
Abstract
Content
- Introduction
- 1. Relevance of the topic
- 2. The purpose and objectives of the study, the planned results
- 3. An overview of existing methods for image contour extraction
- 4. Overview of international sources
- 5. Selection and description of image elements
- 6. Overview of some existing methods
- 6.1 Canny Boundary Detector
- 6.2 Tracking Algorithms
- 6.3 Ways to describe contours
- Conclusions
- List of sources
Introduction
The selection of the boundaries of images is a key element of modern computer vision systems in solving a number of applied problems associated with pattern recognition. Borders are a subset of the points in the original image associated with the borders of objects or other essential elements of the image.
Algorithms for selecting borders and binding them to essential elements of the image are called edge detection (edge ??detection). The points of the image in which the brightness varies especially strongly are called edge points, and their combination forms the edges of the image areas. Edge detectors use a local image fragment to analyze the belonging of the point of interest in the source image, based on the analysis of which it is concluded that there is an edge point.
1. Relevance of the topic
Selecting the boundaries of images is a key element of modern computer vision systems in solving a number of applied problems associated with pattern recognition. The scientific novelty of this work is the development of the algorithm for the selection of contours on low-contrast half-tone images. The existing algorithms for contour extraction do not cope well with the low contrast of objects and background, and are also extremely sensitive to noise in the image. The developed algorithm will be aimed at maximizing all the object boundaries and suppressing the detected false contours, which often arise from the presence of impulse noise.
When analyzing images and recognizing objects that are present on it, methods and algorithms for selecting contours take on a significant share, since they greatly simplify working with an image and / or digital series. But most of the existing algorithms today can not provide a sufficiently good accuracy of the selection of the contour of objects, since there are always gaps and false boundaries. This greatly complicates further work on the image. This work is aimed at developing an algorithm that allows you to maximally improve the selection of image boundaries by combining and modifying existing algorithms for finding object contours in an image using various recognition methods.
2. The purpose and objectives of the study, the planned results
The purpose of writing the work is to research and develop algorithms for the Edge Detection task on noisy images using evolutionary algorithms. And also get acquainted with the use of various methods of recognition.
As a rule, edge detectors provide a large output when there are sharp local variations in brightness. A wide class of vision systems is operated in the presence of noise and interference. Noise significantly distorts information about the position of edge points, which leads to the appearance of two types of possible errors. The first type is associated with the omission of a really existing boundary point, and the second, with the appearance of a false one. Edge detector CANNY is considered one of the best, it is not operational in the presence of noise.
The main objectives of the study:
Improving the quality of edge detectors requires an increase in the area of ??the image fragment used to make a decision about the presence of an edge point, as well as complex processing algorithms. From the point of view of implementation, this means the need to perform a large amount of computation. Naturally, for video systems, the complexity of implementing noise-resistant border filters is significantly more difficult because of the need to process 25 - 30 frames per second.
It can be stated that the problem of developing noise-tolerant edge detectors is relevant, and the ways to solve it largely determine the parameters of the vision subsystems. As the analysis shows, the solution to the problem of processing video information is impossible without the use of parallel computing. One of the possible options for the implementation of noise-resistant edge detectors is to use the methodology of neural networks.
3. Review of research and development
Selecting the contours of images - the definition in the theory of image processing and computer vision, partly from the area of ??searching for objects and selecting objects, is based on algorithms that highlight digital image points where brightness changes dramatically or there are other types of discontinuities.
In the ideal case, the result of the selection of contours is a set of connected curves denoting the boundaries of objects, faces and prints on the surface, as well as curves reflecting changes in the position of the surfaces. Thus, applying a border selection filter to an image can significantly reduce the amount of data being processed, due to the fact that the filtered part of the image is considered less significant, and the most important structural properties of the image are preserved.
However, it is not always possible to isolate the contour in the pictures of the real world of medium complexity. Borders separated from such images often have such disadvantages as fragmentation (the curves of the contours are not connected to each other), the absence of borders or the presence of false ones that do not correspond to the object being studied.
