
Abstract on the theme of master's work
Content
- Introduction
- 1. Goal and tasks of the research
- 2. Taxonomy of Parallel Processor Architectures
- 3. Extrapolation algorithms
- Conclusion
- References
Introduction
The current state of research and development has a wide application of parallel computing systems in the field of mathematical modeling. The rapid development of parallel simulation stimulated the need to solve the problems of modeling complex dynamic objects, which are characterized by high dimensionality, stiffness, poor conditionality, given the large number of parameters[1].
At the present state of technical progress, there are many high-performance computing systems, but there are many problems in which the acute problem of shortage of computing resources. Efficiency Parallel applications on different systems, such estimates do not exceed 15%, and in some cases even 3–5% of the peak performance [2].
1. Goal and tasks of the research
The purpose of this study is to improve the efficiency of parallel computing by improving the parallel extrapolation algorithm and analyze the results to be obtained in experiments on parallel computing system.
Main tasks of the research:
- Consider approaches to parallel implementation of methods for solving multidimensional Cauchy problems, which are based on the use of the Richardson extrapolation.
- Improve parallel extrapolation algorithm.
- Analyze the results to be obtained in experiments on parallel computing system.
Research object: support parallel computing modeling complex dynamic objects.
Research subject: parallel numerical methods for simulation of dynamic objects of high dimensionality.
2. Taxonomy of Parallel Processor Architectures
The taxonomy of computer systems proposed by M.J. Flynn in 1966 has remained the focal point in the field. This is based on the notion of instruction and data streams that can be simultaneously manipulated by the machine [14].
1) SISD – Single Instruction (1) Single Data (3);
2) MISD – Multiple Instruction(2) Single Data;
3) SIMD – Single Instruction Multiple Data (4);
4) MIMD – Multiple Instruction Multiple Data.

Figure 1 – Taxonomy of Parallel Processor Architectures (animation: 12 shots, 5 cycles, 100 Kb)
SISD is a term referring to a computer architecture in which a Single processor, a uniprocessor, executes a single instruction stream, to operate on data stored in a single memory. SISD is one of the four main classifications. In this system classifications are based upon the number of concurrent instructions and data streams present in the computer architecture. SISD can have concurrent processing characteristics.
MISD is a type of parallel computing architecture where many functional units perform different operations on the same data. Pipeline architectures belong to this type, though a purist might say that the data is different after processing by each stage in the pipeline. Fault-tolerant computers executing the same instructions redundantly in order to detect and mask errors, in a manner known as task replication, may be considered to belong to this type. Not many instances of this architecture exist, as MIMD and SIMD are often more appropriate for common data parallel techniques.
SIMD is a class of Parallel computer. It describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously. Thus, such machines exploit data level parallelism. SIMD is particularly applicable to common tasks like adjusting the contrast in a digital image or adjusting the volume of digital audio.
MIMD is a technique employed to achieve parallelism. Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data. MIMD architectures may be used in a number of application areas such as computer-aided design/computer-aided manufacturing, simulation, modeling, and as communication switches. MIMD machines can be of either shared memory or distributed memory categories.
3. Extrapolation algorithms
Practical application of extrapolation methods is difficult due to the large computational complexity of their sequential implementations, therefore the construction of efficient parallel block implicit methods local Richardson extrapolation – one of the most feasible ways to reduce integration time multidimensional rigid primary tasks.
Cauchy problem for systems of ordinary differential equations of the first order [13]:
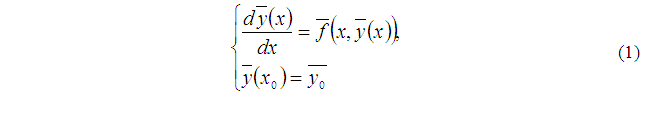
seen in the transition from the point Xn to point Xn+H, where H – the base pitch length.
By recurrence relations determine the value for arbitrary i, j according to the scheme of local polynomial extrapolation Aitken-Neville.
