
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі системи
- 3. Огляд існуючих моделей і методів
- 4. Математична постановка задачі
- Висновки
- Перелік посилань
Вступ
Автоматизування процесу складання спортивного календаря спортсменів велосипедистів полягає у використанні системи підтримки та прийняття рішень щодо підбору найбільш відповідного складу спортсменів на гонку.
Система підтримки прийняття рішень, СППР, Decision Support System, DSS — комп'ютерна автоматизована система, метою якої є допомога людям, які приймають рішення в складних умовах для повного і об'єктивного аналізу предметної діяльності [4].
Система підтримки прийняття рішень призначена для підтримки багатокритеріальних рішень у складній інформаційному середовищі. При цьому під багатокритеріальністю розуміється той факт, що результати прийнятих рішень оцінюються не по одному, а по сукупності багатьох показників (критеріїв) розглянутих одночасно. Інформаційна складність визначається необхідністю обліку великого обсягу даних, обробка яких без допомоги сучасної обчислювальної техніки практично нездійсненна. У цих умовах число можливих рішень, як правило, дуже велике, і вибір найкращого з них "на око", без всебічного аналізу може призводити до грубих помилок.
Система підтримки рішень СППР вирішує два основні завдання:
- вибір найкращого рішення з безлічі можливих (оптимізація)
- впорядкування можливих рішень по перевагу (ранжування)
Для вирішення поставленої проблеми буде використовуватися перше завдання — вибір найкращого рішення з безлічі можливих.
1. Актуальність теми
На даний момент процес обліку фізичного стану професійного спортсмена є обов'язковим фактором для досягнення максимального результату. Це пов'язано з тим, що професійний велоспорт характеризується високою конкурентоспроможністю між спортсменами, що накладає високі вимоги на рівень фізичної підготовки.
Завдяки розвитку комп'ютерних технологій, всі дані, що характеризують тренування і фізичний стан спортсмена, знаходяться в електронному вигляді. Це в свою чергу дозволяє легко маніпулювати ними, зводити дані в таблиці і графіки, а також проводити розрахунки для складання рекомендація спортсмену.
Враховуючи вищезазначене, розробка даного програмного програми є актуальним, ефективним і раціональним рішенням для майбутніх споживачів системи.
2. Мета і задачі системи
Система що розроблюється має обліковий і аналітичний характер, з орієнтацією на професійних спортсменів велосипедистів і спортсменів аматорів, які мають необхідні пристрої для зчитування результатів їх тренувань, які послужать вхідними даними для розроблюваної системи.
Призначення системи – систематизувати інформацію о проведених тренуваннях спортсмена велосипедиста. Ця інформація може використовуватися як для складання спортивного календаря на рік, так і для розподілу ролей гонщиків в команді. Система повинна дати ці рекомендації, тим самим виконати роботу спортивного аналітика і допомогти спортивному директору прийняти рішення про склад команд на різні гонки в поточному сезоні.
Мета системи допомогти вибрати максимально ефективний склад спортсменів на певну гонку, щоб команда змогла показати кращий результат, що ймовірно призведе до нових вкладенням спонсорів.
Основні завдання системи:
- систематизувати статистичну інформацію про тренування спортсмена і планованих гонках.
- класифікувати спортсменів по заданих ролям в команді.
- визначити склад команди на плановані заходи.
3. Огляд існуючих моделей і методів
На даний момент, при вирішенні поставленого завдання, обмежуються складанням статистичних даних і подальшим ручним аналізом. Пропонується використовуватися систему прийняття рішень, засновану на алгоритмі нечіткої класифікації даних.
Нечіткі моделі в теорії розпізнавання стають в останні роки одним з традиційних напрямів. Зокрема, в деяких задачах розпізнавання використовуються нечіткі моделі і нечіткий висновок [1]. У роботах професора Ротштейна та його учнів [2], [3].
говориться про ідентифікацію нелінійних об'єктів нечіткими базами знань та використанні нечітких моделей в задачах розпізнавання. Цікавим є використання нечітких чисел на виході алгоритму (виключається етап дефаззіфікації).У цьому завданню класом буде служить спеціалізація гонщика, а об'єктами — самі гонщики. Для визначення до якого класу належить об'єкт вимірюється «відстань» між порівнюваними спортсменами — ступінь схожості. Існує безліч метрик, ось лише основні з них [7]:
- Евклідова відстань.
Найбільш поширена функція відстані. Являє собою геометричним відстанню в багатовимірному просторі: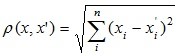
- Квадрат евклидової відстані.
Застосовується для додання більшої ваги більш віддаленим один від одного об'єктів. Це відстань обчислюється таким чином: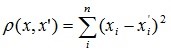
- Відстань міських кварталів (манхеттенська відстань).
