
Abstract
Summary of the final work
Content
- Introduction
- 1. Overview of personalization tools
- 2. Description of Recommended Algorithms
- 2.1 Classification of clustering algorithms
- 2.2 Description of the operation of clustering algorithms 8
- 2.3 Comparison of clustering algorithms
- Conclusion
- List of sources
Introduction
The global network now contains a wealth of information and knowledge. Users under various conditions can view various documents, audio and video files. However, this diversity of data hides problems that can arise both in the analysis and in the search for the necessary information on the Internet.
This means that people need to navigate among the extremely large number of available alternatives when they want to find something. For example, from choosing a new mobile phone or player to searching for a movie for an evening viewing. On the other hand, the owners of online shops and services are speaking: they are interested in personal advertising and recommendations for each specific user, because such an approach can significantly increase the profits of companies. As a result, in recent years, interest in the development and improvement of existing recommender systems has grown significantly.
1. Overview of personalization tools
Many companies today offer personalization services. Consider a brief description of the tools available today, which are focused on convenient integration with the website and do not require qualified programming.
Last.fm and Pandora — recommend music. They adhere to different strategies of recommendation: Last.fm uses, besides the ratings of other users, exclusively “external” data about the music - the author, style, date, tags, etc., and Pandora is based on the “content” of the musical composition, using very much MusicGenomeProject interesting idea, in which professional musicians analyze the composition of several hundred attributes [1-2] . Now Pandora is not available in Russia.
Google, Yahoo !, Yandex — we can say that they also recommend sites to users. Search engines are trying to predict how relevant this document is to this request, and recommender systems are trying to predict what rating this user will put on this product. Leading search engines have lots of side projects based on recommender systems - for example, Yahoo! Music.
Personyze service is designed to segment visitors to the site in real time, as well as to provide them with personalized and optimized content based on their demographic, behavioral and historical characteristics. Personyze offers the most advanced SaaS platform in the market of website customization and user segmentation in real time. Immediately after adding the code, you can see in real time reports on user behavior on the site. All visitors are automatically distributed into segments according to their location, source of visits (including specific key requests), demographic data, site activity, etc. - only about 50 metrics. Once the match between the visitor and the segment has been established, Personyze performs the necessary personalizing actions, allowing you to change any piece of site content, be it adding a banner, changing the picture, changing the text, adding the recommended products and much more. The visitor will see the site version optimized for it. The service is convenient in that it allows you to work with individual segments and provide detailed reports on each of them.
The creators of Monoloop are focused on controlling the buying cycle. Installed on the site, their service monitors the behavior of each site visitor, recognizes him at the time of the next visit, and accordingly changes certain elements of the site for him. Monoloop automatically creates a profile for each new client and allows you to build a coherent and consistent campaign to work with him. Service remembers what exactly interests the buyer, and can offer other suitable products from similar categories. Plus, he understands at what stage the purchase decision is a buyer, and advises what can be done to push the buyer to purchase.
Gravity startup generation Web 3.0 - is the version of the web, implying personalization of the Internet for each user. He positions himself as a service offering a unique personalized experience that helps users find the most interesting content based on their individual needs. At the initial stage, the service was focused on end users, but at present it focuses only on B2B (advertisers and publishers). Gravity's personalization is to apply various “real-time” filters to information available to users in search and social media. The patented Gravity technology creates Interest Graph based on the interests, preferences and habits of the user, and allows site owners to offer their readers editorial and advertising content that matches their interests.
Gravity startup generation Web 3.0 - is the version of the web, implying personalization of the Internet for each user. He positions himself as a service offering a unique personalized experience that helps users find the most interesting content based on their individual needs. At the initial stage, the service was focused on end users, but at present it focuses only on B2B (advertisers and publishers). Gravity's personalization is to apply various “real-time” filters to information available to users in search and social media. The patented Gravity technology creates Interest Graph based on the interests, preferences and habits of the user, and allows site owners to offer their readers editorial and advertising content that matches their interests.
2. Description of Recommended Algorithms

Figure 1 - The work of the collaborative filtering algorithm
2.1 Classification of clustering algorithms
We distinguish two main classifications of clustering algorithms[5].
- Hierarchical and flat. Hierarchical algorithms (also called taxonomy algorithms) do not build a single partitioning of the sample into disjoint clusters, but a system of nested partitions. Thus, at the output we get a cluster tree, the root of which is the entire sample, and the leaves are the smallest clusters. Planar algorithms build one partition of objects into clusters.
- Clear and fuzzy. Clear (or non-intersecting) algorithms for each sample object are assigned a cluster number, i.e. each object belongs to only one cluster. Fuzzy (or intersecting) algorithms for each object associate a set of real values, indicating the degree of the object's relation to the clusters. Those. each object belongs to each cluster with some probability.
