
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі системи
- 3. Огляд існуючих моделей і методів
- 4. Математична постановка задачі
4.1 Алгоритм генетичного програмування
4.2 Застосування генетичного програмування для вирішення задачі
4.3 Генерація початкової популяції
4.4 Застосування генетичного програмування для отримання правил
- Висновки
- Перелік посилань
Вступ
Ефективність роботи практично в будь-якій галузі значною мірою визначається рівнем інформаційних технологій і широтою їх застосування. Цей фактор стає вирішальним у розвитку практично будь-якої області.
При розробці ЕС, як правило, використовуються продукційні моделі.
Продукційні моделі – це найбільш поширені на поточний день моделі подання знань, опис за допомогою правил «якщо щось» (явище > реакція) і надаються у вигляді: ЯКЩО умова (антецедент) ТО дію (консеквент). Система підтримки прийняття рішень призначена для багатокритеріальних рішень у складному інформаційному середовищі. При цьому під многокритериальностью розуміється той факт, де результати прийнятих рішень оцінюються не по одному, а за сукупністю багатьох показників (критеріїв) розглянутих одночасно. Інформаційна складність визначається необхідністю врахування великого обсягу даних, обробка яких без допомоги сучасної обчислювальної техніки практично нездійсненна. У цих умовах число можливих рішень, як правило дуже велике, і вибір найкращого з них "на око" без всебічного аналізу може призводити до грубих помилок.
Під умовою розуміється деяка пропозиція–зразок, за якою здійснюється пошук в базі знань, а під дією – набір дій, які виконуються при успішному результаті пошуку. Всередині консеквента можуть також генеруватися і додаватися до бази нові факти, які були отримані в результаті обчислень або взаємодії з користувачем.
При використанні таких моделей у системах, заснованих на знаннях, можливо:
- застосування простого і точного механізму використання знань;
- уявлення знань з високою однорідністю, описуваних за єдиним синтаксисом.
Ці дві відмінні риси і визначили широке поширення методів представлення знань правилами. Але отримання таких правил є однією з найбільш трудомістких завдань.
1. Актуальність теми
На даний момент, процес отримання продукційних правил є обов'язковим фактором для ЕС в області подання знань. Це пов'язано з тим, що методи машинного навчання на основі використання навчальних даних мають переваги в порівнянні з іншими математичними методами.
Завдяки розвитку комп'ютерних технологій всі дані і методи штучного інтелекту на базі машинного навчання, методи інтелектуального аналізу дозволять швидко і ефективно отримувати продукційні правила для вилучення знань, і отримувати нові і більш оновлені знання використовуючи навчальні приклади.
З огляду на вищевказане, розробка даного програмного додатка є актуальним, ефективним і раціональним рішенням для майбутніх споживачів системи.
2. Мета і задачі системи
Метою даної роботи є розробка математичного апарату для отримання продукційних правил для ЕС.
Для цього необхідно вирішити завдання:
- Розробити структуру ЕС;
- Розробити продукційні правила.
Для вирішення перерахованих завдань обрано такі напрямки досліджень:
- Методи інтелектуального аналізу даних з метою отримання продукційних правил;
- Принципи побудови експертних систем.
3. Огляд існуючих моделей і методів
В даний час існує досить багато методів вилучення закономірностей. Найбільш широко для обробки результатів використовуються методи математичної статистики і регресійного аналізу. Але такі методи можуть бути недоступні непідготовленому користувачеві, так як вимагають спеціальної математичної підготовки. Цим обумовлена необхідність представлення результатів обробки інформації в формі, доступній для фахівців будь–якій галузі. Розглянемо деякі методи здобування знань, багато з яких здатні надати результат в зрозумілому для людини вигляді.
В останні роки успішно впроваджуються програми, реалізовані на основі машинного навчання (МН). Область МН розглядає питання розробки комп'ютерних програм, які здатні автоматично отримувати нові або оновлювати накоплені знання, використовуючи навчальні приклади. Загальний підхід МН полягає в розробці та використанні програм, здатних навчатися під керівництвом вчителя. Так, учитель запропоновує програмі приклади реалізації деякого концепту, а завдання програми полягає в тому, щоб витягти з цих прикладів набір атрибутів і значень, які визначають цей концепт.