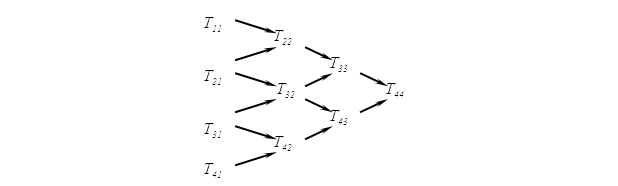
Figure 2 – Scheme of local polynomial extrapolation Aitken-Neville
Conclusion
Master's work is devoted to actual scientific problem – support parallel computing for modeling complex dynamic objects. In the trials carried out:
- Consider approaches to parallel implementation of methods for solving multidimensional Cauchy problems, which are based on the use of the Richardson extrapolation.
- Improve parallel extrapolation algorithm.
Further studies focused on the following aspects:
- Qualitative improvement of parallel extrapolation algorithm.
- Analysis of the results that will be obtained in experiments on parallel computing system.
This master's work is not completed yet. Final completion: December 2014. The full text of the work and materials on the topic can be obtained from the author or his head after this date.
References
- Grand Challenges: Science, Engineering and Societal Advances Requiring Networking and Information Technology Research and Development [Электронный ресурс] // Report by Interagency Working Group on Information the Technology Research and Development. – Режим доступа: http: // www.nitrd.gov/pubs/200311_grand_challenges.pdf
- The Networking and Information Technology Research and Development Program fy 2013. [Электронный ресурс] // Reports National Coordination Office for Networking and Information Technology Research and Development. – Режим доступа: http: // www.nitrd.gov/pubs/2013supplement/FY13NITRDSupplement.pdf
- Хайрер Э. Решение обыкновенных дифференциальных уравнений. Жесткие задачи. // Э. Хайрер, Г. Ваннер. – М.: Мир, 1999. – 685с. – ISBN 5–03–003117.
- Хайрер Э., Нерсетт С., Ваннер Г. Решение обыкновенных дифференциальных уравнений. Нежесткие задачи. // Э. Хайрер, С. Нерсетт, Г. Ваннер. – М.: Мир, 1990. – 512с. – ISBN 5–03–001179–X.
- Холл Дж. Современные численные методы решения обыкновенных дифференциальных уравнений // Дж.Холл. – М.: Мир, 1979. – 312 с.
- Голуб Д., Ван Лоун Ч. Матричные вычисления // Д.Голуб, Ван Лоун Ч. – М.: Мир, 1999. – 548 с.
- Гергель В.П. Теория и практика параллельных вычислений // В.П. Гергель – М.: Мир, 2007 – 424 c.
- Воеводин В.В., Воеводин Вл.В. Параллельные вычисления // В.В. Воеводин, Вл.В. Воеводин – БХВ–Петербург, 2004 – 160 с.
- Дмитриева О.А. Высокоэффективные алгоритмы управления шагом на основе параллельных коллокационных блочных методов / О.А. Дмитриева // Искусственный интеллект, 2012. – № 4. – С. 77–88.
- Фельдман Л.П., Назарова И.А. Применение технологии локальной экстраполяции для высокоточного решения задачи Коши на SIMD–структурах / Л.П. Фельдман, И.А. Назарова // Научные труды Донецкого национального технического университета. Выпуск 70. Серия: «Информатика, кибернетика и вычислительная техника» (ИКВТ–2003) – Донецк: ДонНТУ, 2003.
- Дмитриева О.А. О приведении матриц расчетных коэффициентов коллокационных методов со старшими производными к диагональному виду / О.А. Дмитриева // Наукові праці – Донецк: ДонНТУ, 2013.
- Михайлова Т.В. Оценка эффективности высокопроизводительных вычислительных систем с использованием аналитических методов /Т.В. Михайлова // Материалы 2–й международной научно–технической конференции "Моделирование и компьютерная графика", г. Донецк, 10–12 октября 2007 г.
- Фельдман Л.П., Назарова І.А. Паралельні однокрокові методи чисельного розв’язання задачі Коші /Л.П. Фельдман, І.А. Назарова. – Донецьк: «ДВНЗ» ДонНТУ, 2011. – 185 с.
- Emerson D.R. Introduction to Parallel Computers: Architecture and Algorithms / D.R. Emerson // High Performance Computing in Fluid Dynamics – London, 1996. – 42 p.