There are many approaches to isolating image outlines, but almost everything can be divided into two categories: methods based on searching for maxima and methods based on searching for zeros.
Methods based on searching for maxima outline the contours by calculating the "edge force", usually the expression of the first derivative, such as the magnitude of the gradient, and then searching for local maxima of the edge strength using the expected direction of the contour, usually perpendicular to the gradient vector.
Methods based on searching for zeros look for intersections of the x-axis of the second derivative, usually zeros of Laplacian or zeros of a non-linear differential expression. As a preprocessing step, smoothing of the image, usually a Gaussian filter, is almost always applied to the selection of borders. The contour selection methods differ by the smoothing filters used. Although many border selection methods are based on calculating an image gradient, they differ in the types of filters used to calculate gradients in the x- and y-directions.
4 Overview of international sources
In (Gonzalez, Woods), Chapter 10[1] is devoted to image segmentation, and Chapter 11 is about their presentation and description. The detail of the presentation of all questions is quite high. This book is best suited for additional study of this topic in general.
In work (Zarit) Chapter 9[2] is devoted to the analysis and synthesis of textural textures based on frequency approaches and various expansions[3]. Since this question is not addressed at all in our short course, this chapter can be recommended in its entirety as a material for additional self-study.
Chapter 7[3] is devoted to working with textures in the work (Laxmi, Sankakanyanan). The logic of presentation corresponds to our course, but the volume is much larger and the presentation is more detailed and deeper. Since the topic of texture analysis is described by us extremely briefly, this chapter can also be recommended entirely as a material for additional self-study.
In Chapters 14 and 16 of work (Zuev)[4], the problem of image segmentation (in a broad sense) is considered respectively in the context of clustering (partitioning the sample into classes) and probabilistic optimization (maximum of a posteriori probability and Bayesian approach). These approaches to the segmentation of images on the field are practically not disclosed in our course, so it is recommended to get acquainted with the 14 and 16 chapters of the book as part of an in-depth self-study of this course.
5. Selecting and describing image elements
As the demands on the accuracy and reliability of detection algorithms for more and more complex objects in an increasingly complex real situation increase, the shortcomings of this group of methods have become more pronounced. This is, first of all, a high probability of anomalous errors, the need to have a large number of standards to describe multi-dimensional images of three-dimensional objects, and instability with respect to the brightness-geometric variability of images that occurs in real-world recording conditions. Thus, there has been a transition from correlation detectors of given images to methods and algorithms for structural image analysis.
At present, the sequence of image processing procedures is considered in accordance with the so-called Marr paradigm. This paradigm proposed by D. Marr based on a long study of the mechanisms of human visual perception, argues that image processing relies on several successive levels of the ascending information line "the iconic representation of objects (bitmap, unstructured information) - a symbolic representation (vector and attribute data in a structured form, relational structures) "and should be implemented on a modular basis through the following processing steps:
- Image preprocessing;
- Primary image segmentation;
- Selecting the geometric structure of the visible field;
- The definition of the relative structure and semantics of the visible scene.
The associated processing levels are usually referred to as lower, middle, and high level processing, respectively. While low-level processing algorithms (simple noise filtering, histogram processing) can be considered as well-developed and thoroughly studied, the average level algorithms (segmentation) continue to remain the central field of application of research efforts. In recent years, significant progress has been made in relation to the problems of matching points and image fragments (matching) of feature extraction inside small fragments of high-precision 3D-positioning of points, which implies proper modeling and calibration of sensors and their combinations, selection of simple bright-geometric structures of the "dot "," edge "," spot "," straight line "," angle ". These "primary" features of the image, also called the characteristic features (CC), play a basic role in the compilation of bright-geometric models of objects and the development of robust algorithms for their selection.
Figure 5.1 shows the classification of features (HC) that may be present in the images.