Все йде до того, що МН буде грати центральну роль в інформатиці та комп'ютерних технологіях. МН використовує поняття і походить від багатьох галузей, таких дисциплін, як теорія ймовірності і статистика, ШІ, філософія, теорія інформації, нейробиология, обчислювальна теорія складності, елементи теорії управління та інші.
Застосування МН до вилучення знань може використовуватися для:
- вилучення правил початкових навчальних вхідних даних;
- аналізу важливості окремих правил;
- оптимізації продуктивності набору правил.
Методи ШІ використовують машинне навчання як підхід до проблеми пошуку рішення, на основі застосування накопичених знань, які містяться в навчальних даних. Розглянемо деякі з них.
Вилучення знань за допомогою НС. Як правило, НС використовуються як інструмент передбачення, а не розуміння. Класичний нейросетевий підхід – метод чорного ящика – припускає створення імітаційної моделі, без явного формулювання правил прийняття рішень.
Метод нейросетевого передбачення реалізується НС, здатної здійснювати маніпуляції в просторі ознак великої розмірності. Рішення завдання за допомогою НС можна описати наступним алгоритмом:
- Формалізація навчальної вибірки. Відбір пацієнтів та інформації, яка буде включена в навчальну вибірку. Вибір важливих факторів, що характеризують (впливають на) певне захворювання. При необхідності – кодування і нормування навчальних даних.
- Формування архітектури НС. Вибирається тип НС, функції активації і алгоритм навчання.
- Початкова активація нейронів. Завдання початкових вагових коефіцієнтів.
- Ітераційне навчання НС обраним алгоритмом.
- Отримання і інтерпретація результату.
Еволюційні обчислення включають чотири відносно незалежні напрямки: генетичні алгоритми (ГА), еволюційне програмування, ДП і еволюційні стратегії. Всі чотири парадігми почали досліджуватися в 60–х і 70–х роках, але тільки в кінці 80–х років вони почали широко застосовуватися на практиці і отримали визнання.
В даний час ГА розглядаються як один з найбільш успішних методів МН. По суті, вони є процедурами оптимізації, що імітують при проектуванні моделі такі процеси, як генетична рекомбінація, мутація і відбір, аналогічні тим, що обумовлюють природну еволюцію. Перші генетичні алгоритми були запропоновані на початку 70–х років Джоном Холландом (John Holland) з метою імітації еволюційних процесів у живій природі.
Реалізувати більш потужні можливості можна за допомогою ДП. ДП є однією з парадігм еволюційних обчислень, які теж засновані на формалізації принципів природної еволюції. В даний час ДП успішно застосовується при вирішенні різних завдань. Як особини (потенційного рішення) в ДП використовується комп'ютерна програма, яка вирішує певне завдання. На відміну від інших еволюційних методів у ДП особини мають змінювати розмір та форму. Особина будується на основі безлічі проблемно–орієнтованих елементарних функцій (функціональної множини) і констант (термінальної множини), вибір яких істотно впливає на розмірність простору пошуку та якість одержуваного рішення. В процесі еволюції виробляється автоматична розробка, у певному сенсі, кращої програми.
Рішення завдання на основі ДП можна представити наступною послідовністю дій:
- Створення вихідної популяції.
- Оцінка особин за фітнес–функцією.
- Вибір батьків (працює оператор відбору – репродукції).
- Створення нащадків з відібраних пар батьків (працює оператор схрещування – кросинговер).
- Мутація нових особин (працює оператор мутації).
- Розширення популяції новими породженими особинами.
- Скорочення розширеної популяції до вихідного розміру (працює оператор редукції).
- Якщо критерій зупинки алгоритму виконано, то вибір кращої особини в кінцевій популяції є результатом роботи алгоритму. Інакше перехід на крок 2.
Таким чином, для вирішення завдання на основі ДП необхідно визначити безліч елементарних функцій і констант, форму представлення потенційного рішення – особини, операції схрещування і мутації, задати фітнес–функцію. Очевидно, що ефективність виконання завдання залежить від цілого ряду параметрів: розміру популяції, стратегії вибору особин, операторів схрещування і мутації, стратегії скорочення популяції, а також виду фітнес–функції. Застосовуються різні варіанти даних параметрів залежно від конкретного завдання.
