локальной экстраполяции на основе явных опорных схем ограничивает использование методов областью нежестких задач. Поэтому построение эффективных параллельных блочных неявных методов локальной экстраполяции Ричардсона – одна из самых актуальных тем в настоящее время.
2. Цель и задачи исследования, планируемые результаты
Целью исследования является повышение эффективности параллельных вычислений за счет совершенствования параллельного экстраполяционного алгоритма и анализ результатов, которые будут получены при проведении экспериментов на параллельной вычислительной системе.
Основные задачи исследования:
- Рассмотреть подходы к параллельной реализации методов решения многомерных задач Коши, которые основаны на использовании экстраполяции Ричардсона.
- Усовершенствовать параллельный экстраполяционный алгоритм.
- Проанализировать результаты, которые будут получены при проведении экспериментов на параллельной вычислительной системе.
Объект исследования: поддержка параллельных вычислений при моделировании сложных динамических объектов.
Предмет исследования: параллельные численные методы моделирования динамических объектов большой размерности с сосредоточенными параметрами, ориентированные на решение задачи Коши для обыкновенных дифференциальных уравнений, обеспечивающих повышение эффективности функционирования параллельных вычислительных систем.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Усовершенствование параллельного экстраполяционное алгоритма.
- Разработка тестовых задач для оценки эффективности модификации.
3. Обзор исследований и разработок
3.1 Обзор международных источников
Хайрер Е. и Ваннер Г., известные математики Швейцарии и Норвегии, в своих работах [3–4] предоставляют полную картину современного состояния теории и практики численного решения обыкновенных дифференциальных уравнений, основные теоретические результаты, представляют наиболее употребляемые численные методы, дают большое количество примеров практических применений в физике и прикладных науках. И что не менее важно, представляют тексты программ на Фортране.
В книге Дж.Холла [5] представлен полный набор лучших из существующих алгоритмов решения, а также обзор последних достижений теории как для начальных, так и краевых задач. Книга адресована широкому кругу специалистов, интересующихся численными методами.
Удачное сочетание учебного пособия и справочника по методам численной алгебры представляет собой книга [6] известных американских математиков–вычислителей, Голуба Дж. и Ван Лоун Ч. Изложение сжатое, в рецептурной формы, без доказательств. Книгу отличают методические преимущества: каждый раздел содержит задания для читателей–студентов, и обзор научной литературы – для специалистов. Для математиков–вычислителей, инженеров, студентов математических и технических специальностей.
3.2 Обзор национальных источников
Учебные пособия Гергеля В.П. [7] содержат материалы для работы в области параллельного программирования. Дается краткая характеристика принципов построения параллельных вычислительных систем, рассматриваются математические модели параллельных алгоритмов и программ для анализа эффективности параллельных вычислений, приводятся примеры конкретных параллельных методов для решения типовых задач вычислительной математики.
Воеводин В.В. и Воеводин Вл.В. свою книгу [8] посвящают обсуждению ключевых проблем современных параллельных вычислений. С единых позиций рассматриваются архитектуры параллельных вычислительных систем, технологии параллельного программирования, численные методы решения задач. Вместе со строгим описанием основных положений теории информационной структуры программ и алгоритмов, книга содержит богатый справочный материал, необходимый для организации эффективного решения больших задач на компьютерах с параллельной архитектурой.
3.3 Обзор локальных источников
На территории Украины сотрудники Донецкого национального технического университета активно занимаются проблемой повышения эффективности численного решения многомерных задач Коши.
В статье [9] профессор Дмитриева О.А. предлагает новые колокационные блочные методы решения жестких систем обыкновенных дифференциальных уравнений с управлением размером шага, которые ориентированы на параллельную архитектуру. Основная идея, на которой базируется конструирование предлагаемых методов, заключается в одновременном получении приближений точного решения во всех расчетных точках блока.
В статье [10] профессор Лев Петрович Фельдман и доцент Ирина Акоповна Назарова (ДонНТУ) рассмотрели параллельный алгоритм решения систем ОДУ, который ориентирован на системы с SIMD–архитектурой. Были получены характеристики алгоритма, такие как время выполнения, ускорения и эффективность параллельной реализации.
