ИСПОЛЬЗОВАНИЕ БИНАРНОЙ ЛОГИСТИЧЕСКОЙ РЕГРЕССИИ ДЛЯ ОЦЕНКИ КАЧЕСТВА АДАПТИВНОГО ТЕСТА
Авторы: Е. В. Жилина
Источник:Журнал: Вестник томского государственного университета, май 2010 Ссылка
Аннотация
Приводится обоснование использования метода бинарной логистической регрессии для оценки качества адаптивного теста; приведен пример адаптивного тестирования, рассчитаны вероятности получения правильных ответов тестируемыми на каждом уровне знания.
Ключевые слова
Адаптивный тест; оценка качества; логистическая регрессия.
Адаптивный тест – это один из видов проверки знаний учащихся, предусматривающий изменение последовательности выдачи вопросов в процессе прохождения теста, учитывающий ответы тестируемого на предыдущие вопросы для определения трудности последующих вопросов [1]. Адаптивность сочетается с принципом «алгоритма–цепочки»: предъявление заданий с систематическим изменением уровня трудности.
Адаптивный тест как система обладает составом, целостностью и структурой. Тест состоит из заданий, правил их применения, оценок за выполнение каждого задания и рекомендаций по интерпретации тестовых результатов. Система означает, что в тесте собраны такие задания, которые обладают системообразующими свойствами. Хотя любой тест состоит из тестовых заданий, последние представляют не совокупность произвольно объединенных заданий, а именно систему. Время выделяют в качестве другого системообразующего фактора. Действительно, одно из соображений, положенных в основу создания адаптивных тестов, – иметь инструмент быстрого и относительно точного оценивания большого числа испытуемых. Требование экономии времени становится естественным в массовых процессах, каковым и стало образование. Одно из актуальных направлений современной организации тестового контроля – это индивидуализация контроля, приводящая к значительной экономии времени тестирования. От времени тестирования существенно зависит качество результатов. Каждый адаптивный тест имеет оптимальное время тестирования, необходимое для получения точной оценки тестируемого, уменьшение или превышение которого снижает качественные показатели теста
Эффективным можно назвать тест, который лучше, чем другие тесты, измеряет знания студентов интересующего уровня подготовленности, с меньшим числом заданий, качественнее, быстрее, дешевле, и все это – по возможности в комплексе [2]. С понятием «эффективность» сопряжено и близкое к нему по содержанию понятие «оптимальность». Последнее трактуется как наилучшее из возможных вариантов, с точки зрения удовлетворения нескольким критериям, взятым поочередно или вместе. В определении эффективности теста учитываются два ключевых элемента: число заданий теста и уровень подготовленности студентов. Если из какого-либо теста с большим числом заданий сделать оптимальный выбор меньшего числа, то может образоваться система, не уступающая заметно по своим свойствам тесту со сравнительно большим числом заданий.
Тест с меньшим числом заданий в таком случае можно называть сравнительно более эффективным
Помимо этого, эффективность теста можно оценить с точки зрения соответствия уровня его трудности уровню подготовленности тестируемых в данный момент студентов. Эту оценку в литературе нередко относят к валидности, имея в виду идею валидности теста, так сказать, по уровню. Легко понять практическую бесполезность того, чтобы давать слабым студентам трудные задания; большинство студентов, вероятнее всего, не сумеют правильно на них ответить. Так же обстоит дело и с легким тестом: его бесполезно (неэффективно) давать знающим студентам, потому что и здесь высока вероятность теперь уже правильных ответов, и потому практически все испытуемые получат по тесту одинаково высокий балл. И в том и в другом случае испытуемые не будут различаться между собой. Измерение, таким образом, не состоится по причине несоответствия уровня трудности теста уровню подготовленности. Из этих соображений легко вывести, что самый эффективный тест – это тест, точно соответствующий по трудности заданий уровню подготовленности испытуемых.
Эффективность теста зависит также и от принципа подбора заданий. Если подбирать задания для измерения на всем диапазоне изменения трудности, то снижается точность измерения на отдельном участке. И наоборот, если стремиться точно измерить знания испытуемых, например среднего уровня подготовленности, то это потребует иметь больше заданий именно данного уровня трудности. Поэтому тест не может быть эффективным вообще, на всем диапазоне подготовленности студентов. Он может быть более эффективен на одном уровне знаний и менее – на другом. Именно этот смысл вкладывается в понятие дифференциальной эффективности адаптивного теста.