4. Математична постановка задачі
Нехай для вектора вхідних змінних див. рис.1, для кожної i–ої змінної визначено певний вектор допустимих значень див. рис.2, де s – кількість допустимих значень, різний для кожного входу Xi.
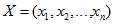
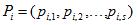
Тоді, наприклад, при вирішенні задачі класифікації на два класи з бінарними вхідними аргументами, правило може бути представлене таким чином:
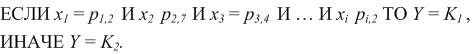
Часто є кілька таких правил, наприклад:
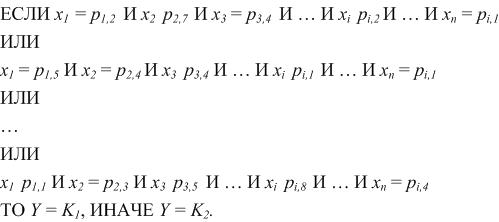
У такому випаду систему правил можливо описати таким чином:
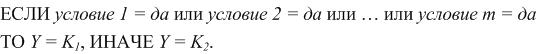
Де i–ій умові може відповідати, наприклад, така умова:
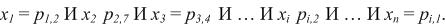
Перераховані правила можна формально описати наступним чином:
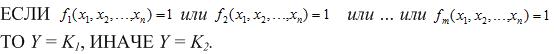
При такій інтерпретації для побудови правил необхідно знайти булеві функції виду (3)
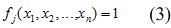
І тоді вся система правил буде представлена так:
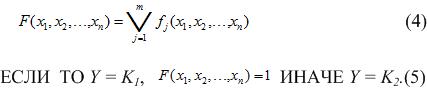
Тоді функція визначена в (4), а:
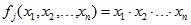
при цьому присутність кожного фактора не обов'язково, і кожен присутній фактор може бути в прямому або інверсному стані (операція НЕ). Базис логічних функцій теж можна змінювати. Розробка правил зводиться до знаходження певної функції або системи функцій F і полягає в побудові булевих функцій (3).
Критерієм оцінки якості знайденого рішення може бути оцінка точності. Нехай критерієм оцінювання є помилка Е (F), тоді завдання пошуку рішення зводиться до знаходження функцій F, так щоб виконувалася умова:
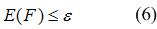
де e – допустима похибка класифікації.
У якості похибки класифікації може використовуватися:
– частка правильної класифікації (7);
– середньоквадратична похибка (8);
– середня абсолютна похибка (9);
– критерій суми квадратів похибки (10).
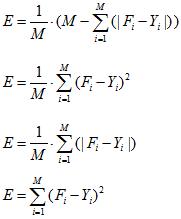
де М – кількість навчальних прикладів, А – отриманий результат, І – бажаний результат.
4.1 Алгоритм генетичного програмування
Для вирішення завдання за допомогою генетичного програмування необхідно виконати наступні попередні етапи:
-
визначити термінальну множину;
-
визначити функціональну множину;
-
визначити фітнес–функцію;
-
визначити значення параметрів ДП: потужність популяції, максимальний розмір особини, імовірності кросинговеру і мутації, спосіб відбіру батьків, критерій закінчення еволюції та інші.
Після цього розробляється еволюційний алгоритм, який реалізує ДП для вирішення конкретного завдання. Можуть бути різні підходи. Будемо використовувати для вирішення нашої задачі класичний підхід ДП, узагальнений алгоритм роботи який представлений на рис.3. Наведений алгоритм належить до класу синхронних еволюційних алгоритмів, де потужність популяції на кожній ітерації завжди підтримується постійної і перехід до наступної ітерації (поколінню) «синхронізований». Спочатку обробляються всі нащадки попереднього покоління, а потім відбувається перехід на наступну ітерацію.
4.2 Застосування генетичного програмування для вирішення задачі
Апарат ДП дозволяє побудувати за допомогою еволюційного алгоритму на основі навчальної вибірки програму, яка буде будувати продукційні правила, для класифікації на два класи. Відповідно постановки завдання необхідно побудувати булеву функцію виду (11):
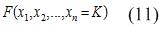
Значення K, що дорівнює одиниці, означає приналежність до одного класу, а нулю – відповідно до іншого.