Статья [11] посвящена вопросам построения параллельных разностных схем решения задачи Коши с улучшенными показателями скорости сходимости, с целью выравнивания порядка аппроксимации во всех расчетных точках. Колокационные методы построены на интерполяционных многочленах Эрмита, степени которых совпадают с количеством точек коллокации.
В [12] доцентом Татьяной Васильевной Михайловой были предложены модифицированные методы анализа и синтеза высокопроизводительных вычислительных ресурсов различной топологии с помощью вероятностных моделей, позволяющих анализировать и проектировать широкий класс высокопроизводительных параллельных вычислительных сред.
4. Классификация архитектур по параллельной обработки данных
В 1966 году М.Флинном был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемых процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных, и описывает четыре архитектурных класса [14] (см. рис.1):
1) SISD – Single Instruction (1) Single Data (3);
2) MISD – Multiple Instruction(2) Single Data;
3) SIMD – Single Instruction Multiple Data (4);
4) MIMD – Multiple Instruction Multiple Data.

Рисунок 1 – Классификация архитектур вычислительных систем по М.Флинну (анимация: 12 кадров, 5 циклов повторения, 100 Кб)
SISD – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно выполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако, каждый из них выполняют несвязанные потоки инструкций, что делает такие системы комплексами SIMD–систем, которые действуют на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем, векторный поток данных следует рассматривать как поток из одиночных неделимых векторов. Примерами компьютеров с архитектурой SISD есть большинство рабочих станций Compaq, Hewlett–Packard и Sun Microsystems.
MISD – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, не было создано. Как аналог работы такой системы, видимо, можно рассматривать работу банка. Из любого терминала можно подать команду и что–то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, то мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, в пределах от 214 до 16384, которые могут выполнять одну и ту же инструкцию по разным данным в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD – систем является векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются с помощью векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз быстрее, чем при работе в скалярном режиме. Примерами систем подобного типа является, например, компьютеры Hitachi S3600.
MIMD – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от многопроцессорных SISD–машин, упомянутых выше, команды и данные связаны, потому что они представляют различные части одной и той же выполняемой задачи. Например, MIMD–системы могут параллельно выполнять множество подзадач, с целью сокращения времени выполнения основной задачи.
5. Экстраполяционные алгоритмы
Практическое применение экстраполяционных методов затруднено в связи с большой вычислительной сложностью их последовательных реализаций, поэтому построение эффективных параллельных блочных неявных методов локальной экстраполяции Ричардсона – один из наиболее реальных способов сокращения времени интегрирования многомерных жестких начальных задач.
Решение задачи Коши для систем обыкновенных дифференциальных уравнений первого порядка [13]
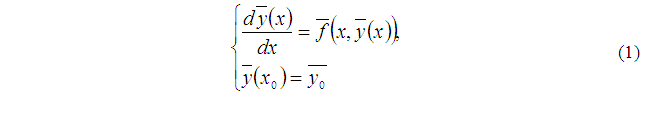
рассматривается при переходе из точки Xn в точку Xn+H, где H – базовая длина шага.
По рекуррентными соотношениями определяют значение для произвольных i, j по схеме локальной полиномиальной экстраполяции Эйткена–Невилла (см. рис. 2).
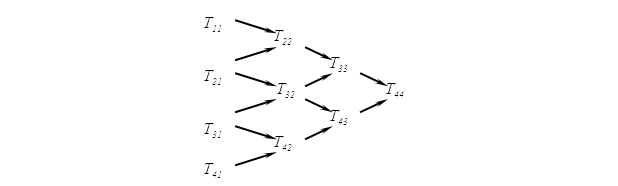
Рисунок 2 – Расчет по схеме Эйткена–Невіла
Существует несколько вариантов вычислений элементов экстраполяционной таблицы Эйткена–Невилла. Первый заключается в ограничении размерности СОДУ, то есть каждый процессор группы передает соответствующему процессору соседней группы все компоненты своего вектора аппроксимации решения. Второй вариант заключается в следующем: в каждой группе процессоров ровно один процессор отвечать за передачу данных между группами [13].
