
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи системы
- 3. Обзор существующих моделей и методов
- 4. Математическая постановка задачи
- Выводы
- Список источников
Введение
Автоматизирование процесса составления спортивного календаря спортсменов велосипедистов заключается в использовании системы поддержки и принятия решений относительно подбора наиболее подходящего состава спортсменов на гонку.
Система поддержки принятия решений, СППР, Decision Support System, DSS - компьютерная автоматизированная система, целью которой является помощь людям, принимающим решение в сложных условиях для полного и объективного анализа предметной деятельности [4].
Система поддержки принятия решений предназначена для поддержки многокритериальных решений в сложной информационной среде. При этом под многокритериальностью понимается тот факт, что результаты принимаемых решений оцениваются не по одному, а по совокупности многих показателей (критериев) рассматриваемых одновременно. Информационная сложность определяется необходимостью учета большого объема данных, обработка которых без помощи современной вычислительной техники практически невыполнима. В этих условиях число возможных решений, как правило, весьма велико, и выбор наилучшего из них "на глаз", без всестороннего анализа может приводить к грубым ошибкам.
Система поддержки решений СППР решает две основные задачи:
- выбор наилучшего решения из множества возможных (оптимизация)
- упорядочение возможных решений по предпочтительности (ранжирование)
Для решения поставленной проблемы будет использоваться первая задача - выбор наилучшего решения из множества возможных.
1. Актуальность темы
На данный момент процесс учета физического состояния профессионального спортсмена является обязательным фактором для достижения максимального результата. Это связано с тем, что профессиональный велоспорт характеризуется высокой конкурентоспособностью между спортсменами, что накладывает высокие требования на уровень физической подготовки.
Благодаря развитию компьютерных технологий, все данные, характеризующие тренировку и физическое состояние спортсмена, находятся в электронном виде. Это в свою очередь позволяет легко манипулировать ими, сводить данные в таблицы и графики, а также производить расчеты для составления рекомендация спортсмену.
Учитывая вышеуказанное, разработка данного программного приложения является актуальным, эффективным и рациональным решением для будущих потребителей системы.
2. Цель и задачи системы
Разрабатываемая система имеет учетный и аналитический характер, с ориентацией на профессиональных спортсменов велосипедистов и спортсменов любителей, имеющих необходимые устройства для считывания результатов их тренировок, которые послужат входными данными для разрабатываемой системы.
Назначение системы – систематизировать информацию о проведенных тренировках спортсмена велосипедиста. Эта информация может использоваться как для составления спортивного календаря на год, так и для распределения ролей гонщиков в команде. Система должна дать эти рекомендации, тем самым выполнить работу спортивного аналитика и помочь спортивному директору принять решение о составе команд на различные гонки в текущем сезоне.Цель системы помочь выбрать максимально эффективный состав спортсменов на определённую гонку, чтобы команда смогла показать лучший результат, что вероятно приведет к новым вложениям спонсоров.
Основные задачи системы:
- систематизировать статистическую информацию о тренировках спортсмена и планируемых гонках.
- классифицировать спортсменов по заданным ролям в команде.
- определить состав команды на планируемые мероприятия.
3. Обзор существующих моделей и методов
На данный момент, при решении поставленной задачи, ограничиваются составлением статистических данных и дальнейшим ручным анализом. Предлагается использоваться систему принятия решений, основанную на алгоритме нечеткой классификации данных.
Нечеткие модели в теории распознавания становятся в последние годы одним из традиционных направлений. В частности, в некоторых задачах распознавания используются нечеткие модели и нечеткий вывод [1]. В работах профессора Ротштейна и его учеников [2], [3] говорится об идентификации нелинейных объектов нечеткими базами знаний и использовании нечетких моделей в задачах распознавания. Интересным является использование нечетких чисел на выходе алгоритма (исключается этап дефаззификации).
В данной задаче классом будет служит специализация гонщика, а объектами — сами гонщики. Для определения к какому классу относится объект измеряется «расстояние» между сравниваемыми спортсменами — степень похожести. Существует множество метрик, вот лишь основные из них [7]:
- Евклидово расстояние.
Наиболее распространенная функция расстояния. Представляет собой геометрическим расстоянием в многомерном пространстве: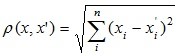
- Квадрат евклидова расстояния.
