
Abstract
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the system
- 3. The mathematical formulation
- Conclusion
- References
Introduction
The efficiency of virtually any industry is largely determined by the level of information technologies and the breadth of their application. This factor becomes critical in practical development of any area.
In the development of ES usually used production models.
Production model – is the most common in the present day knowledge representation model, where knowledge is described using the rules "if–then" (the phenomenon > reaction) and are presented in the form: if (antecedent) then the action (consequent). System support decision–making is designed to support multicriteria decisions in a complex information environment. Thus, under the multicriteria it understood the fact that the results of the decisions are evaluated not by one, but by a set of multiple indicators (criteria) are considered simultaneously. Information complexity is determined by the need to allow large amounts of data, which the treatment without the aid of modern computer technology is almost impossible. Under these conditions, the number of possible solutions are usually very large, and selecting the best one "eye", without the full analysis can lead to serious errors.
Under the condition refers to a proposal sample, which is used by search in the knowledge base, and under the influence – a set of actions performed on a successful outcome of the search. Inside consequent may also be generated and added to the new data base, which was obtained by computation or user interaction.
If you are using these models for systems based on knowledge, it is possible to:
- use of a simple and precise knowledge of the use of the mechanism;
- knowledge Representation with high uniformity, described by a single syntax.
These two distinctive features led to wide distribution methods of knowledge representation by rules. But obtaining such rules is one of the most time–consuming tasks.
1. Theme urgency
At the moment, the process of obtaining production rules is an indispensable factor for the ES in the field of knowledge representation. This is due to the fact that machine learning methods based on the use of training data have advantages over other mathematical methods.
With the development of computer technology, all the data and methods of artificial intelligence based on machine learning methods for the Intellectual analysis will quickly and efficiently receive production rules for the extraction of knowledge and gain new and more updated knowledge using training examples.
Thus, the development of this software application is relevant, effective and efficient solution for future system users.
2. Goal and tasks of the system
The aim of this work is to develop a mathematical apparatus for production rules for the ES.
It is necessary to solve the problem:
- to develop the structure of ES;
- to develop production rules.
In order to solve the following research areas selected following tasks:
- methods of data mining in order to obtain production rules;
- principles of expert systems.
3. The mathematical formulation
Let the vector of input variables, see. fig.1, for each i–th variable is defined a vector of valid values, see. fig.2 where s – the number of valid values, Xi different for each entry.
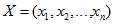
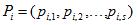
Then, for example, in dealing with the problem of classification into two classes with the binary input arguments, the rule can be represented as follows:
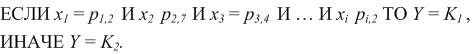
Often there are several such rules, for example:
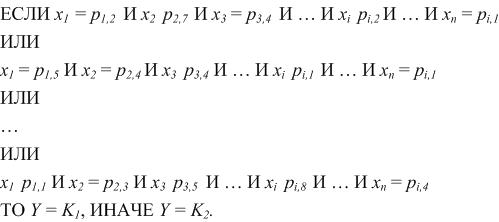
In this case, a system of rules can now be described as follows:
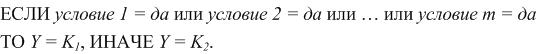
Where is the i–th condition may correspond to, for example, such a condition:
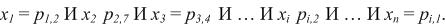
These rules can be formally described as follows:
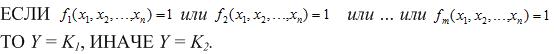
In this interpretation of the rules is necessary for building a Boolean search function of the form (3)
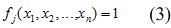
And then the whole system of rules will be represented as:
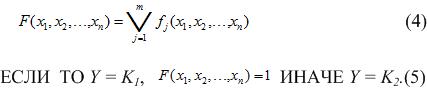
Then the function is defined in the (4), and:
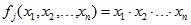
at the same time the presence of each factor is not necessarily present and each factor can be in direct or inverted state (NOT operation). The basis of the logic functions can also be changed. Development of rules is reduced to finding a specific function or functions of the system and F is to construct boolean functions (3).
The criteria for assessing the quality of the obtained solution may be to assess accuracy. Let the criterion for evaluation is the error E (F), then the task of finding solutions reduces to finding functions F, so that the following condition:
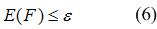
where e – permissible classification error
.As a classification error can be used:
-
the proportion of correct classification (7);
-
mean square error (8);
-
The average absolute error (9);
-
criterion is the amount of error squares (10).
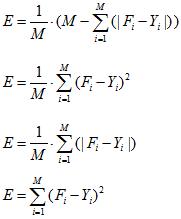
where M – the number of training examples, F – the result, Y – the desired result.
Application of genetic programming to solve the problem
GP machine allows you to build with the help of evolutionary algorithm based on training sample program, which will build the production rules for the classification into two classes. In accordance with the statement of the problem is necessary to construct a boolean function of the form (11):
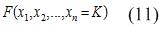
The value of the K, equal to one, means belonging to the same class, and zero – to another.