Ця відстань є середнім різниць по координатах. У більшості випадків ця міра відстані призводить до таких же результатів, як і для звичайного відстані Евкліда. Однак для цього заходу вплив окремих великих різниць (викидів) зменшується (тому вони не зводяться в квадрат). Формула для розрахунку манхетенської відстані: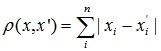
- Відстань Чебишева.
Ця відстань може виявитися корисним, коли потрібно визначити два об'єкти як «різні», якщо вони розрізняються за якоюсь однією координаті. Відстань Чебишева обчислюється за формулою: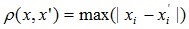
- Ступенева відстань.
Застосовується у випадку, коли необхідно збільшити або зменшити вагу, що відноситься до розмірності, для якої відповідні об'єкти сильно відрізняються. Ступенева відстань обчислюється за наступною формулою:де r і p – параметри, які визначаються користувачем. Параметр p відповідальний за поступове зважування різниць по окремих координатах, параметр r відповідальний за прогресивне зважування великих відстаней між об'єктами. Якщо обидва параметри – r і p – рівні двом, то ця відстань збігається з відстанню Евкліда.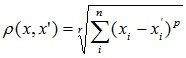
Вибір метрики повністю лежить на дослідника, оскільки результати кластеризації можуть істотно відрізнятися при використанні різних заходів.
4. Математична постановка задачі
Вхідні параметри завантажуються в систему з велокомпьютера, підключеного до ПК. До цих даних відносяться пульс, швидкість, каденс, потужність, температура повітря, висота [6]. Ці показники представляються у вигляді масивів поточних значень на кожен момент часу замірів датчиків. Також записується тривалість і тривалість поїздки.
Первинна обробка даних полягає в тому, що розраховуються середні, максимальні і мінімальні значення для кожного з вхідних параметрів за всю дистанцію і невеликими інтервалами, наприклад, по одному кілометру.
Після таких операцій є можливість відобразити статистичні графіки і таблиці.
Статистичні графіки і таблиці, містять середні, максимальні і мінімальні значення з кожного тренування по таким показників як пульс, швидкість, каденс, потужність, сила вітру, набір / втрата висоти. На графіку дані відображаються у вигляді кривих, побудованих по точках — по осі Х — дата тренування, по осі Y — значення параметра. Оскільки значення параметрів будуть сильно відрізнятися, наприклад, відображення на одній шкалі значення температури повітря і пульсу як мінімум буде виглядати неясно, по осі Y графік буде розділений на окремі області. Приклад наведено на рис. 1.
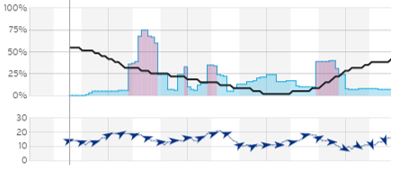
Рисунок 1 - Приклад відображення статистичного графіка
На підставі даних декількох тренувань можна судити про прогрес чи регрес спортсмена в плані фізичної форми. Точність результат буде залежати від кількості проведених тренувань. Необхідно стежити за змінами в значеннях параметрів пульсу, швидкості, каденса і потужності при приблизно однакових значеннях температури повітря і набору / втрати висоти. Якщо результати спортсмена протягом декількох тренувань погіршуються, то можна судити про недостатній відпочинок і необхідності зниження навантаження.
Також на підставі даних тренувань можна судити про найбільш придатною спеціалізації для спортсмена. Для цього визначимо можливі спеціалізації: спринтер — людина з кращим фінішем, це можна визначити по здатності розвинути потужність більше 700 Ватт, гірник — людина з кращого середньою швидкістю при наборі висоти понад 1000 м на 100 км шляху, роздільник — людина з кращим індивідуальним ходом, це визначається відносно стабільною потужністю і високою середньою швидкістю при наборі висоти менше 500 м на 100 км шляху. Для коректного визначення спеціалізацій необхідно щоб в системі були присутні декілька гонщиків, а в ідеалі — вся команда.
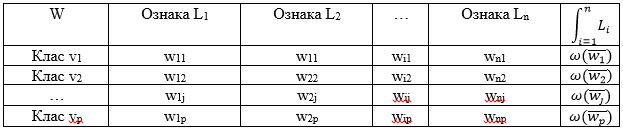
Сказати чітко до якої спеціалізації відноситься гонщик не можна, тому що ці поняття є елементами нечіткої логіки. Ступінь приналежності визначається за наступним алгоритмом формування функцій приналежності [5]. В основу побудови функції приналежності покладена частотна характеристика зустрічальності значень ознаки. Універсальним безліччю кожної лінгвістичної змінної є об'єднання носіїв нечітких множин термів — безліч всіх допустимих значень ознаки. На етапі побудови відсіваються різко виділяються значення - викиди. Значенням функції приналежності μij(х′i) ∈ [0,1] є ступінь впевненості, з якою зразок x′ зі значенням i-ої компоненти, рівним x′i, відповідає j-ому класу.
