
Реферат по теме выпускной работы
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: июнь 2019 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Основные этапы определения жанра документа
- 4.1 Стемминг как первый этап обработки текста документа
- 4.2 Представление документа в векторно-пространственной модели
- 4.3 Описание прототипа программной системы определения принадлежности документа к определенному жанру
- Выводы
- Список источников
Введение
Основной проблемой анализа текстов является большое количество слов в документе и его неоднородность. Автоматизированный анализ текста в исходном виде – трудоёмкий и длительный процесс, учитывая то, что не все слова несут значимую для пользователя информацию. Кроме того, в силу гибкости естественных языков формально различные слова (синонимы и т.п.) на самом деле означают одинаковые понятия, большое число словоформ одного и того же слова усложняют поиск и систематизацию информации. Следовательно, удаление неинформативных слов, а также приведение слов к нормальной форме значительно сокращают время анализа текстов. Устранение описанных проблем является предварительным этапом анализа и поиска в документах, определения их схожести и жанра.
1. Актуальность темы
Поиск семантического сходства между текстами является серьёзной проблемой для автоматической обработки текста. Необходимость поиска расстояния между документами возникает в различных задачах, таких как обнаружение плагиата, определение авторства документа, поиск информации, машинный перевод, формирование тестов и задач, автоматическое построение рефератов и пр. Близка к классификации задача рубрицирования текста – его отнесение к одной из заранее известных тематических рубрик или жанру. Следовательно, задачи эффективной автоматизированной обработки текстов остаются актуальными, стабильное увеличение объёма информации требует постоянного совершенствования алгоритмов и подходов [1].
2. Цель и задачи исследования, планируемые результаты
Цель работы — проектирование и реализация системы определения жанра литературного произведения на основе технологии Text Mining.
Задачи исследования:
- рассмотреть методы и алгоритмы базовой обработки текста;
- изучить подходы к представлению документа;
- сформировать программный аппарат обработки документов на основании пространственно-векторной модели;
- разработать алгоритм определения принадлежности литературного произведения к определенному жанру.
Объект исследования: литературные произведения, классифицируемые по жанровой принадлежности.
Предмет исследования: алгоритмы и методы определения близости документов.
3. Обзор исследований и разработок
Исследуемая тема популярна не только в международных, но и в национальных научных сообществах.
3.1 Обзор международных источников
Среди международных источников нельзя выделить работы, связанные непосредственно с определением жанра литературных произведений на русском языке, однако в процессе поиска материалов были выделены работы, связанные с обработкой текста и общими подходами определения сходства или релевантности документа.
Так в статье Г. Солтона и К. Бакли Term-weighting approaches in automatic text retrieval
[2] обобщаются данные, полученные при автоматическом взвешивании терминов, и представлены базовые модели с одним индексом, с помощью которых можно сравнивать другие более сложные процедуры анализа контента. Также обоснован выбор эффективности использования данной весовой системы, ее сравнение с прочими, более сложными, и анализ экспериментальных данных, накопленных в процессе предыдущих исследований.
В книге К. Маннинга, П. Рагхаван, Х. Шютце Введение в информационный поиск
[3] рассматривается веб-поиск, включая смежные задачи классификации и кластеризации текстов. Кроме веб-поиска, в учебнике рассмотрены основные понятия и история классического информационного поиска и индексирования документов, методы оценки поисковых систем, а также введение в методы машинного обучения на базе коллекций текстов.
3.2 Обзор национальных источников
Поиск семантического сходства между текстами является серьёзной проблемой для автоматической обработки текста. Необходимость поиска расстояния между документами возникает в различных задачах, таких как обнаружение плагиата, определение авторства документа, поиск информации, машинный перевод, формирование тестов и задач, автоматическое построение рефератов и пр. Поиску семантической схожести текстов было уделено внимание в рамках многих международных и российских конференций такими авторами как Красников И.А., Керимова С.У., Ермоленко Т.В., Никуличев Н.Н. [4 - 5] .