С помощью метода бинарной логистической регрессии можно исследовать зависимость дихотомических переменных от независимых переменных, имеющих любой вид шкалы. Как правило, в случае с дихотомическими переменными речь идёт о некотором событии, которое может произойти или не произойти; бинарная логистическая регрессия в таком случае рассчитывает вероятность наступления события в зависимости от значений независимых переменных [3].
Как известно, все регрессионные модели могут быть записаны в виде формулы
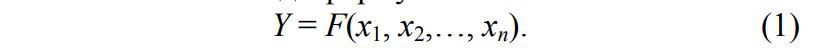
Например, в множественной линейной регрессии предполагается, что зависимая переменная является линейной функцией независимых переменных, т. е.
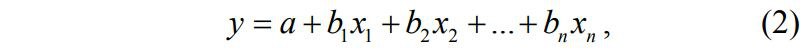
где x1 – значения независимых переменных, b1 – коэффициенты, расчёт которых является задачей бинарной логистической регрессии, a – некоторая константа.
Можно ли ее использовать для задачи оценки вероятности исхода события? Да, можно, вычислив стандартные коэффициенты регрессии. Например, если рассматривается исход по ответу на тестовое задание, задается переменная y со значениями 1 и 0, где 1 означает, что тестируемый правильно ответил на вопрос, а 0 – что неправильно. Однако здесь возникает проблема: множественная регрессия не «знает», что переменная отклика бинарна по своей природе. Это неизбежно приведет к модели с предсказываемыми значениями большими 1 и меньшими 0. Но такие значения не допустимы для первоначальной задачи. Таким образом, множественная регрессия просто игнорирует ограничения на диапазон значений для y.
Для решения проблемы задача регрессии может быть сформулирована иначе: вместо предсказания бинарной переменной мы предсказываем непрерывную переменную со значениями на отрезке [0,1] при любых значениях независимых переменных. Это достигается применением следующего регрессионного уравнения (логит-преобразование):
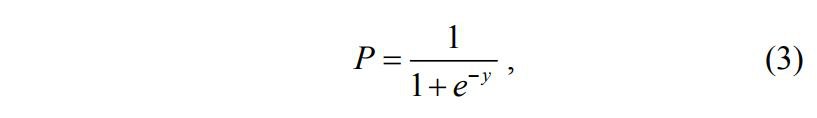
где P – вероятность того, что произойдет интересующее событие; e – основание натуральных логарифмов 2,71…; y – стандартное уравнение регрессии [4].
Если для P получится значение меньшее 0,5, то можно предположить, что событие не наступит; в противном случае предполагается наступление события.
Поясним необходимость преобразования. Предположим, что мы рассуждаем о нашей зависимой переменной в терминах основной вероятности P, лежащей между 0 и 1. Тогда преобразуем эту вероятность P:
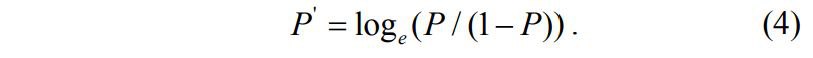
Это преобразование обычно называют логистическим или логит-преобразованием. Теоретически P’ может принимать любое значение. Поскольку логистическое преобразование решает проблему об ограничении на 0–1 границы для первоначальной зависимой переменной (вероятности), то эти преобразованные значения можно использовать в обычном линейном регрессионном уравнении. А именно: если произвести логистическое преобразование обеих частей описанного выше уравнения, мы получим стандартную модель линейной регрессии [4].
Существует несколько способов нахождения коэффициентов логистической регрессии. На практике часто используют метод максимального правдоподобия.
Нами предлагается использовать метод бинарной логистической регрессии для оценки вероятностей получения правильного ответа на задание по каждому уровню знания как один из критериев качества адаптивного теста, уменьшающий время его прохождения, число заданий и увеличивающий точность оценки.
Предположим, что испытуемый начал тестирование с вопроса, соответствующего уровню 3, шаг контрольной точки равен 5, максимальное количество шагов тестирования равно 6, на первом шаге адаптации были получены следующие результаты (рис. 1, шаг 1; «+» отмечен правильный ответ, «–» – неправильный) (на основе метода, предложенного в (5)).