Применяется для придания большего веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом: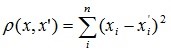
- Расстояние городских кварталов (манхэттенское расстояние).
Это расстояние является средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако для этой меры влияние отдельных больших разностей (выбросов) уменьшается (т.к. они не возводятся в квадрат). Формула для расчета манхэттенского расстояния: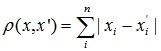
- Расстояние Чебышева.
Это расстояние может оказаться полезным, когда нужно определить два объекта как «различные», если они различаются по какой-либо одной координате. Расстояние Чебышева вычисляется по формуле: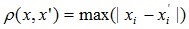
- Степенное расстояние.
Применяется в случае, когда необходимо увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Степенное расстояние вычисляется по следующей формуле:где r и p – параметры, определяемые пользователем. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра — r и p — равны двум, то это расстояние совпадает с расстоянием Евклида.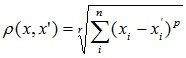
Выбор метрики полностью лежит на исследователе, поскольку результаты кластеризации могут существенно отличаться при использовании разных мер.
4. Математическая постановка задачи
Входные параметры загружаются в систему с велокомпьютера, подключенного к ПК. К этим данным относятся пульс, скорость, каденс, мощность, температура воздуха, высота [6]. Эти показатели представляются в виде массивов текущих значений на каждый момент времени замеров датчиков. Также записывается длительность и продолжительность поездки.
Первичная обработка данных заключается в том, что рассчитываются средние, максимальные и минимальные значения для каждого из входных параметров за всю дистанцию и небольшими интервалами, например, по одному километру.
После таких операций есть возможность отобразить статистические графики и таблицы.
Статистические графики и таблицы, содержат средние, максимальные и минимальные значения с каждой тренировки по таким показателей как пульс, скорость, каденс, мощность, сила ветра, набор/потеря высоты. На графике данные отображаются в виде кривых, построенных по точкам — по оси Х — дата тренировки, по оси Y — значение параметра. Поскольку значения параметров будут сильно отличаться, например, отображение на одной шкале значения температуры воздуха и пульса как минимум будет выглядеть неясно, по оси Y график будет разделен на отдельные области. Пример приведен на рис. 1.
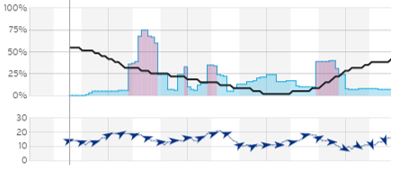
Рисунок 1 – Пример отображения статистического графика
На основании данных нескольких тренировок можно судить о прогрессе или регрессе спортсмена в плане физической формы. Точность результат будет зависеть от количества проведенных тренировок. Необходимо следить за изменениями в значениях параметров пульса, скорости, каденса и мощности при приблизительно одинаковых значениях температуры воздуха и набора/потери высоты. Если результаты спортсмена на протяжении нескольких тренировок ухудшаются, то можно судить о недостаточном отдыхе и необходимости снижения нагрузки.
Также на основании данных тренировок можно судить о наиболее подходящей специализации для спортсмена. Для этого определим возможные специализации: спринтер — человек с лучшим финишем, это можно определить по способности развить мощность более 700 Ватт, горняк — человек с лучшей средней скоростью при наборе высоты более 1000 м на 100 км пути, раздельщик — человек с лучшим индивидуальным ходом, это определяется относительно стабильной мощностью и высокой средней скоростью при наборе высоты менее 500 м на 100 км пути. Для корректного определения специализаций необходимо чтобы в системе присутствовали несколько гонщиков, а в идеале - вся команда.
Сказать четко к какой специализации относится гонщик нельзя, потому что эти понятия являются элементами нечеткой логики. Степень принадлежности определяется по следующему алгоритму формирования функций принадлежности [5]. В основу построения функции принадлежности положена частотная характеристика встречаемости значений признака. Универсальным множеством каждой лингвистической переменной является объединение носителей нечетких множеств термов — множество всех допустимых значений признака. На этапе построения отсеиваются резко выделяющиеся значения — выбросы. Значением функции принадлежности μij(х′i) ∈ [0,1] является степень уверенности, с которой образец x′ со значением i-ой компоненты, равным x′i, соответствует j-ому классу.