(анімація: 10 кадрів, 10 циклів повторення, розмір 572x706, 145 КБ, 1 к/с)
Дані повинні бути попередньо оброблені, основне призначення попередньої обробки – перетворити вхідну навчальну множину в булевозначний вектор. Далі відповідно до наведеного вище, алгоритмом визначаються термінальні й функціональні множини, фітнес–функція, значення параметрів еволюційного алгоритму. Рішенням завдання буде булева функція (11), представлена у вигляді дерева.
Термінальна множина в даному випадку складається з вхідних змінних, які після попередньої обробки є булевозначний вектор.
Функціональне множина. Основними логічними операціями є: АБО, І, НЕ. Всі ці операції завжди мають один вихід, але можуть мати різну кількість входів. Так як перші дві функції можуть мати два і більше входа, а остання тільки один, то для більш зручної програмної реалізації виконаємо заміну операції НЕ на наступні дві: АБО–НЕ і І–НЕ. Така заміна дозволить уніфікувати кількість входів для всіх операцій (їх буде завжди 2). Таким чином, функціональну множину складають 4 логічні функції АБО, І, АБО–НЕ і І–НЕ. Такий логічний базис дозволяє позбутися і від так званих інтронів (непотрібних ділянок коду), в даному випадку від подвійного заперечення (НЕ (НЕ (X))).
Як фітнес–функції використовується частка з правильно певним класом (7).
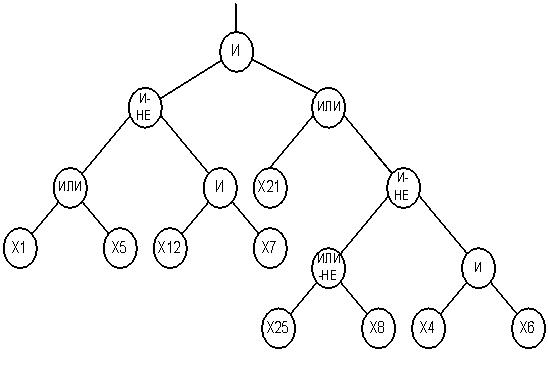
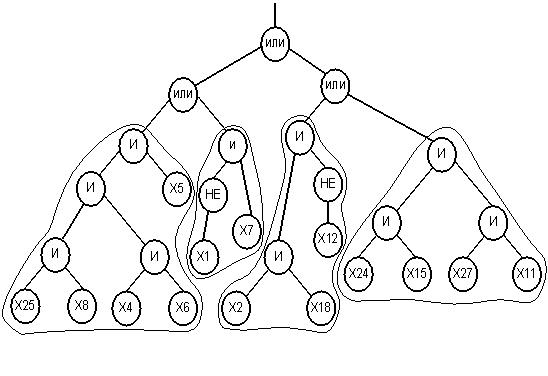
Отже, в контексті нашої задачі ДП використовується для отримання класифікаційного дерева (приклад структури показаний рис.4. Дереву на рис. 4 відповідає булева функція (12):
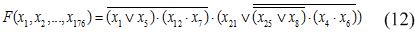
Узагальнений алгоритм отримання таких дерев і правил за допомогою генетичного програмування представлений рис.3.
Для отримання класифікаційного дерева необхідно виконати наступні етапи:
1. Встановити параметри ГП.
2. Згенерувати початкову популяцію. Популяція складається з певної кількості хромосом (особин). Кожна особина відповідає певному дереву, яке представляє собою рішення, наприклад, як на рис.4. Особина (дерево) на початковому етапі генерується випадковим чином і складається з функціональних і термінальних вузлів.
3. За значенням фітнес–функції (7) оцінити всі особини, що входять до популяції.
4. Виконати генетичні оператори.
5. Перевірити умову зупинки. Якщо критерій зупинки виконаний, то перейти на крок 6, інакше на крок 3.