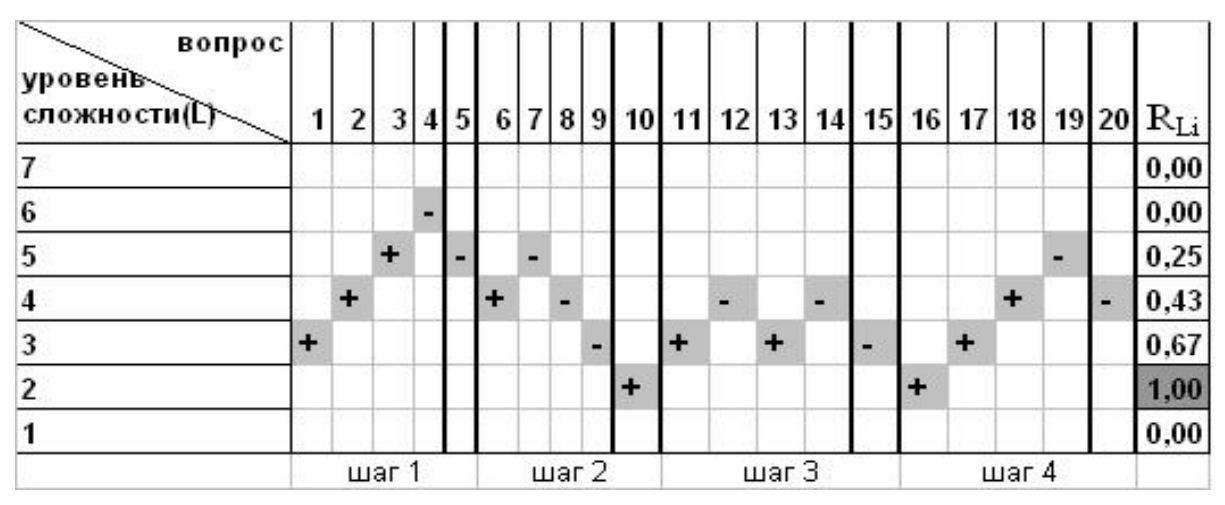
Рисунок 1 – Пример адаптивного теста
«Промежуточные уровни знания» используются во избежание случайности ответов (как положительных, так и отрицательных). Поэтому под термином «промежуточные уровни знания» понимаем логическое распределение уточняющих вопросов на оценки 3, 4, 5 (уровни знания соответственно равны 3, 5, 7).
Используя программный продукт STATISTICA 6.0, были обработаны результаты тестирования каждого шага адаптации. Исходные данные приведены на рис. 2.
Гипотеза H(0) предполагает, что тестируемый ответит на вопрос правильно (1).
На первом шаге адаптации были получены следующие результаты логистической регрессии (см. рис. 3).
Далее, согласно формуле 3, вычисляем вероятности (Р1) того, что тестируемый на данном шаге адаптации ответить правильно на вопрос соответствующего уровня сложности (см. рис. 4). Р0 – начальное значение – принимаем равным 0,5 на каждом уровне сложности. Рассчитываем коэффициент изменения вероятности
Согласно алгоритму, предложенному в [5], шагов адаптации должно быть не менее двух, поэтому тестируемому предлагается продолжить тест далее (рис. 1, 2, шаг 2). На втором и третьем шаге адаптации были получены следующие результаты логистической регрессии (рис. 5, а, б) и рассчитаны вероятности (Р2, Р3, ΔР) (рис. 4).
Вычисляем вероятности (Р4, ΔР) (см. рис. 7). Анализируем полученные результаты: р-уровень менее 5%, следовательно, модель значима; значение статистики хи-квадрат для разницы между текущей моделью и моделью, содержащей лишь свободный член, высоко значимо.