Таблиця 1 - Оцінка ступенів впевненості відповідності запропонованих даних
Функції будуються методом ковзного вікна. Розмір ковзного вікна підбирається експериментально. На рис. 2 наведено приклад терм-множини лінгвістичної змінної ознаки «Значення каденса» для ситуації, коли кількість класів n = 5.
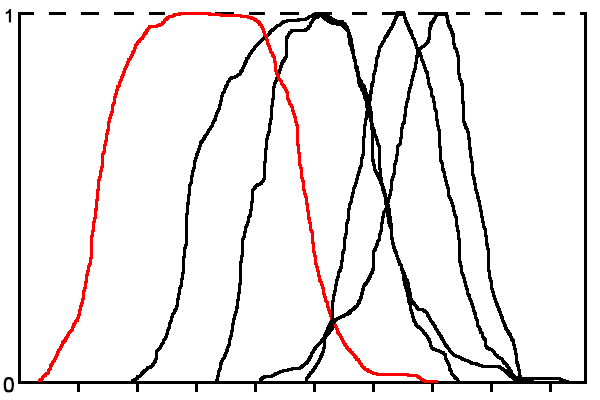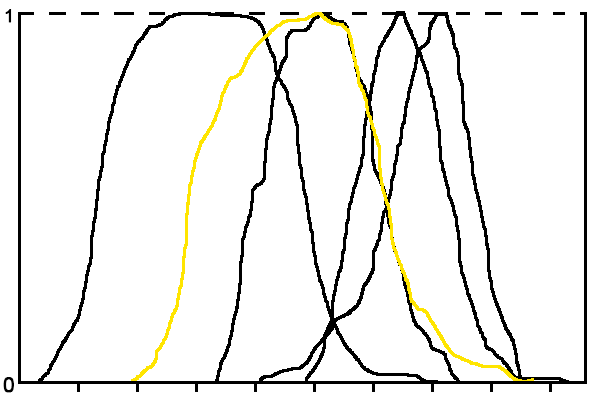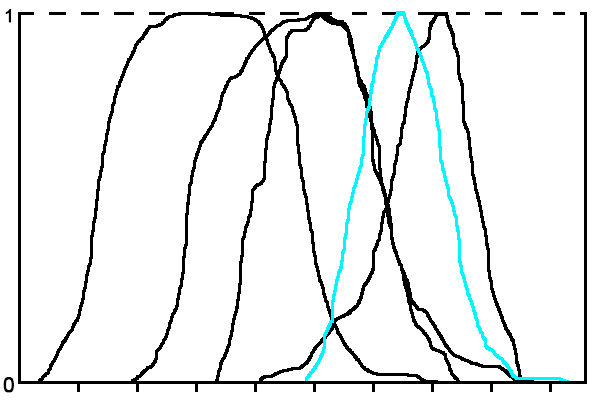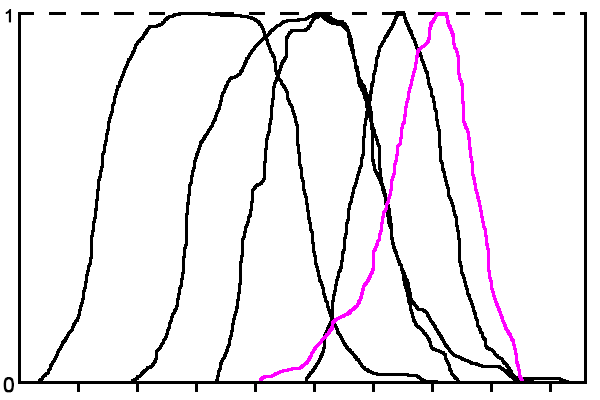
Рисунок 2 - Терм-множина лінгвістичної змінної «Значення каденса»
(анімація: 5 кадрів, зациклена, 21 кілобайт)З малюнка видно, що функції приналежності термів часто дуже близькі або перетинаються, що не дає можливості зробити висновок за даними тільки однієї ознаки, тому необхідна інтегральна оцінка за сукупністю ознак.
Щоб отримати значення ступеня впевненості відповідності запропонованого способу кожному з класів образів vi, будується табл. 1 оцінки ступеня впевненості.