(ŕnimation: 10 frames, 10 cycles of repetition, size 572x706, 145 Šb, 1 fps)
The data should be pre–treated, the main purpose of pre–processing – convert the input training set in boolean–valued vector. Further in accordance with the algorithm defined above and terminal functional set fitness function values evolutionary algorithm parameters. Solution of the problem is a boolean function (11), presented in the form of a tree.
The terminal set in the present case consists of input variables, which, after pre–treatment is a boolean–valued vector.
The function set. The basic logic operations are: OR, AND, NOT. All these operations are always one output, but may have a different number of inputs. Since the first two features may have two or more inputs, and only the last one, the more convenient for a software implementation replacement operations NOT perform the following two: NOR and NAND. Such a change would allow to unify the number of entries for all operations (they will always be 2). Thus the functional set up four logical functions OR, AND, NOR and NAND. This allows the logical basis to get rid of the so–called introns (useless pieces of code), in this case of double negation (NOT (NOT (X))).
As a fitness function is used with the correct proportion of a certain class (7).
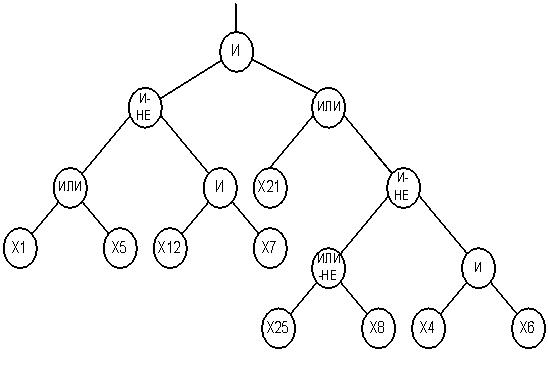
So, in the context of our problem GP is used to obtain a classification tree (an example of the structure shown in fig.4. The tree in fig. 4 corresponds to the boolean function (12):
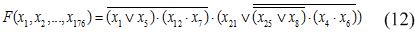
A generalized algorithm for obtaining such trees and rules using genetic programming is shown in fig.3.
The following steps must be performed to obtain a classification tree:
1. Set parameters SE.
2. Generate initial population. The population consists of a number of chromosomes (individuals). Each individual corresponds to a tree, which is a solution, such as in fig.4. Individual (tree) initially randomly generated and consists of nodes and terminal functionalities.
3. As the value of the fitness function (7) to evaluate all the individuals included in the population.
4. Run genetic operators.
5. Check the stop condition. If the stop criterion is met, then go to step 6, otherwise to step 3.
6. Choose the best individual (with a maximum value of fitness–function), which will be the result of the SE and the corresponding tree – a solution of the problem (classification tree classifies into two classes).
Conclusion
The analysis of modern methods of knowledge extraction. It has been shown that the methods of machine learning based on the use of training data have advantages over other mathematical methods. Methods of artificial intelligence based on machine learning have been reviewed. It is noted that the GP has powerful search capabilities laws considered parameters affecting its effectiveness, which values depend on the particular task.
The aim of the work – to automate the process of development of production rules for the ES.
It is necessary to solve the problem:
1. Develop structure ES.
2. Develop production rules.
In order to solve the following research areas selected following tasks:
1. Methods of data mining in order to obtain production rules.
2. Principles of expert systems.
A mathematical formulation of the problem in relation to the problem of classification into two classes.
References
-
Ńčńňĺěű ďîääĺđćęč ďđčí˙ňč˙ đĺřĺíčé / Číňĺđíĺň-đĺńóđń. — Đĺćčě äîńňóďŕ: http://bourabai.kz/tpoi/dss.htm
-
Ăĺíĺňč÷ĺńęčĺ ŕëăîđčňěű / Číňĺđíĺň-đĺńóđń. — Đĺćčě äîńňóďŕ: https://ru.wikipedia.org/wiki/
-
Ăĺíĺňč÷ĺńęčĺ ŕëăîđčňěű Ň.Â. Ďŕí÷ĺíęî / Číňĺđíĺň-đĺńóđń. — Đĺćčě äîńňóďŕ: http://mathmod.aspu.ru/images/File/ebooks/GAfinal.pdf
-
Goldberg D.E. Genetic Algorithms in Search, Optimization and Machine Learning.-Addison-Wesley, reading,MA.-1989.
-
Koza J.R. Genetic Programming.Cambridge:MA:MIT Press,1992.
-
Đóňęîâńęŕ˙ Ä., Ďčëčíńęčé Ě., Đóňęîâńęčé Ë. Íĺéđîííűĺ ńĺňč, ăĺíĺňč÷ĺńęčĺ ŕëăîđčňěű č íĺ÷ĺňęčĺ ńčńňĺěű: Ďĺđ. ń ďîëüńę. Č.Ä. Đóäčíńęîăî. - Ě.: Ăîđ˙÷ŕ˙ ëčíč˙ – Ňĺëĺęîě, 2006. – 452 ń. : čë.
-
Ăîěçčí Ŕ., Ęîđřóíîâ Ŕ. Ńčńňĺěű đĺęîěĺíäŕöčé: îáçîđ ńîâđĺěĺííűő ďîäőîäîâ // Ďđĺďđčíň. Ěîńęâŕ: Ňđóäű Číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. 2012. 20 c.