В статье Яцко В.А. Алгоритмы и программы автоматической обработки текста
[6] даётся обзор наиболее распространённых алгоритмов и программ автоматической обработки текста. Описываются особенности алгоритмов и программ, применяемых на морфологическом, лексическом, синтаксическом и дискурсивном уровнях языковой системы.
Шарнин, М. М., Ищенко, Н. С., Пахмутова Н.Ю., Сюракшина Ю.В. в своей статье Использование методов тематического моделирования многоязычных коллекций для прогноза тревожных событий
[7] демонстрируют результаты практического применения методов тематического моделирования в мультиязыковых средах для мониторинга экстремистской активности в Интернете и прогноза тревожных событий. При работе с двумя корпусами текстов, содержащих экстремистскую идеологию радикальных мусульман и украинских националистов, подбираются оптимальные параметры для метода неявных ссылок, рассчитывается мера подобия корпусов текста, определяется общая и специфическая характерная терминологии двух корпусов текстов. Хотя направление магистерской работы не предполагает мультиязычности разрабатываемой системы или прогноза, данные материал позволяет сделать вывод о широких возможностях и сферах применения автоматической обработки текста.
Авторы Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. в своей работе Автоматическая обработка текстов на естественном языке и компьютерная лингвистика
[8] рассматривают базовые вопросы компьютерной лингвистики: от теории лингвистического и математического моделирования до вариантов технологических решений. В статье приведены сведения, необходимые для создания отдельных подсистем, отвечающих за анализ текстов на естественном языке, рассмотрены вопросы построения систем классификации и кластеризации текстовых данных, основы фрактальной теории текстовой информации.
Данный научный труд лежит в основе более предметных исследований Ягуновой Е.В. в работах Экспериментально- вычислительные исследования художественной прозы Н.В. Гоголя
[9] и Ключевые слова в исследовании текстов Н.В. Гоголя
[10] . В статьях представлены этапы анализа семантической и информационной структур, где первая в наибольшей степени соотносится со стилем (характерном для писателя, цикла, произведения), а вторая – с содержанием произведения и/или цикла. Автор демонстрирует возможности использования формальных признаков (видов распределения в тексте) и излагает свою методику и подход к классификации типов ключевых слов произведения.
3.3 Обзор локальных источников
В реферате Леонова А.Д. Методы автоматизированной коррекции специализированных естественно-языковых текстов
[11] рассмотрены алгоритмы морфологического и синтаксического анализ: стемминг, метод n-грамм и прочие, выделены области их применения и сформулированы общие выводы по теме.
Стуликова Н.В. в реферате по теме магистерской работы [12] рассматривает подходы и методы автоматического реферирования, проводит анализ существующих систем реферирования такие как Intelligent Text Miner, Золотой ключик и TextAnalyst.
4. Основные этапы определения жанра документа
4.1 Стемминг как первый этап обработки текста документа
Основная задача лексического анализа - распознать лексические единицы текста. Базовым алгоритмом является лексическая декомпозиция, которая предусматривает разбивку текста на токены. В данном контексте токенами могут быть это слова, словоформы, морфемы, словосочетания и знаки препинания, даты, номера телефонов и пр [13].
Лексическая сегментация имеет фундаментальное значение для проведения автоматического анализа текста, поскольку лежит в основе большинства других алгоритмов. Следующим шагом обработки исходного произведения является стемминг, на вход которого подается готовый список токенов.
Стемминг — это процесс нахождения основы слова для заданного исходного слова. Основа слова необязательно совпадает с морфологическим корнем слова. Стемминг применяется в поисковых системах для расширения поискового запроса, ускорения времени обработки запроса, является частью процесса нормализации текстов [14].
Стеммеры принято классифицировать на алгоритмические и словарные. Словарные стеммеры функционируют на основе словарей основ слов. В процессе морфологического анализа такой стеммер выполняет сопоставление основ слов во входном тексте и в соответствующем словаре, а анализ начинается с начала слова. Используя словарный стеммер, повышается точность поиска, однако увеличивается время работы алгоритма и объём памяти, занимаемой словарями основ.