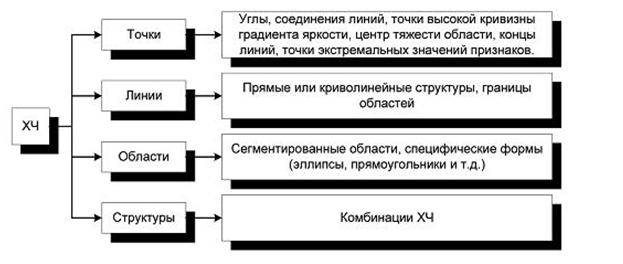
Figure 5.1 - Classification of Characteristic Features (HC)
When working with real images, the listed criteria are inconsistent. Therefore, the specific choice of HF and their attributes depends on the available computing power and on the minimum required robustness of describing the object model in terms of HH. This table demonstrates the inconsistency of different types of hCh in the sense of different criteria. If we talk about methods and algorithms for detecting complex objects, then one of the central problems that distinguish image processing methods from the well-studied theory of signal processing is the development of methods for detecting objects that are weakly sensitive to various types of variability characteristic only of images. Such specific types of variability are the perspective and radiometric distortions, as well as various types of distortions that are not reducible to probabilistic models (form noise). On the way of combating them, both a huge number of heuristic algorithms for detecting specific types of objects and a number of approaches that have more commonality were proposed: methods of correlation detection, Hough transformation, morphological approaches of Pyt'ev and Serra. A significant contribution to the development of methods and algorithms for image processing and machine vision as applied to the discussed detection problems was made by the works of L.P. Yaroslavsky, V.K. Zlobin, V.L.Levshina, R.Haralika, E.Devisa, R.Nevatia, E Dickmanns, W. Ferstner and many others. However, despite the results achieved, the general state of the problem of isolating and identifying complexly structured objects in monoscopic images can be characterized as unsatisfactory. Even more difficult is the task of detecting three-dimensional structures on stereoscopic images. Here only approaches to more general settings are outlined.
6. Review of research and development
6.1 Canny Boundary Detector
John Canny described the boundary detection algorithms, which have since become one of the most widely used. We can say that they have become classics in the detection of boundaries. Canny proceeded from three criteria that the boundary detector must satisfy:
- Good detection (Canny interpreted this property as an increase in the signal-to-noise ratio);
- Good localization (correct determination of the position of the border);
- The only response to one border.
From these criteria, the objective function of the cost of errors was then constructed, the minimization of which is the “optimal” linear operator for convolution with the image. The Canny Boundary Detection algorithm is not limited to calculating the gradient of a smoothed image. In the contour of the border, only the maximum points of the gradient of the image are left, and not the maximum points lying near the border are removed. It also uses information about the direction of the border in order to remove points exactly near the border and not to break the border itself near the local maxima of the gradient. Then, using two thresholds, weak boundaries are removed. Fragment of the border is treated as a whole. If the value of the gradient somewhere on the traceable fragment exceeds the upper threshold, then this fragment also remains the “acceptable” boundary in those places where the gradient value falls below this threshold until it falls below the lower threshold. If there is not a single point on the entire fragment with a value greater than the upper threshold, then it is deleted. Such a hysteresis reduces the number of breaks in the output limits. The inclusion of noise cancellation in the Canny algorithm, on the one hand, increases the stability of the results, and, on the other hand, increases computational costs and leads to distortion and even loss of the details of the boundaries. So, for example, this algorithm rounds the corners of objects and destroys the boundaries at the junction points[5][6].
6.2 Tracking Algorithms
Tracking methods are based on the fact that an object is searched for on the image (the first point of the object that was encountered) and the contour of the object is tracked and vectorized. The advantage of these algorithms is their simplicity, the disadvantages include their consistent implementation and some complexity in the search and processing of internal contours, as well as the need to use scanning to detect very small contours.