In the case of using hierarchical algorithms, the question arises of how to unite clusters among themselves, how to calculate the “distances” between them.
Single relationship (nearest neighbor distances) In this method, the distance between two clusters is determined by the distance between the two closest objects (nearest neighbors) in different clusters. The resulting clusters tend to chain together.
Full communication (distance of the most distant neighbors) In this method, the distances between clusters are determined by the greatest distance between any two objects in different clusters (that is, the most distant neighbors). This method usually works very well when objects come from separate groups.
Unweighted pairwise mean. In this method, the distance between two different clusters is calculated as the average distance between all pairs of objects in them.
The method is effective when objects form different groups, but it works equally well in the case of extended (“chained” type) clusters. Weighted paired average The method is identical to the unweighted paired average method, except that the size of the corresponding clusters (i.e. the number of objects contained in them) is used as a weighting factor in the calculations.
Among the algorithms of hierarchical clustering, there are two main types: ascending and descending algorithms. Downstream algorithms operate on the top-down principle: first, all objects are placed in one cluster, which is then divided into smaller and smaller clusters. Ascending algorithms are more common, which at the beginning of the work place each object in a separate cluster, and then combine the clusters into ever larger ones.
Thus, a system of nested partitions is built. The results of such algorithms are usually presented as a tree.
2.2 Description of the operation of clustering algorithms
Fuzzy clustering. The most popular fuzzy clustering algorithm is the c – medium algorithm. It is a modification of the k – means method[6]. Algorithm steps:
- Select the initial fuzzy partition of n objects into k clusters by choosing the matrix of membership U of size nx k.
- Using the U matrix, find the value of the fuzzy error criterion using the formula
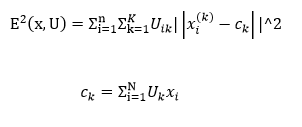
- Rearrange objects to reduce this value of the fuzzy error criterion.
- Return to p. 2 until the changes in the matrix U become insignificant.
This algorithm may not be suitable if the number of clusters is not known in advance, or it is necessary to unambiguously assign each object to one cluster.
The essence of the algorithms based on graphs is that the sample of objects is represented as a graph G = (V, E), the vertices of which correspond to objects, and the edges have a weight equal to the "distance" between objects. The advantages of graph clustering algorithms are visibility, relative ease of implementation, and the possibility of making various improvements based on geometrical considerations.
The main algorithms are the algorithm for selecting connected components, the algorithm for constructing the minimum covering (spanning) tree and the layer-by-layer clustering algorithm. Algorithm of selection of connected components In the algorithm of selection of connected components, the input parameter R is set and all edges for which “distances” are greater than R are deleted in the graph. Only the closest pairs of objects remain connected. The meaning of the algorithm is to find an R value that lies in the range of all “distances” at which the graph “collapses” into several connected components. The resulting components are clusters.
For the selection of the parameter R, a histogram of distributions of pairwise distances is usually constructed. In problems with a well-pronounced cluster data structure, there will be two peaks in the histogram — one corresponds to intracluster distances, and the second to intercluster distances. The parameter R is selected from the minimum zone between these peaks. At the same time, managing the number of clusters using the distance threshold is rather difficult.
The minimum spanning tree algorithm The minimum spanning tree algorithm first builds a minimum spanning tree on a graph, and then successively removes the edges with the highest weight.
By removing the link labeled CD, with a length of 6 units (edge with maximum distance), we get two clusters: {A, B, C} and {D, E, F, G, H, I}. The second cluster can be further divided into two more clusters by removing the edge EF, which has a length of 4.5 units. Layer Clustering The layer clustering algorithm is based on the separation of connected components. a graph at some level of distance between objects (vertices).
The distance level is set by the distance threshold c. For example, if the distance between objects is 0 <= p (x, x ') <= 1, then 0 <= c <= 1. The layer-by-layer clustering algorithm forms a sequence of subgraphs of the graph G, which reflect hierarchical relations between clusters: By changing the distance thresholds { c0, ..., cm}, where 0 = c0
2.3 Comparison of clustering algorithms
Algorithm clustering Computational complexity Hierarchical O (n2) k – medium O (nkl), where k is the number of clusters, l is the number of iterations c – means depends on the algorithm Selection of connected components depends on the algorithm Minimum spanning tree O (n2 log n) Layered clustering O (max (n, m)), where m
Analysis of tonality is usually defined as one of the tasks of computational linguistics, i.e. it is implied that we can find and classify tonality using natural language processing tools (such as teggers, parsers, etc.). Having made a great generalization, we can distinguish four approaches. A rule-based, dictionary based approach, machine learning with a teacher and machine learning without a teacher. Dictionary based approaches use so-called tonal dictionaries (affective lexicons) to analyze text. In its simplest form, a tonal dictionary is a list of words with a tonality value for each word.
