
Реферат по теме выпускной работы
Содержание
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Обзор исследований и разработок по теме
- 4. Общие понятия
- 4.1 Анализ существующих топологий многоядерных компьютеров
- 4.2 Средства распараллеливания
- 5. Методы анализа кластерных систем. Модель однородного кластера
- 5.1 Оценка эффективности
- 6. Планируемые результаты
- Список источников
Актуальность темы
С развитием информационных технологий количество задач, решаемых на вычислительных системах, непрерывно растет. При этом также значительно увеличиваются их сложность, а значит вместе с этим и их требования к вычислительным ресурсам. Персональные ЭВМ давно перестали удовлетворять эти потребности, поэтому для высокопроизводительных вычислений используются вычислительные кластеры. Стремительное развитие кластерных систем создает условия для использования многопроцессорной вычислительной техники не только в традиционной научной сфере (генетика, астрономия, метеорология и др.), но и в реальном секторе экономики, бизнесе. Поэтому анализ эффективности многопроцессорных систем и поиск путей повышения эффективности является одной из важнейших работ по развитию параллельных вычислительных технологий
2. Цель и задачи исследования
Цель работы состоит в разработке эффективного параллельного алгоритма построения аналитической модели кластерной системы.
Основные задачи исследования:
- Обзор и анализ современных вычислительных систем.
- Разработка марковской модели функционирования кластерной системы
- Расчет основных характеристик функционирования кластерной системы, с учетом особенностей ее структуры и класса решаемых на ней задач.
- Исследование эффективности вычислительной системы
3. Обзор исследований и разработок по теме
Работа по исследованию и разработке вычислительных систем не прекращается: активно разрабатываются алгоритмы улучшения работы вычислительных систем, решаются проблемы балансировки нагрузки в сети, планирования, выявления узких мест. В ДонНТУ над этими вопросами работают:
- Доктор технических наук, профессор, Фельдман Лев Петрович
- Кандидат технических наук, доцент Михайлова Татьяна Васильевна
В прошлом больших успехов в исследовании вычислительных систем достигли магистранты:
- Дяченко Татьяна Федоровна (Руководитель: к.физ-мат.н., доцент Дацун Наталья Николаевна)
- Тема магистерской работы:
Исследование параллельного алгоритма построения Марковских моделей вычислительных систем
- Кучереносова Ольга Владимировна (Руководитель: д.т.н., профессор Башков Евгений Александрович)
- Тема магистерской работы:
Исследование эффективности параллельных вычислительных систем
- Мищук Юлия Константиновна Руководитель: Фельдман Лев Петрович
- Тема магистерской работы:
Анализ эффективности вычислительных систем с использованием Марковской модели
- Юсков Андрей Германович Руководитель: Фельдман Лев Петрович
- Тема магистерской работы:
Эффективность функционирования кластерных систем
Данная работы является продолжением разработок этих магистрантов. Новизна работы состоит в том, что предыдущие модели вычислительных систем были рассчитаны на работу с одним классом задач. Необходимо продолжить исследования и построить дискретную Марковскую модель кластера, рассчитанного на работу с несколькими классами задач. Данная работа проводится совместно с магистром Ильей Владимировичем Бибиковым, Руководитель: Фельдман Лев Петрович. Тема работы: Оценка производительности распределенных систем Отличие моделей состоит в различном выборе ограничений, накладываемых на модель. Модель, рассмотренная в этой работе, будет иметь постоянное число заявок, обрабатываемых в системе.
4 Общие понятия
Вычислительная система:
В узком смысле под ВС понимают совокупность технических средств, в которую входит не менее двух процессоров, связанных общей системой управления и использования общесистемных ресурсов (память, периферийные устройства, программное обеспечение и т.п.). В более широком смысле – это взаимосвязанная совокупность аппаратных средств вычислительной техники и программного обеспечения, предназначенная для обработки информации [1].
Кластер – группа взаимно соединенных вычислительных систем (узлов), работающих совместно и составляющих единый вычислительный ресурс, создавая иллюзию наличия единственной ВМ. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. Примеры кластерных вычислительных систем: NT-кластер в NCSA, Beowulf-кластеры.
В качестве узла кластера может выступать как однопроцессорная ВМ, так и ВС типа SMP (Симметричная мультипроцессорная система логически представляется как единственная ВМ). Как правило, это не специализированные устройства, приспособленные под использование в вычислительной системе, как в МРР(Системы с массовым параллелизмом), а серийно выпускаемые вычислительные машины и системы. Еще одна особенность кластерной архитектуры состоит в том, что в единую систему объединяются узлы разного типа, от персональных компьютеров до мощных ВС. Кластерные системы с одинаковыми узлами называют гомогенными(однородными) кластерами, а с разнотипными узлами – гетерогенными(неоднородными) кластерами [2]. Типичный однородный кластер представлен на рисунке 1.