Таблица 1 – Оценка степеней уверенности соответствия предложенных данных

Функции строятся методом скользящего окна. Размер скользящего окна подбирается экспериментально. На рис. 2 приведен пример терм-множества лингвистической переменной признака «Значение каденса» для ситуации, когда количество классов n = 5.
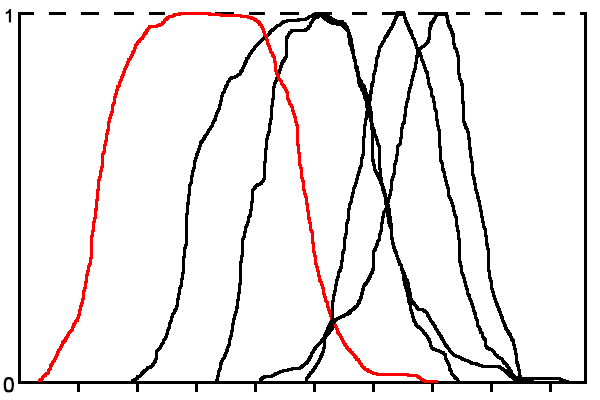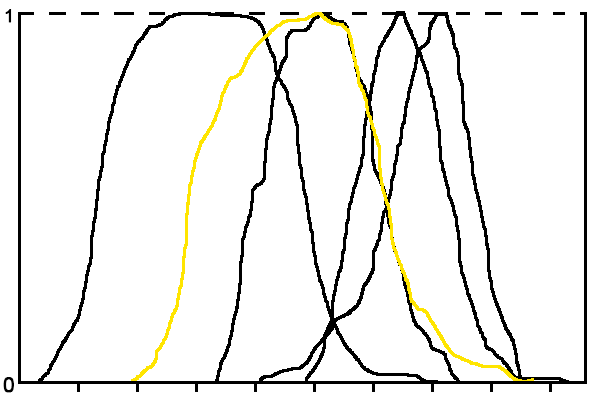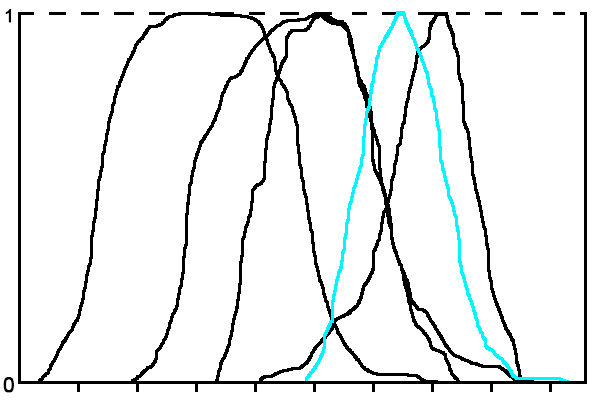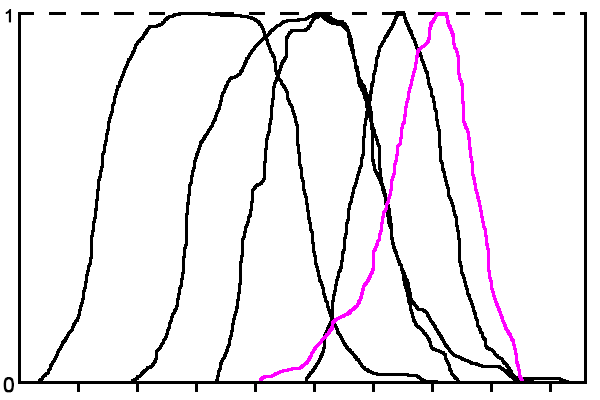
Рисунок 2 – Терм-множество лингвистической переменной «Значение каденса»
(анимация: 5 кадров, зацикленная, 21 килобайт)Из рисунка видно, что функции принадлежности термов часто очень близки или пересекаются, что не дает возможности сделать вывод по данным только одного признака, поэтому необходима интегральная оценка по совокупности признаков.
Чтобы получить значение степени уверенности соответствия предложенного образа каждому из классов образов vi, строится табл. 1 оценки степени уверенности.
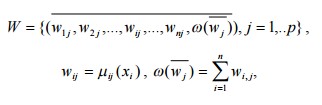
где μij(x) — функция принадлежности j-ого терма i-ой лингвистической переменной, ω(w) — интегральная уверенность, a xi — i-ая компонента распознаваемого образа x.