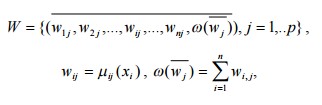
де μij(x) — функція належності j-ого терма i-ой лінгвістичної змінної, ω (w) — інтегральна впевненість, a xi — i-а компонента розпізнаваного способу x.
Ранжируємо таблицю за останнім стовпцем інтегральних впевнено і отримуємо клас vi, для якого ω(w) максимально. Він і визначається як найбільш відповідний запропонованим образу x. Експерт з табл. 1 визначає клас, якому найбільше відповідає вихідний спортсмен. У деяких ситуаціях виявляється, що з ненабагато меншим ступенем впевненості алгоритм відносить цей об'єкт і до інших класів. Така ситуація пояснюється наступним фактором — класи не завжди лінійно розділяються. Відсоток правильних відповідей залежить від повноти навчальної вибірки і кількості використовуваних для розпізнавання інформативних ознак.
Маючи дані про підходящої спеціалізації гонщика і календарний план гонок на майбутній сезон можна скласти гоночний індивідуальний календар спортсмена. Спортивним директором кожній гонці виставляється пріоритет від 0 до 10 і залежно від цього значення програма підбирає гонщиків на гонку, чим вище пріоритет, тим сильніший гонщик в необхідної категорії буде обраний. Сила гонщика визначається умовним коефіцієнтом, вираховуємо на підставі порівняння його середньої швидкості з іншими гонщиками з його спеціалізації. Кожна гонка вимагає гонщиків певних спеціалізацій, на відміну від турів, де є гонки усіх типів, а відповідно потрібні гонщики всіх класифікацій.
Для коректного підбору спортсменів на майбутню гонку необхідно мати достатньо інформації про саму гонці. Насамперед розрізняють одноденні і багатоденні гонки. Для багатоденної гонки важлива така особливість спортсмена, як відновлюваність. Це визначається за періодичністю та результативності тренувань, наприклад, якщо у гонщика є проміжок тренувань тривалістю не менше 5-ти днів з середнім пульсом більше 170 ударів / хв - можна судити про гарну відновлюваність спортсмена і має сенс рекомендувати його на багатоденні гонки. Також відмінною рисою багатоденних перегонів є різноманітність етапів, що говорить про необхідність спортсменів різних категорій у складі команди.
Кожна гонка, а в разі туру — етап, повинна бути описана в системі, і містити інформації про тривалість, наборі висоти і узвозі, максимальний градієнт, дату проведення і короткому описі.
Існує безліч сторонніх чинників, що не піддаються комп'ютерному аналізу, тому обрана класифікація спортсмена і запропонований календар гонок не завжди будуть оптимальними, що говорить про необхідність перевірки вихідних даних.
На підставі наведеної інформації можна сказати що вихідними параметрами будуть гоночний календар команди, а також статистичні таблиці та графіки з показниками тренувань.
Висновки
В результаті проведених досліджень була обґрунтована необхідність розробки комп'ютеризованої системи автоматизації процесу складання спортивного календаря спортсменів велосипедистів, визначено її основні функції, проаналізовано існуючі методи класифікації даних, наведено принцип алгоритму формування функції приналежності. Описана очікувана функціональна і математична постановка задачі.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: зима 2015—2016 рр. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- А.В Леоненков. Нечеткое моделирование в среде MATLAB и fuzzyTECH. — СПб.: БХВ-Петербург, 2003. — 736 с.
- А.П. Ротштейн, Д.И. Кательников Идентификация нелинейных объектов нечеткими базами знаний // Кибернетика и системный анализ. — 1998. — № 5 — 122 с.
- С.Д. Штовба Настройка нечеткой модели по обучающей выборке с нечетким выходом // Кибернетика и системный анализ. — 2007. — № 3 — с. 55–68.
- Системы поддержки принятия решений / Интернет-ресурс. — Режим доступа: http://bourabai.kz/tpoi/dss.htm
- В.А. Козловский, А.Ю. Максимова Алгоритм распознавания, основанный на нечетком подходе // «Искусственный интеллект» — 2008 — №4 — с. 594–599.
- Шеннон Совндаль, Анатомия велосипедиста — Попурри, 2011. — 129 с.
- Обзор алгоритмов кластеризации данных / Интернет-ресурс. — Режим доступа: http://habrahabr.ru/post/101338
- О.И. Ларичев. Теория и методы принятия решений. — М., Логос, 2000 — 98 c.
- М.Ф. Каспшицкая, А.А. Провотарь Решение нечеткой задачи классификации: алгоритм и результаты вычислительного эксперимента // Компьютерная математика. — 2013, — № 2 — с. 144–152.
- В.А. Ибрагимов Элементы нечеткой математики — БАКУ, 2009. — 165 с.
- Квадрат евклидової відстані.