6. Вибрати кращу особину (з максимальним значенням фітнес–функції), яка буде результатом роботи ДП, а відповідне їй дерево – рішенням поставленого завдання (класифікаційним деревом, яке виконує класифікацію на два класи).
4.3 Генерація початкової популяції
На даному етапі відбувається генерація початкової популяції відповідно до заданих параметрів. Популяція складається з набору дерев, згенерованих випадковим чином.
Генерація кожного дерева відбувається рекурсивно, починаючи з генерації функціонального вузла і його аргументів. Для кожного дочірнього вузла (аргументу) випадковим чином визначається, буде даний вузол функціональним або термінальним, далі відповідно до типу вузла вибирається його значення з відповідної термінальної або функціональної множини. Процес виконується за лівою гілкою до тих пір, поки не буде обраний дочірнім термінальний вузол. Потім генеруються праві гілки.
Чим передбачені наступні методи створення дерев:
1. Повний. При генерації випадкового дерева, кожна гілка має однакову (максимальну) глибину.
2. Зростаючий. При генерації випадкового дерева, кожна гілка може мати різну глибину, але не більше від встановленої максимальної.
3. Комбінований. Половина дерев всієї популяції генерується повним методом, друга половина – зростаючим.
1.Відбір батьків. Найважливішим фактором, який впливає на ефективність ДП, є оператор відбору. Сліпе слідування принципу «виживає найсильніший» може привести до звуження простору області пошуку рішення і попаданню знайденого рішення у галузь локального екстремуму фітнес–функції. З іншого боку, досить слабкий оператор відбору може привести до повільного зростання якості популяції, що призведе до уповільнення пошуку рішення. Крім того, популяція при такому підходу може не тільки не поліпшитися, але і погіршитися.
Найбільш поширені варіанти відбору батьків:
– випадковий рівноймовірний;
– рангово–пропорційний;
– відбір пропорційно значенням фітнес–функції;
– елітний відбір;
– відбір з витісненням.
З них використано відбір пропорційно значенням фітнес–функції, реалізований методом рулетки й турніру.
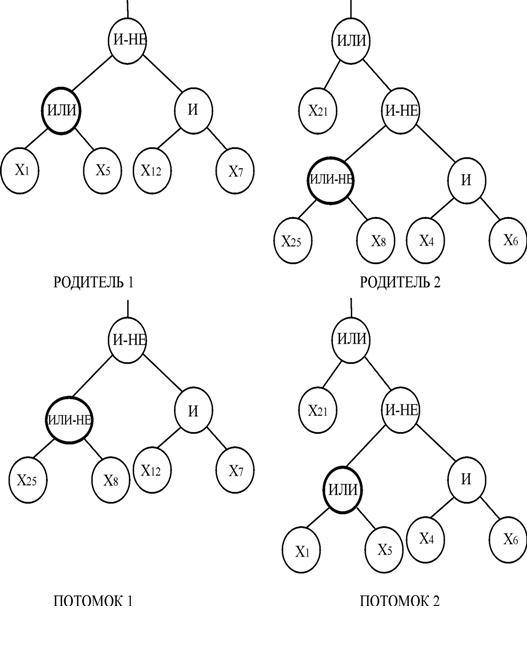
2.Кроссинговер. Для древоутвореної форми подання використовуються наступні три основних типи оператора кросинговеру (ОК):
– вузловий кроссинговер;
– кроссинговер піддерев;
– змішаний;
Вузловий оператор кросинговеру виконується наступним чином:
– вибираються два дерева і вузли в цих деревах. Так як вузли в деревах можуть бути різного типу, спочатку необхідно переконатися, що вибрані вузли у батьків є взаємозамінними. Якщо тип вузла у другому батькові відмінний від типу вузла першого батька, то в іншому батькові випадковим чином вибирається інший вузол, після чого знову виконується перевірка на предмет сумісності;
– проводиться обмін обраних вузлів.
Приклад вузлового ОК показаний на рис.5.