Рисунок 1 – Кластерная система
В состав кластера входят:
- Управляющий сервер (Server)
- Вычислительные узлы (Computer Nodes)
- LAN – Local Area Network, локальная сеть
- SAN – Storage Area Network, сеть хранения данных
4.1 Анализ существующих топологий многоядерных компьютеров
На сегодняшний день в мире существует множество классов и типов компьютеров, их все можно классифицировать по количеству потоков команд и по количеству потоков данных, которые обрабатывает одновременно система (классификация Флинна):
- ОКОД – Вычислительная система с одиночным потоком команд и одиночным потоком данных (SISD, Single Instruction stream over a Single Data stream).
- ОКМД – Вычислительная система с одиночным потоком команд и множественным потоком данных (SIMD, Single Instruction, Multiple Data).
- МКОД – Вычислительная система со множественным потоком команд и одиночным потоком данных (MISD, Multiple Instruction Single Data).
- МКМД – Вычислительная система со множественным потоком команд и множественным потоком данных (MIMD, Multiple Instruction Multiple Data).
Самыми распространенными и эффективными промышленными системами являются MIMD-компьютеры. В состав такого компьютера входит несколько процессоров, которые функционируют асинхронно и независимо друг от друга. В любой момент времени различные процессоры могут выполнять различные команды над разными частями одних и тех же данных.
MIMD-компьютеры относятся к компьютерам с разделенной памятью. А персональные компьютеры и малые сервера, привычные обычному пользователю, относятся к SIMD системам с общей памятью [3].
4.2 Средства распараллеливания
Существует несколько разных подходов к программированию параллельных вычислительных систем:
- На стандартных широко распространенных языках программирования с использованием коммуникационных библиотек и интерфейсов для организации межпроцессорного взаимодействия (PVM, MPI, HPVM, MPL, OpenMP, ShMem)
- использование специализированных языков параллельного программирования и параллельных расширений (параллельные реализации Fortran и C/C++, ADA, Modula-3)
- использование средств автоматического и полуавтоматического распараллеливания последовательных программ (BERT 77, FORGE, KAP, PIPS, VAST)
- программирование на стандартных языках с использованием параллельных процедур из специализированных библиотек, которые ориентированы на решение задач в конкретных областях, например: линейной алгебры, методов Монте-Карло, генетических алгоритмов, обработки изображений, молекулярной химии, и т.п. (ATLAS, DOUG, GALOPPS, NAMD, ScaLAPACK).
Существует также немало инструментальных средств, которые упрощают проектирование параллельных программ. Например:
- CODE – Графическая система для создания параллельных программ. Параллельная программа изображается в виде графа, вершины которого есть последовательные части программы. Для передачи сообщений используются PVM и MPI библиотеки.
- TRAPPER – Коммерческий продукт немецкой компании Genias. Графическая среда программирования, которая содержит компоненты построения параллельного программного обеспечения [4].
По опыту пользователей высокоскоростных кластерных систем, наиболее эффективно работают программы, специально написанные с учетом необходимости межпроцессорного взаимодействия. И даже несмотря на то, что программировать на пакетах, которые используют shared memory interface или средства автоматического распараллеливания, значительно удобней, больше всего распространены сегодня библиотеки MPI и PVM.
Коммуникационные библиотеки стандарта MPI (MPICH2, Open MPI, Cray MPI и др.) являются основным средством создания параллельных программ для распределенных вычислительных систем (ВС). Основу этих библиотек составляют коммуникационные функции дифференцированных (Point-to-point communications) и коллективных операций (Collective communications) обмена информацией между ветвями параллельных программ [5].
5. Методы анализа кластерных систем.Методы анализа кластерных систем. Модель однородного кластера
Для оценки качества и оптимизации параллельных вычислительных систем применяются аналитические и имитационные модели и методы экспериментального исследования.
Одним из методов оценки качества моделей ВС является теория массового обслуживания, позволяющая определить такие показатели качества, как пропускная способность, коэффициент использования, среднее время отклика и другие. Вычислительная система рассматривается как совокупность обслуживающих устройств, в качестве которых выступают различные ресурсы системы – рабочие станции, серверы, оперативная память, КЕШ-память и так далее. Задания, или процессы, предъявляют запросы на обслуживание к этим устройствам, поэтому значительная часть задач оценки качества связана с анализом очередей [6]. В теории массового обслуживания наиболее изученными и исследованными являются аналитические модели ВС, построенные на основе понятий теории цепей Маркова, использующие точные методы анализа.
С помощью дискретных моделей Маркова проанализировано небольшое количество однопроцессорных вычислительных структур, многопроцессорные же системы вызывают трудности ввиду трудоемкости их вычисления. В этом случае целесообразно распараллелить алгоритм построения дискретной модели и оценить эффективность распараллеливания.
Рассмотрим базовую дискретную модель однородного кластера с общим использованием дискового пространства(см. Рис. 2). Модель была построена с помощью методики [7]. В системе N одинаковых серверов, D дисковых накопителей и управляющий сервер УС.
В сети постоянное количество заявок M.
Требования, обсуживающиеся на сервере, поступают в ограниченную очередь типа FIFO (first in – first out
, Первый пришел – первый обслужился).