Из двух рассмотренных вариантов получения экстраполяционной таблицы, именно второй подходит для пропорционального разбиения процессоров, поскольку не требует дополнительного сортировки данных из–за неравномерности их распределения. В общем виде проблема разбиения процессорного поля на группы, обеспечивающие оптимальное решение задачи балансировки загрузки многопроцессорной системы, сформулирована в терминах комбинаторной оптимизации. Точное решения задач этого класса за приемлемое время невозможно, поскольку задача является NP–сложной, поэтому предлагаются близкие к оптимальному рациональные решения приближенными эвристическими методами.
Выводы
Магистерская работа посвящена актуальной научной задаче – поддержке параллельных вычислений при моделировании сложных динамических объектов. В рамках проведенных исследований выполнено:
- Рассмотрены подходы к параллельной реализации методов решения многомерных задач Коши, основанные на использовании экстраполяции Ричардсона.
- Усовершенствован параллельный экстраполяционный алгоритм.
Дальнейшие исследования направлены на следующие аспекты:
- Качественное совершенствование параллельного экстраполяционное алгоритма.
- Анализ результатов, которые будут получены при проведении экспериментов на параллельной вычислительной системе.
На момент написания данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Grand Challenges: Science, Engineering and Societal Advances Requiring Networking and Information Technology Research and Development [Электронный ресурс] // Report by Interagency Working Group on Information the Technology Research and Development. – Режим доступа: http://www.nitrd.gov/pubs/200311_grand_challenges.pdf
- The Networking and Information Technology Research and Development Program fy 2013. [Электронный ресурс] // Reports National Coordination Office for Networking and Information Technology Research and Development. – Режим доступа: http://www.nitrd.gov/pubs/2013supplement/FY13NITRDSupplement.pdf
- Хайрер Э. Решение обыкновенных дифференциальных уравнений. Жесткие задачи. // Э. Хайрер, Г. Ваннер. – М.: Мир, 1999. – 685с. – ISBN 5–03–003117.
- Хайрер Э., Нерсетт С., Ваннер. Г. Решение обыкновенных дифференциальных уравнений. Нежесткие задачи. // Э. Хайрер, С. Нерсетт, Г. Ваннер. – М.: Мир, 1990. – 512с. – ISBN 5–03–001179–X.
- Холл Дж. Современные численные методы решения обыкновенных дифференциальных уравнений // Дж.Холл. – М.: Мир, 1979. – 312 с.
- Голуб Д. Ван Лоун Ч. Матричные вычисления // Д.Голуб, Ван Лоун Ч. – М.: Мир, 1999. – 548 с.
- Гергель В.П. Теория и практика параллельных вычислений // В.П. Гергель – М.: Мир, 2007 – 424 c.
- Воеводин В.В., Воеводин Вл.В. Параллельные вычисления // В.В. Воеводин, Вл.В. Воеводин – БХВ–Петербург, 2004 – 160 с.
- Дмитриева О.А. Высокоэффективные алгоритмы управления шагом на основе параллельных коллокационных блочных методов/ О.А. Дмитриева // Искусственный интеллект, 2012. – № 4. – С. 77–88.
- Фельдман Л.П., Назарова И.А. Применение технологии локальной экстраполяции для высокоточного решения задачи Коши на SIMD–структурах / Л.П. Фельдман, И.А. Назарова // Научные труды Донецкого национального технического университета. Выпуск 70. Серия: «Информатика, кибернетика и вычислительная техника» (ИКВТ–2003) – Донецк: ДонНТУ, 2003.
- Дмитриева О.А. О приведении матриц расчетных коэффициентов коллокационных методов со старшими производными к диагональному виду/ О.А. Дмитриева // Наукові праці – Донецк: ДонНТУ, 2013.
- Михайлова Т.В. Оценка эффективности высокопроизводительных вычислительных систем с использованием аналитических методов/Т.В. Михайлова// Материалы 2–й международной научно–технической конференции "Моделирование и компьютерная графика", г. Донецк, 10–12 октября 2007 г.
- Фельдман Л.П., Назарова І.А. Паралельні однокрокові методи чисельного розв’язання задачі Коші/Л.П. Фельдман, І.А. Назарова. – Донецьк: «ДВНЗ» ДонНТУ, 2011. – 185 с.
- Emerson D.R. Introduction to Parallel Computers: Architecture and Algorithms / D.R. Emerson // High Performance Computing in Fluid Dynamics – London, 1996. – 42 p.