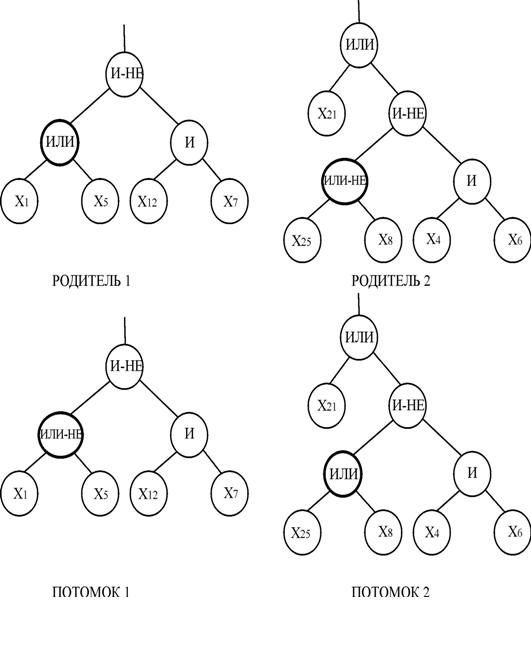
В кроссинговері піддерев батьки обмінюються не самими вузлами, а відповідними їм піддеревами. Такий ОК виконується наступним чином:
– вибираються батьки і вузли в них. Далі необхідно переконатися, що вибрані вузли належать одному типу (функціональному або термінальному). Якщо ця умова не виконується, то, як і в попередньому випадку, в іншому дереві вибирається інший вузол з подальшою перевіркою на взаємозамінність;
– проводиться обмін піддерев, які відповідають цим обраним вузлам. Обчислюється глибина дерева для кожного нащадка. Якщо очікуваний розмір не перевищує заданий поріг, то нащадки запам'ятовуються.
Обмін піддеревами можливий і в одному батькові. Приклад ОК піддерев показаний на рис.6.
При змішаному операторі кросинговеру для одних особин виконується вузловий оператор кросинговеру, а для інших – кроссинговер піддерев.
3.Мутація. Для дерев застосовні наступні оператори мутації (ОМ):
– вузлова мутація;
– посічена мутація;
– зростаюча мутація.
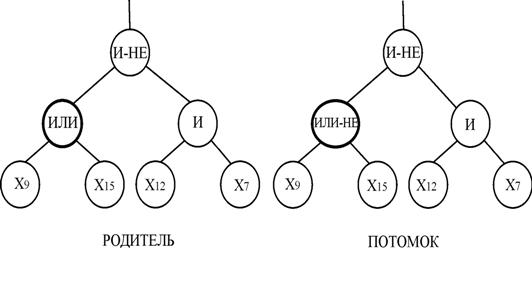
Вузловий оператор мутації виконується наступним чином:
– обирається випадковим чином вузол, що підлягає мутації;
– визначається тип обраного вузла (функціональний або термінальний);
– випадково вибирається з множини, відповідно до типу обраного вузла, значення вузла, відмінне від розглянутого;
– замінюється початкове значення вузла на вибране.
Приклад вузлового оператора мутації показаний на рис.7.
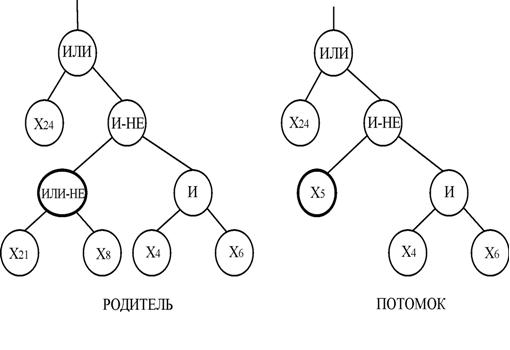
видалення оператора мутації проводиться так:
– випадковим чином вибирається вузол;
– випадковим чином вибирається символ з заданого термінальної множини;
– обрізається гілка обраного вузла мутації;
– замість обрізаної гілки ставиться термінальний символ.
Приклад видалення оператора мутації показаний на рис.8.