Алгоритмические стеммеры работают на основе файлов данных, которые содержат списки аффиксов и флексий. В процессе анализа программа выполняет сравнение суффиксов и окончаний слов входного текста со списком из файла, анализ происходит посимвольно, начиная с конца слова. Такие стеммеры обеспечивают большую полноту поиска, хотя и допускают допуская больше ошибок, которые проявляются в недостаточном или избыточном стеммировании. Избыточное стеммирование проявляется, если по одной основе отождествляются слова с разной семантикой; при недостаточном стеммировании по одной основе не отождествляются слова с одинаковой семантикой.
В русском языке преобладает словоформирование на основе аффиксов, сочетающих сразу несколько грамматических значений. Например, добрый
— окончание ый
указывает одновременно на единственное число, мужской род и именительный падеж, поэтому данный язык способствует использованию алгоритмов стемминга. Однако в силу сложной морфологической изменяемости слов для минимизации ошибок следует использовать дополнительные средства [15], например, лемматизацию. Ниже рассмотрены наиболее популярные реализации стеммеров, основывающиеся на различных принципах и допускающие обработку несуществующих слов для русского языка.
Основная идея стеммера Портера заключается в том, что существует ограниченное количество словообразующих суффиксов, и стемминг слова происходит без использования каких-либо баз основ: только множество существующих суффиксов и правила, заданные вручную. Алгоритм состоит из пяти шагов, на каждом из которых отсекается словообразующий суффикс и оставшаяся часть проверяется на соответствие правилам [16]. Например, для русских слов основа должна содержать не менее одной гласной. Если полученное слово удовлетворяет правилам, происходит переход на следующий шаг, иначе — алгоритм выбирает другой суффикс для отсечения. На первом шаге отсекается максимальный формообразующий суффикс, на втором — буква и
, на третьем — словообразующий суффикс, на четвертом — суффиксы превосходных форм, ь
и одна из двух н
. Недостатком является то, что часто обрезается больше необходимого, что затрудняет получение правильной основы слова. Например кровать-крова
при этом реально неизменяемая часть — кроват
, но стеммер выбирает для удаления наиболее длинную морфему [17].
Алгоритм Stemka основан на вероятностной модели: слова из обучающего текста разбираются анализатором на пары последние две буквы основы
+ суффикс
. При этом, если такая пара уже есть в модели – её вес увеличивается. Полученный массив данных ранжируется по убыванию веса и маловероятные модели отсекаются. Результат — набор потенциальных окончаний с условиями на предшествующие символы — инвертируется для удобства сканирования словоформ справа налево
и представляется в виде таблицы переходов конечного автомата [18].
Алгоритм MyStem является собственностью компании Яндекс. На первом шаге при помощи дерева суффиксов во входном слове определяются возможные границы между основой и суффиксом, после чего для каждой потенциальной основы начиная с самой длинной бинарным поиском по дереву основ проверяется её наличие в словаре либо нахождение наиболее близких к ней основ мерой близости является длина общего хвоста
. Если слово словарное — алгоритм заканчивает работу, иначе — переходит к следующему разбиению [19].
4.2 Представление документа в векторно-пространственной модели
Предположим, что каждый документ можно охарактеризовать определенным набором слов и частотой их появления. Тогда при условии, что если в документе конкретный набор слов употребляется с определенными частотами, то этот документ отвечает требованиям этого запроса. На основании этой информации строится таблица «слово-документ», где строки соответствуют терминам, а столбцы – исследуемым документам. В каждой ячейке может храниться булево значение, которое показывает наличие хотя бы одного вхождения термина в документ, частота слова в документе или вес термина [20, с. 143]. Теперь, для того чтобы сравнить документ d и запрос q, нужно определить меру схожести двух столбцов таблицы.
В рамках этой модели каждому терму ti документе dj соответствует некоторый неотрицательный вес wj. Каждому запросу q, который представляет собой множество термов, не соединенных между собой никакими логическими операторами, также соответствует вектор весовых значений wi j.