An example of a tracking method - the beetle method - is shown in Figure 6.1. The beetle begins to move from the white area towards the black one. Once it hits the black element, it turns left and moves to the next element. If this element is white, then the beetle turns to the right, otherwise - to the left. The procedure is repeated until the beetle returns to the starting point. The coordinates of the transition points from black to white and from white to black describe the boundary of the object.
Figure 3 shows the flowchart of such an algorithm.
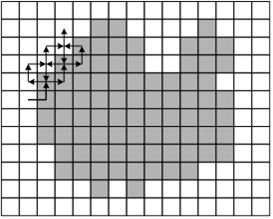
Figure 6.1 - The Beetle Method
The method based on sequential scanning of an image (Figure 6.2) is to search for such pairs of points for which the difference in intensity with adjacent points (along the scanning direction) is greater than a certain ? / 2 threshold, and the difference in intensity with all the points between those sought. exceeds this threshold[7]. The advantages of this method include the independence of processing time on the number of contours on the map and greater efficiency compared to tracking algorithms.
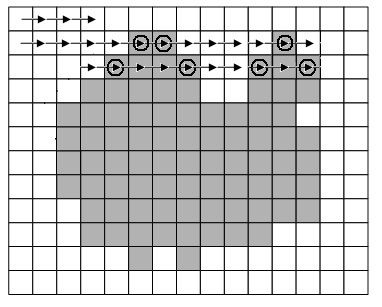
Figure 6.2 - Sequential scan method
6.3 Ways to describe contours
Discrete representation of a curve as a sequence of points with coordinates (x, y) is extremely inefficient. A more effective representation is with the help of chain codes (using a chain code) in which the vector connecting two adjacent points is encoded with one symbol belonging to a finite set[7]. Usually, when using a chain code, a neighborhood of a point of 3 ? 3 and 4 or 8 possible coding directions is considered (Figure 5.1).
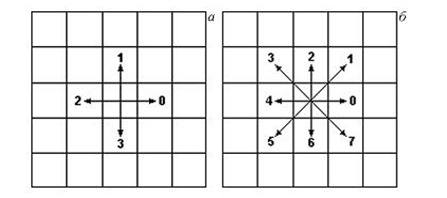
Figure 6.3 - Encoding directions in chain codes:
a ? 4 directions, b - 8 directions
Starting from the first point, the circuit is traversed in a clockwise direction, with each subsequent point being coded with the numbers 1 - 8, depending on its location relative to the center point of the neighborhood. The result of the coding is a sequence consisting of the numbers 1 - 8. An example of the curve coding using the chain code: 77121076667110076771122334. This way of presenting a curve has the following disadvantages.
- Dependency on coding start point.
- Does not have the property of invariance to rotation.
- Noise instability.
- The possibilities of integrated automation of the developed approach to the unification of the synthesis of Moore automata, software requirements were evaluated, functionally similar synthesis software was searched sequential logic circuits.

Figure 6.4 - The process of selecting the contours of the image
(animation: 7 frames, 7 cycles of repetition, 36 kilobytes)
Local contour changes can lead to different coding results. Another way to represent a curve is piecewise polynomial approximation. The task of approximation is to find a curve passing near a given set of contour points. The curve is divided by separate nodes into segments, and the approximating function on each of them has the form:

where an is the polynomial coefficients to be determined on each segment.
As characteristic features, you can use the number and positions of the singular points of the contour (points of maximum inflection, local extremes of the curvature function, end points, branch points). First of all, the so-called corner (control) points, that is, the points that have the maximum curvature in a certain neighborhood, try to be selected on the contour, since endpoints and branch points are not reliable enough signs and are largely subject to the effects of noise. Going back to point characteristics allows the identification methods described in the previous chapter[8] to be used.
The essential difference in the method of distinguishing characteristic points on the contours is that not the brightness, but the geometric features of the object are used as reference information.