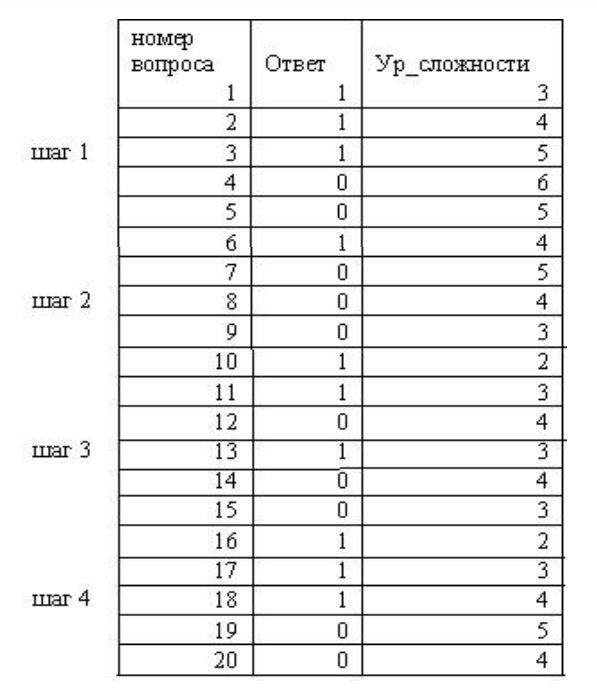
Рисунок 2 – Исходные данные для моделирования логистической регрессии
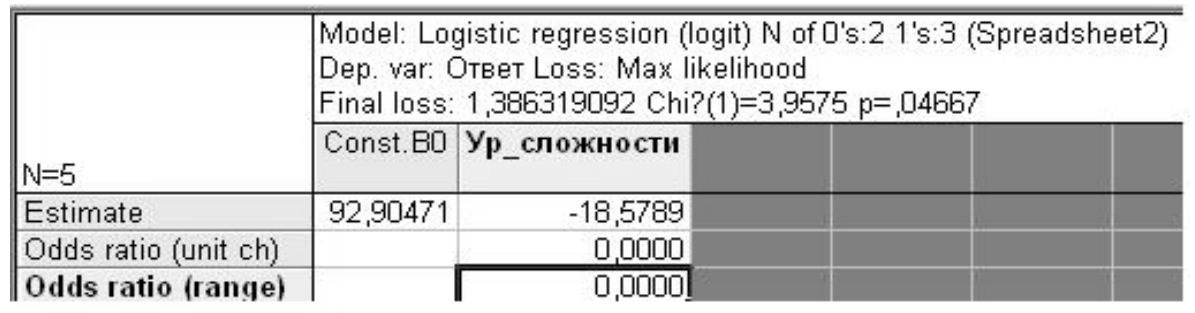
Рисунок 3 – Результаты логистической регрессии 1-го шага адаптации теста
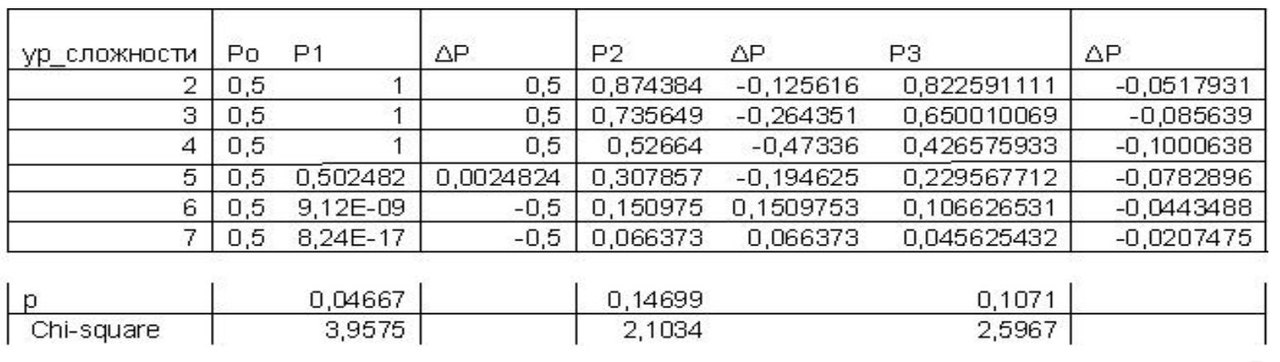
Рисунок 4 – Рассчитанные вероятности наступления события «1» на 1–3-м шагах адаптации
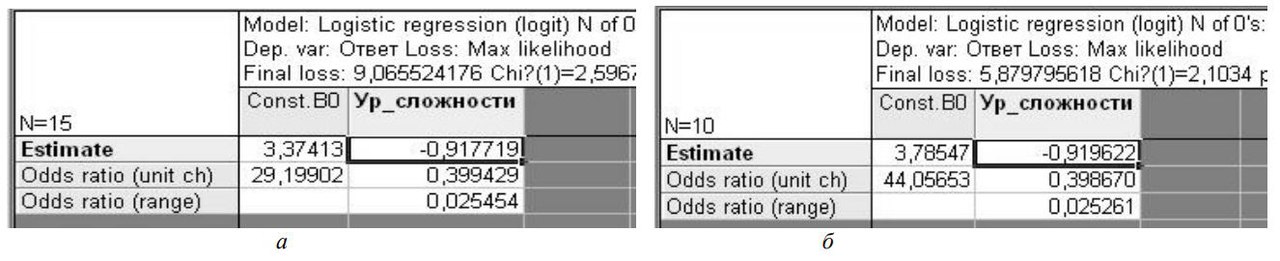
Рисунок 5 – Результаты логистической регрессии 2-го (а) и 3-го (б) шагов адаптации теста
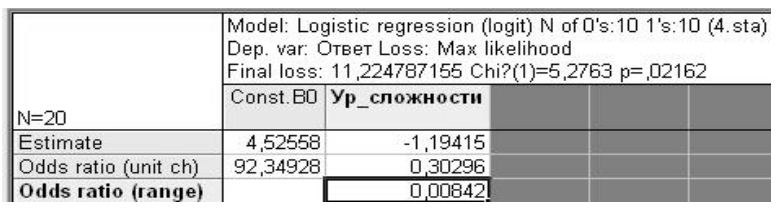
Рисунок 6 – Результаты логистической регрессии четвертого шага адаптации теста
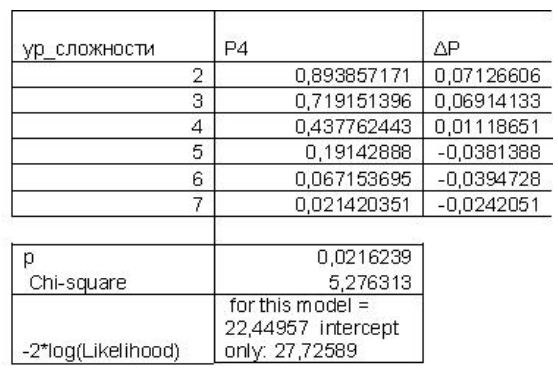
Рисунок 7 – Рассчитанные вероятности наступления события «1» на 4-м шаге адаптации
Одним из критериев оценки качества логистической регрессии является отношение несогласия (Odds ratio) (рис. 8), полученное методом классификации наблюдений.
Отношение несогласия вычисляется как отношение произведения чисел правильно расклассифицированных наблюдений к произведению чисел неправильно расклассифицированных. Отношение несогласия больше 1 показывает, что построенная классификация лучше, чем если бы мы просто провели классификацию наугад.
Нами предлагается интерпретировать результаты классификации наблюдений для установления количества угаданных ответов и количества случайных ошибок (рис. 8).
В рассматриваемом нами примере адаптивного теста четвертый шаг адаптации является заключительным.
Согласно алгоритму, предложенному в [5], на данном этапе тестируемый выходит на уровень знания 2 (коэффициент RLi = 1,00). Результаты логистической регрессии не противоречат этим данным: вероятность Р4 для уровня 2 максимальна, ΔР – положительна, р-уровень более 5%, Odds ratio более 1.
Далее переводим полученный результат в оценку (рис. 9).
Из вышесказанного можно сделать вывод: метод бинарной логистической регрессии рекомендуется применять для анализа качества адаптивного тестирования, при этом уменьшая время тестирования, число заданий и увеличивая точность оценки тестируемого; результаты моделирования показывают, что уровень сложности задания влияет на успехи тестируемого в выполнении адаптивного теста.

Рисунок 8 – Отношение несогласия
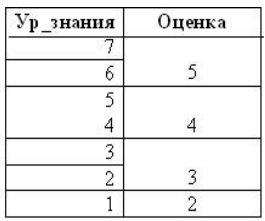
Рисунок 9 – Шкала перевода уровня знания (уровня сложности) в оценку