При этом вес отдельных термов можно вычислять разными способами. Один из возможных простейших подходов – использование нормализованной частоты появления терма в документе по следующей формуле:
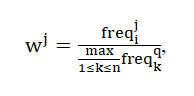
где freqij– число употребления терма в документе.
Такой показатель веса терма в документе обозначают аббревиатурой tfj (от английского term frequency – частота термина). Однако этот подход не учитывает, насколько часто рассматриваемый терм используется во всем массиве документов, иными словами - дискриминационную силу терма. Поэтому в случае, когда доступна статистика использования термов во всем документальном массиве, более эффективно правило вычисления веса с использованием следующей формулы:
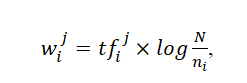
где ni – количество документов, в которых используется терм ti,
N - общее количество документов в массиве.
Следует отметить, что основание логарифма может быть любым, для простоты чаще всего используют 2 или 10. Приведенная выше формула многократно уточнялась с целью наиболее точного соответствия выдаваемых документов запросам пользователей. В 1988 году Солтоном был предложен такой вариант для вычисления веса терма ti из запроса в документе, представленный в следующей формуле [21, с.41]:
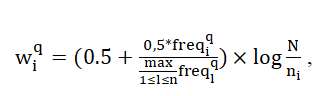
где freqiq – частота терма ti из запроса в тексте этого документа.
Использование такого показателя позволяет усилить отличие термина, если он встречается часто в небольшом количестве документов и уменьшить значение термина и релевантность документа, если термин встречается во многих документах или используется всего несколько раз.
Векторно-пространственная модель представления данных обеспечивает системам, построенным на ее основе, следующие возможности:
- обработку запросов без ограничений их длины;
- простоту реализации режима поиска подобных документов (каждый документ может рассматриваться как запрос);
- сохранение результатов поиска с возможностью выполнения уточняющего поиска;
- возможность установки дополнительных весовых коэффициентов для усовершенствования более узконаправленного поиска и анализа сходства документов [22].
Вместе с тем в векторно-пространственной модели не предусмотрено использование логических операций в запросах, что определенным образом ограничивает ее применимость.
4.3 Описание прототипа определения принадлежности документа к определенному жанру
На текущий момент реализован базовый алгоритм определения жанра текста, основанный на представленных выше подходах. Рассмотрим этапы работы программной модели анализатора документов (см. рис.1).

Рисунок 1 – Диаграмма состояний программной модели
(анимация: 5 кадров, 7 циклов повторения, 132 килобайта)
Для разработки прототипа системы и тестирования её работы, цель которой состоит в определении принадлежности документа к некоторому литературному жанру, были выбраны 2 жанра – детектив и любовный роман, подобрано по 5 книг каждого жанра. По нажатию на кнопку в систему загружается 6 файлов – первый файл является запросом, ещё 5 – предварительно отобранные файлы одного жанра.
Программный модуль, отвечающий за лексический анализ, запускается в первую очередь и готовит данные для последующих этапов анализа. Основная задача лексического анализа - распознать лексические единицы текста, удалить стоп-слова и привести их к единому представлению с помощью стемминга. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Наборы стоп-слов могут быть разными и зависеть от целей и задач исследования. В данном случае используется список стоп-слов, состоящий из частиц, предлогов и некоторых местоимений. По результатам собственных исследований, удаление стоп-слов отсекает в среднем 30% слов (см. рис.2), что ускоряет дальнейшую обработку данных и повышает точность результатов.
Для определения жанровой принадлежности текста в реализовываемом прототипе программной системы был разработан анализатор близости загружаемого документа к документам, жанровая принадлежность которых уже определена. С этой целью была использована векторно–пространственная модель, как наиболее подходящая для решения поставленной задачи. Для определения близости документов были использованы 4 наиболее популярных показателя:
- скалярное произведение векторов;
- евклидово расстояние;
- манхэттенское расстояние;
- метод косинусной меры сходства.