In this paper, we considered various options for the selection of singular points on the resulting contours. The simplest and fastest way is the above described search for points of maximum inflection using an iterative algorithm for selecting end points. However, the use of this algorithm did not bring positive results. The instability of his work is determined by the rather strong dependence of the results of the search for points on the initial conditions (end points of the contour). Insufficient noise immunity does not allow using this method to highlight special points on contours.
7. Problems and unresolved issues in the area of ??contour image analysis
Investigating this problem, it becomes obvious that, on the one hand, this issue is covered very widely, although directly in Ukraine it is touched very superficially, more attention is paid to its study abroad[9]. Over time, research in the field of contour analysis methods is becoming deeper and deeper, but as the study area becomes wider, there are more and more questions for further consideration.
The problem of obtaining an ideal closed loop has not been solved yet, although modern methods quite approximate the solution of this problem. It also leaves open the question of how to discard false contours without affecting others that are true. In addition, often when receiving an image for further processing, the problem of superimposing a contour arises. Thus, the separation of contours is also still an unsolved problem.
Research in this area will be relevant until at least these issues are resolved[10]. Image processing is quite a modern problem and many scientists working in this direction offer their own methods of solution. For example, Fomin Ya. A. In his works “Pattern Recognition: Theory and Applications” offers the following idea: in his opinion, the accuracy of edge selection can be improved by tracing them on a sequence of images taken at different points in time.
Conclusion
In this paper, we considered various options for the selection of singular points on the resulting contours. The simplest method is the contour tracking described above using an iterative algorithm for selecting end points. However, the use of this algorithm did not bring positive results. The instability of his work is determined by the rather strong dependence of the results of the search points on the initial conditions (end points of the contour and image noise). Insufficient noise immunity does not allow using this method to highlight special points on contours.
In the future, an attempt will be made to delve into the research in order to introduce new technologies developed in various areas of activity. Abroad, the use of these algorithms for finding the contour of objects in noisy images is found almost everywhere, since the selection of the contours of individual objects makes it much easier to further search for these objects. Let us hope that the development of advanced technologies in this field in our time will also soon take place.
Note
When writing this essay, the master's work is not yet completed. Final completion: May 2019. Full text of the work and materials on the topic can be obtained from the author or his manager after the specified date.
List of sources
- Gonzalez D., Woods D., Hildreth E. Theory of edge detection / Dslash Proc. R. Soc. (London). 2009. B207. 187 - 217c.
- B.D. Zarit, International Journal of Computer Science & Information Technology (IJCSIT), 3 (6). - p. 259–267.
- Lakshmi S, Sankaranarayanan V. (2010) For computerized and computerized education approaches. - P. 35–41.
- Ramadevi Y. (2010) International Journal of Computer Science and Information Technology, Vol 2, No.6. - P. 153–161.
- Zuev A.A. Contour detection methods on images / Ŕ.Ŕ. Zuev, G.E. Necheporenko // MicroCAD International Scientific Conference: Section No. 8 - Microprocessor-based technology in automatics and application - NTU KPI, 2012. - P. 108.
- Samal DI Selection of signs for recognition based on statistical data / D.I. Samal, V.V. Golovenko - Minsk: ITK, 1999. - 218 c.
- Samal DI Methods of automated recognition of people based on portraits / D.I. Samal., V.V. Golovenko - Minsk: ITK, 1999. –187 p.
- Vapnik VN Theory of Pattern Recognition. / V.N. Vapnik, A. Ya. Chervonenkis - M .: Nauka, 1974. - 416 p.
- Fomin Ya. A. Pattern recognition: theory and applications / Fomin, Ya.A. - 2nd ed. - M .: FASIS, 2012. - 429 p.
- Cheng S.K. Principles of designing visual information systems / Cheng, Sh.K. - M .: Mir, 1994. - 408 p.
- Arkad'ev, A. G. Learning a machine for pattern recognition / A.G. Arkadiev, E.M. Braverman - M .: Science, 1964. - 478 p.