Рисунок 2 – Структурная схема Марковской модели однородного кластера
(анимация: 9 кадров, 10 циклов повторения, 1 сек задержка, размер – 493x323, 79.1 килобайт)
Введем такие характеристики обслуживания программ устройства:
- p10 – вероятность завершения обработки программы УС,
- p11 – вероятность запроса к одному из N серверов
- p21 – вероятность запроса к одному из D дисковых накопителей
- p10 – вероятность завершения обслуживания задачи на сервере
- p20 – вероятность завершения работы с дисковым накопителем, поступление на сервер (1..N)
5.1 Оценка эффективности
Алгоритм, примененный в параллельной реализации марковских моделей [8], состоит из двух частей: вычислений матрицы переходных вероятностей и вектора стационарных вероятностей.
Расчет стационарных вероятностей реализован с использованием итерационного алгоритма, в котором в качестве базового используется алгоритм умножения матрицы на вектор.
Для определения вектора стационарных вероятностей состояний 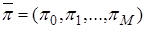 необходимо решить систему линейных алгебраических уравнений (СЛАУ),
необходимо решить систему линейных алгебраических уравнений (СЛАУ), 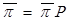 , соответствующую рассмотренной модели кластера.
, соответствующую рассмотренной модели кластера.
Расчет переходных вероятностей. За состояние системы примем размещение М заявок по N узлам 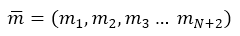 , где mi – количество задач в i-ом узле. Необходимо определить все возможные состояния. Обозначим множество состояний :
, где mi – количество задач в i-ом узле. Необходимо определить все возможные состояния. Обозначим множество состояний :