Анализируя эти методы, следует обратить внимание, что значения схожести по евклидовому и манхэттенскому методам на самом деле являются расстояниями между векторами. Таким образом, чем расстояние меньше, тем более документ схож с запросом. Методы, использующие скалярное произведение и косинусные показатели, в результате возвращают именно сходство, то есть наилучший документ тот, который имеет наибольший показатель сходства. Весомым недостатком методов манхэттенского расстояния и евклидового расстояния является полный перебор векторов и вычисление расстояний даже для нулевых точек, что несет за собой увеличение требований к производительности.
Одна из причин популярности косинусного сходства состоит в том, что оно эффективно в качестве оценочной меры, особенно для разреженных векторов, так как необходимо учитывать только ненулевые измерения. На основании проделанных расчетов и анализа описанных методов, основанных на векторной модели, лучшим методом для определения близости документов был определен метод косинусного сходства (см. рис. 2).
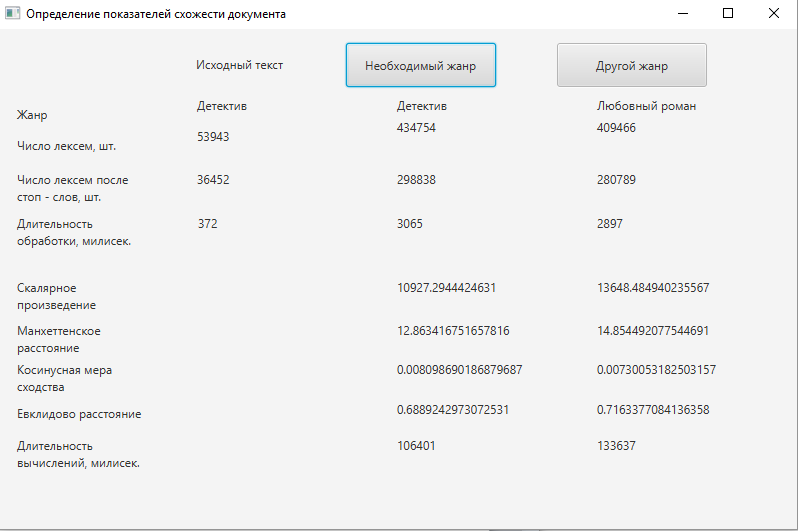
Рисунок 2 – Результаты работы программы
Так как показатели расстояний между запросом и документами численно меньше у выборки детективного жанра, а значения скалярного произведения и косинусной меры сходства наоборот, больше, можно сделать вывод, что исследуемый документ детективного жанра. Однако разительной разницы заметить не удастся – выбранная для дальнейшего исследования косинусная мера сходства в общем случае принадлежит промежутку [0, 1], т.е., чем ближе значение к единице, тем более вероятно, что жанр определен верно.
Следовательно, показатели в 0,0081 и 0,0073 являются недостаточно весомыми, чтобы с уверенностью классифицировать выбранный текст. Для того, чтобы считать документ принадлежащим к определенному жанру, следует максимально приблизить показатель косинусной меры к единице, следовательно, необходимо доработать систему [23].
На данном этапе разработки были выявлены следующие недостатки программной системы:
- высокая продолжительность первичной обработки текстов;
- низкие показатели схожести документов, релевантность которых определена на основе экспертных оценок;
- методы манхэттенского и евклидового расстояния требуют большей временной и вычислительной сложности;
- отсутствует возможность дообучения, то есть дополнения обучающей выборки документами, которые в результате программного анализа были определены как принадлежащие к выбранному жанру;
- требуется выполнять загрузку обучающей выборки каждый раз в начале работы программы.