Ранжируем таблицу по последнему столбцу интегральных уверенностей и получаем класс vi, для которого ω(w) максимально. Он и определяется как наиболее соответствующий предложенному образу x. Эксперт по табл. 1 определяет класс, которому наиболее соответствует исходный спортсмен. В некоторых ситуациях оказывается, что с ненамного меньшей степенью уверенности алгоритм относит этот объект и к другим классам. Такая ситуация объясняется следующим фактором — классы не всегда линейно разделимы. Процент правильных ответов зависит от полноты обучающей выборки и количества используемых для распознавания информативных признаков.
Имея данные о подходящей специализации гонщика и календарный план гонок на предстоящий сезон можно составить гоночный индивидуальный календарь спортсмена. Спортивным директором каждой гонке выставляется приоритет от 0 до 10 и в зависимости от этого значения программа подбирает гонщиков на гонку, чем выше приоритет, тем более сильный гонщик в необходимой категории будет выбран. Сила гонщика определяется условным коэффициентом, высчитываем на основании сравнения его средней скорости с другими гонщиками из его специализации. Каждая гонка требует гонщиков определенных специализаций, в отличии от туров, где есть гонки всех типов, а соответственно нужны гонщики всех классификаций.
Для корректного подбора спортсменов на предстоящую гонку необходимо иметь достаточно информации о самой гонке. В первую очередь различают однодневные и многодневные гонки. Для многодневной гонки важна такая особенность спортсмена, как восстанавливаемость. Это определяется по периодичности и результативности тренировок, например, если у гонщика есть промежуток тренировок длительностью не менее 5-ти дней со средним пульсом более 170 ударов/мин — можно судить о хорошей восстанавливаемости спортсмена и имеет смысл рекомендовать его на многодневные гонки. Также отличительной чертой многодневных гонок является разнообразие этапов, что говорит о необходимости спортсменов различных категорий в составе команды.
Каждая гонка, а в случае тура — этап, должна быть описана в системе, и содержать информации о длительности, наборе высоты и спуске, максимальном градиенте, дате проведения и коротком описании.
Существует множество сторонних факторов, не поддающихся компьютерному анализу, поэтому выбранная классификация спортсмена и предложенный календарь гонок не всегда будут являться оптимальными, что говорит о необходимости проверки выходных данных.
На основании приведенной информации можно сказать что выходными параметрами будут гоночный календарь команды, а также статистические таблицы и графики с показателями тренировок.
Выводы
В результате проведенных исследований была обоснована необходимость разработки компьютеризированной системы автоматизации процесса составления спортивного календаря спортсменов велосипедистов, определены ее основные функции, проанализированы существующие методы классификации данных, приведен принцип алгоритма формирования функции принадлежности. Описана ожидаемая функциональная и математическая постановка задачи.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: зима 2015—2016 гг. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- А.В Леоненков. Нечеткое моделирование в среде MATLAB и fuzzyTECH. — СПб.: БХВ-Петербург, 2003. — 736 с.
- А.П. Ротштейн, Д.И. Кательников Идентификация нелинейных объектов нечеткими базами знаний // Кибернетика и системный анализ. — 1998. — № 5 — 122 с.
- С.Д. Штовба Настройка нечеткой модели по обучающей выборке с нечетким выходом // Кибернетика и системный анализ. — 2007. — № 3 — с. 55–68.
- Системы поддержки принятия решений / Интернет-ресурс. — Режим доступа: http://bourabai.kz/tpoi/dss.htm
- В.А. Козловский, А.Ю. Максимова Алгоритм распознавания, основанный на нечетком подходе // «Искусственный интеллект» — 2008 — №4 — с. 594–599.
- Шеннон Совндаль, Анатомия велосипедиста — Попурри, 2011. — 129 с.
- Обзор алгоритмов кластеризации данных / Интернет-ресурс. — Режим доступа: http://habrahabr.ru/post/101338
- О.И. Ларичев. Теория и методы принятия решений. — М., Логос, 2000 — 98 c.
- М.Ф. Каспшицкая, А.А. Провотарь Решение нечеткой задачи классификации: алгоритм и результаты вычислительного эксперимента // Компьютерная математика. — 2013, — № 2 — с. 144–152.
- В.А. Ибрагимов Элементы нечеткой математики — БАКУ, 2009. — 165 с.
- Квадрат евклидова расстояния.