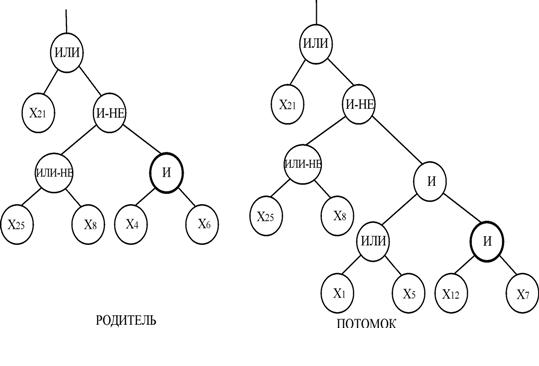
Зростаючий оператор мутації виконується наступним чином:
– випадковим чином визначається вузол мутації;
– якщо вузол не є термінальним, то необхідно відсікти гілки, які виходять з нього, інакше вибрати інший вузол;
– обчислити глибину залишка дерева;
– замість відтятої гілки дерева, виростити випадковим чином нову гілку так, щоб розмір нового побудованого дерева не перевищував заданий поріг.
Приклад зростаючого оператора мутації показаний на рис.9. Це дуже потужний оператор, що володіє великими можливостями.
4.Редукція. Оператор редукції виконується з метою збереження розміру популяції. Типи оператора практично збігаються з типами оператора відбору батьків. Але процедури редукції і відбору батьків рознесені по дії в часі і мають різне значення. Можливе виконання наступних варіантів редукції:
– елітна стратегія;
– чиста заміна;
– рівномірна випадкова заміна (із зазначенням кількості замінних особин у відсотках).
Як критерій зупинки можна використовувати вказівку певного числа ітерацій, або вказівка певного числа повторення найкращого результату.
4.4 Застосування генетичного програмування для отримання правил
Не менш важливо побудувати систему правил, які полегшать інтерпретацію результату. Для вирішення такого завдання запропоновано метод, основна ідея якого полягає в способі кодування особин для ДП. Як і раніше, особина представляє собою дерево, тільки тепер воно відповідає синтаксичному вислову, який представляє булеву функцію в диз'юнктивній нормальній формі (ДНФ), що повністю відповідає постановці завдання.
На рис.10 представлений приклад дерева, якому відповідала б функція в диз'юнктивній нормальній формі. Таке кодування особини для ДП значно спрощує інтерпретацію результату. Розглянуте дерево складається з 4 правил, розшифровка для даного прикладу буде наступною:
ЯКЩО виконується правило 1 АБО виконується правило 2 АБО виконується правило 3 АБО виконується правило 4, ТО результат 1, ІНАКШЕ результат 2.
Висновки
Проведено аналіз сучасних методів вилучення знань. Показано, що методи машинного навчання на основі використання навчальних даних мають переваги в порівнянні з іншими математичними методами. Розглянуто методи штучного інтелекту на базі машинного навчання. Відзначено, що ДП має потужні можливості пошуку закономірностей, розглянуті параметри, що впливають на його ефективність, значення яких залежать від конкретного завдання.
Поставлено мету роботи – автоматизувати процес розробки продукційних правил для ЕС.
Для цього необхідно вирішити завдання:
1. Pозробити структуру ЕС.
2. Pозробити продукційні правила.
Для вирішення перерахованих завдань обрано такі напрямки досліджень:
1. Методи інтелектуального аналізу даних з метою отримання продукційних правил.
2. Принципи побудови експертних систем.
Виконано математичну постановку задачі, стосовно до задачі класифікації на два класи.
Перелік посилань
-
Системы поддержки принятия решений / Интернет-ресурс. — Режим доступа: http://bourabai.kz/tpoi/dss.htm
-
Генетические алгоритмы / Интернет-ресурс. — Режим доступа: https://ru.wikipedia.org/wiki/
-
Генетические алгоритмы Т.В. Панченко / Интернет-ресурс. — Режим доступа: http://mathmod.aspu.ru/images/File/ebooks/GAfinal.pdf
-
Goldberg D.E. Genetic Algorithms in Search, Optimization and Machine Learning.-Addison-Wesley, reading,MA.-1989.
-
Koza J.R. Genetic Programming.Cambridge:MA:MIT Press,1992.
-
Рутковская Д., Пилинский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы: Пер. с польск. И.Д. Рудинского. - М.: Горячая линия – Телеком, 2006. – 452 с. : ил.
-
Гомзин А., Коршунов А. Системы рекомендаций: обзор современных подходов // Препринт. Москва: Труды Института системного программирования РАН. 2012. 20 c.