В связи с этим следует исследовать следующие направления работы:
- доработать первичную обработку документов посредством удаления личных имен, названий населенных пунктов, других малозначащих конструкций;
- использовать распараллеливание в процессе обработки документов;
- использовать для определения схожести документов метод косинусного сходства;
- считать документом, принадлежащим к выбранному жанру такой, косинусная мера сходства которого будет более чем 0.7;
- разработать методологию сохранения результатов анализа для последующего обучения модели;
- увеличить число обучающей выборки минимум до 100 книг выбранного жанра;
- с помощью экспертов выполнить анализ весов часто употребляемых термов в документах определенного жанра, повысить степень их влияния на конечное вычисление схожести документов и в последствии – на определение жанра.
Выводы
Анализ источников показал, что тема анализа и обработки текстовой информации актуальная как в международном, национальном так и в локальном научных сообществах. Однако следует отметить, что исследования в автоматизации определения жанра документа недостаточно популярны либо являются внутренними наработками поисковых и других коммерческих систем и не находятся в открытом доступе.
В реферате описаны особенности стемминга как метода первичной обработки текста, рассмотрены рабочие стеммеры. Также были коротко описаны наработки и исследования в области анализа схожести документов, проведенные на текущий момент, изложены недостатки прототипа программной системы и направления дальнейшей работы.
Дальнейшая работа будет направлена на анализ весов часто употребляемых термов в документах определенного жанра, внедрение результатов в дипломную работу, а также на разработку приложения, реализующего анализатор принадлежности документа к определенному жанру, соответствующего выдвинутым выше требованиям.
Список источников
- Сторожук, Н. О. Анализ методов определения текстовой близости документов / Н. О. Сторожук, И. А. Коломойцева // Материалы студенческой секции IX Международной научно-технической конференции «Информатика, управляющие системы, математическое и компьютерное моделирование» (ИУСМКМ-2018). – Донецк: ДонНТУ, 2018. – С. 43-47.
- Salton G., Buckley C. Term-weighting approaches in automatic text retrieval. Information Processing & Management 1988./ Salton G., Buckley C. Vol. 24, No. 5, pp. 513-523 [Электронный ресурс]. Режим доступа: http://pmcnamee.net/744/papers/SaltonBuckley.pdf. – Загл. с экрана.
- Маннинг, К.Д., Рагхаван П., Шютце Х. Введение в информационный поиск / К. Д. Маннинг, П. Рагхаван, Х. Шютце. – Москва : М.: ООО «И.Д. Вильямс», 2011. – 528 с. [Электронный ресурс]. – Режим доступа: http://mirknig.su/knigi/web/163982-vvedenie-v-informacionnyy-poisk.html. – Загл. с экрана.
- Красников, И.А. Гибридный алгоритм классификации текстовых документов на основе анализа внутренней связности текста [Текст] / И. А. Красников, Н. Н. Никуличев [Электронный ресурс]. – Режим доступа: ivdon.ru/ru/magazine/archive/n3y2013/1773 . – Загл. с экрана.
- Харламов, А. А. Сравнительный анализ организации систем синтаксических парсеров [Текст] / А. А. Харламов, Т. В. Ермоленко, Г. В. Дорохина [Электронный ресурс]. – Режим доступа: ivdon.ru/ru/magazine/archive/n4y2013/2015. – Загл. с экрана.
- Яцко, В.А., Алгоритмы и программы автоматической обработки текста // Вестник иркутского государственного лингвистического университета: Том 1, номер 17. – Иркутск: Евразийский лингвистический институт в г. Иркутске, 2012. – 150-160 с.
- Шарнин, М. М., Ищенко, Н. С., Пахмутова Н.Ю., Сюракшина Ю.В. Использование методов тематического моделирования многоязычных коллекций для прогноза тревожных событий [Текст] / М. М. Шарнин, Н. С.Ищенко, Н.Ю. Пахмутова, Ю.В Сюракшина [Электронный ресурс]. – Режим доступа: http://www.academia.edu/36763506/Использование_методов_тематического_моделирования_в_мультиязыковых_средах_для_прогноза_тревожных_событий _Topic_modeling_methods_in_multi-language_environments_for_troubling_events_prediction. – Загл. с экрана.
- Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. Автоматическая обработка текстов на естественном языке и компьютерная лингвистика [Текст]/ Автоматическая обработка текстов на естественном языке и компьютерная лингвистика: учеб.пособие/Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. — М.: МИЭМ, 2011. — 272 с.
- Ягунова Е.В., Пивоварова Л.М. Экспериментально- вычислительные исследования художественной прозы Н.В. Гоголя [Текст]/ Е.В. Ягунова, Л.М. Пивоварова [Электронный ресурс]. – Режим доступа: http://webground.su/data/lit/pivovarova_yagunova/Experimentalno-vychislitelnyie_issledovaniya_prozy.pdf. – Загл. с экрана.
- Ягунова Е.В. Ключевые слова в исследовании текстов Н.В. Гоголя [Текст]/ Е.В. Ягунова [Электронный ресурс]. – Режим доступа: http://webground.su/data/lit/yagunova/Kliuchevyie_slova_v_issledovanii_textov_N_V_Gogolya.pdf. – Загл. с экрана.
- Леонов А.Д. Методы автоматизированной коррекции специализированных естественно-языковых текстов [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2014/fknt/leonov/diss/index.html. – Загл. с экрана.
- Стуликова Н.В. Разработка и исследование алгоритма автоматического реферирования текстов на основе нечеткой логики [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2014/fknt/stulikova/diss/index.htm. – Загл. с экрана.
- Сторожук, Н. О., Коломойцева И.А. Анализ алгоритмов лексической и морфологической обработки текстов c целью определения жанровой принадлежности / Н. О. Сторожук, И. А. Коломойцева // Материалы V Международной научно-технической конференции «Современные информационные технологии в образовании и научных исследованиях» (СИТОНИ-2017). – Донецк: ДонНТУ, 2017. – С. 191-195.
- Стемминг [Электронный ресурс]. – Режим доступа: https://intellect.ml/stemming-stemmer-portera-6235. – Загл. с экрана.
- Алгоритмы интеллектуальной обработки больших объемов данных [Электронный ресурс]. – Режим доступа: http://www.intuit.ru/studies/courses/3498/740/info . – Загл. с экрана.
- Стеммер Портера для русского языка [Электронный ресурс]. – Режим доступа: https://medium.com/@eigenein/ . – Загл. с экрана.
- Стеммер Портера для русского языка [Электронный ресурс]. – Режим доступа: http://www.algorithmist.ru/2010/12/porter-stemmer-russian.html. – Загл. с экрана.
- Стемминг текстов на естественном языке [Электронный ресурс]. – Режим доступа: http://r.psylab.info/blog/2015/05/26/text-stemming/. – Загл. с экрана.
- Segalovich I., A fast morphological algorithm with unknown word guessing induced by a dictionary for a web search engine [Электронный ресурс] // Yandex-Team – Режим доступа: http://cache-mskdataline03.cdn.yandex.net/download.yandex.ru/company/iseg-las-vegas.pdf. – Загл. с экрана.
- Маннинг, К.Д. Введение в информационный поиск / К. Д. Маннинг, П. Рагхаван, Х. Шютце. – Москва : М.: ООО «И.Д. Вильямс», 2011. – 528 с.
- Salton G., Fox E., Wu H. Extended Boolean information retrieval. Communications of the ACM. 2001./ G.Salton, E,Fox, H.Wu.- Vol. 26. № 4. P. 35–43.
- Компьютерный анализ текста [Электронный ресурс]. – Режим доступа: http://lab314.brsu.by/kmp-lite/CL/CL-Lect/KAT.htm. – Загл. с экрана.
- Сторожук, Н. О., Коломойцева И.А. Реализация прототипа анализатора жанровой принадлежности произведений на основании векторно – пространственной модели представления документов / Н. О. Сторожук, И. А. Коломойцева // Материалы международной научно-практическаой конференции «Программная инженерия: методы и технологии разработки информационновычислительных систем» (ПИИВС-2018) – Донецк: ДонНТУ, 2018. – С. 132-137.