Число состояний системы для одного и того же количества задач  равно числу размещений j задач по N узлам и определяется по формуле
равно числу размещений j задач по N узлам и определяется по формуле 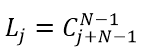 , общее количество состояний вычисляется так:
, общее количество состояний вычисляется так:
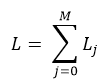
Вектор определяет количество устройств в каждом узле ВС. В зависимости от количества задач в системе размерность получаемых матриц может меняться. Порядок возникающих матриц – от нескольких тысяч до миллионов.
Вычисление элемента матрицы переходных вероятностей не зависит от соседних элементов, следовательно, в основе параллельной реализации этой части параллельного алгоритма можно использовать принцип распараллеливания по данным. Суть заключается в том, в задаче выделены отдельные независимые части – ветви программы, которые при наличии нескольких обрабатывающих устройств могут выполняться параллельно и независимо друг от друга [9].
Стационарные вероятности дают возможность определить средние значения временных характеристик обслуживания и занятости устройств вычислительной системы. Вычисление основных характеристик происходит по следующим формулам [10]:
- Среднее число свободных устройств в s-м узле вычисляется по формуле.

- Среднее число занятых устройств в s-м узле определяется по формуле.

- Загрузка устройств определяется по следующей формуле.

- Среднее число задач, находящихся в s-м узле.

- Среднее числo задач, находящихся в очереди к s-му узлу.

- Среднее время пребывания в s-м узле.

- Среднее время ожидания в s-м узле.

- Среднее время пребывания в вычислительной системе.

- Среднее время ожидания в вычислительной системе.

6 Планируемые практические результаты
По окончанию исследования планируется получить такие результаты:
- Дискретная Марковская модель однородного вычислительного кластера.
- Основные характеристики вычислительной системы.
- Новый параллельный алгоритм реализации дискретной Марковской модели однородного кластера.
- Основные характеристики распараллеливания.
Важное замечание При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014г. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Чекменев С. Е. Архитектура вычислительных систем. [Электронный ресурс]. – Режим доступа:http://stankin.ru/..
- Кластер // Словарь терминов в коллекции "Вычислительные системы" [Электронный ресурс]. – Режим доступа:http://www.nsc.ru/win/elbib/data/show_page.dhtml?77+858
- Чистяков А.В., Ислямова И.С. Метод и технологии параллельного программирования при решении прикладных задач / Инженерия программного обеспечения 2010 Том 3.
- Эффективные кластерные решения. [Электронный ресурс]. – Режим доступа:http://www.ixbt.com/cpu/clustering.shtml
- Курносов М.Г. MPIPerf: пакет оценки эффективности коммуникационных функций стандарта MPI // Труды международной научной конференции "Параллельные вычислительные технологии (ПаВТ-2012)". – Новосибирск, 2012. - С. 212-223.
- Клейнрок Л. Вычислительные системы с очередями. –М.: Мир, 1979.– 600с.
- Фельдман Л.П., Малинская Э.Б. Аналитическое моделирование вычислительных систем с приоритетным обслуживанием программ. //Электронное моделирование. – К., 1985. – №6.– с. 78-82.
- Михайлова Т.В. Параллельный алгоритм построения дискретной модели Маркова // Искусственный интеллект. Интеллектуаьные и многопроцесорные системы. Материалы Международной научно-технической конференции, 25-30 сентября 2006г., Таганрог-Донецк-Минск, 2006.
- Мищук Ю.К., Фельдман Л.П. Моделирование параллельной реализации марковских моделей в многопроцессорных вычислительных системах // Матеріали I всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених – 19-21 травня 2010р., Донецьк, ДонНТУ. – 2010. – с. 238-240Матеріали I всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених – 19-21 травня 2010р., Донецьк, ДонНТУ. – 2010. – с. 238-240 600с.
- Фельдман Л.П., Михайлова Т.В. Оценка эффективности кластерных систем с использованием моделей Маркова. //Известия ТРТУ. Тематический выпуск: Материалы Всероссийской научно-технической конференции с международным участием
Компьютерные технологии в инженерной и управленческой деятельности
. – Таганрог: ТРТУ, 2002. – №2 (25). – С. 50-53.