To analyze the text, you can use the following algorithm: first, assign each word in the text to its value from the dictionary key (if it is present in the dictionary), and then calculate the overall tonality of the entire text. You can calculate the overall tonality in different ways. The simplest of them is the arithmetic average of all values.
The rule-based approach consists of a specially created set of rules, applying which the system makes a conclusion about the tonality of the text. For example, for the sentence “I love coffee,” you can apply the following rule: If the predicate (for example, “I love”) is included in the positive set of verbs (“I love”, “I love”, “I approve”, etc.) and in the sentence there are no negatives, then classify the tonality as “positive”.
Many commercial systems use this approach, despite the fact that it is costly, because For a good system operation, you need to make a large number of rules. Often, the rules are tied to a specific domain (for example, “restaurant theme”) and when you change the domain (“camera review”), you must re-create the rules. Nevertheless, this approach is the most accurate with a good rule base, but completely uninteresting for research.
Machine learning with a teacher is the most common method used in research. Its essence is to train the machine classifier on a collection of pre-marked texts, and then use the resulting model to analyze new documents. Machine learning without a teacher is probably the most interesting and at the same time the least accurate method for analyzing tonality. One example of this method may be automatic clustering of documents.
The process of creating a tonality analysis system is very similar to the process of creating other systems using machine learning: it is necessary to assemble a collection of documents for classifier training. Each document from the training collection must be represented as a feature vector. For each document, you must specify the "correct answer", i.e. type of tonality (for example, positive or negative), the classifier will select the classification algorithm and classifier training using these answers. The number of classes into which the tonality is divided is usually specified from the system specification.
Classification of tonality into more than two classes is a very difficult task. Even with three classes it is very difficult to achieve good accuracy regardless of the approach used. If there is a task of classification into more than two classes, then the following options are available for classifier training
Regression - you need to train the classifier to obtain a numerical value of tonality, for example, from 1 to 10, where a larger value means more positive tonality. Usually hierarchical classification gives better results than flat, because For each classifier, you can find a set of attributes that allows you to improve the results. However, it requires a lot of time and effort for training and testing. Regression can show better results if there are really many classes.
The most common way to present a document in computational linguistics and search tasks is either in the form of a set of words (bag-of-words) or in the form of a set of N-grams. For example, the sentence “I love black coffee” can be represented as a set of unigrams (I, love, black, coffee) or bigrams (I love, I love black, black coffee). Usually unigrams and bigrams give better results than N-grams of higher orders (trigrams and higher), because In most cases, the sample of training is not large enough to calculate higher-order N-grams. It always makes sense to test the results using unigrams, bigrams and their combinations. Depending on the type of data, unigrams may show better results than bigrams, and vice versa. Also, sometimes a combination of unigrams and bigrams improves results. Stemming and lemmatization.
Another way of presenting text is symbolic N-grams. The text “I love black coffee” can be represented as the following 4-character N-grams: “I love”, “love”, “I love”, “blue”, etc. Despite the fact that this method may seem too primitive, because at first glance, the character set does not carry any semantics; nevertheless, this method sometimes gives even better results than N-grams of words. N-grams of symbols correspond in some measure to the morphemes of words, and in particular the root of the word (“love”) bears in itself its meaning. Character N-grams can be useful in cases when there are spelling errors in the text - the character set of the text with errors and the character set of the text without errors will be almost the same as in words.
For languages with a rich morphology (for example, for Russian) - the same words can be found in texts, but in different variations (different gender or number), but the root of the words does not change, and, consequently, the common set of characters. Symbolic N-grams are used much less frequently than N-grams of words, but sometimes they can improve results. You can also use additional features such as: parts of speech, punctuation (smiles, exclamation marks in the text), negative signs in the text (“not”, “no”, “never”), interjections, etc. The next step in the compilation of the feature vector is the assignment of a weight to each feature. For some classifiers, this is optional, for example, for a Bayesian classifier, since he himself calculates the probability for signs. But if the support vector method is used, setting the weights can significantly improve the results.
Conclusion
In the course of work, the work of recommender systems algorithms was investigated, popular algorithms their classification, their basic structure were analyzed.
Clustering algorithms have been studied. Algorithms of fuzzy clustering are considered, and various algorithms based on graphs are also studied. The approaches of working with natural languages, word processing and the process of working with tonality are considered. Were considered modern algorithms used in recommender systems, as well as tools and programs necessary for their work.
The main data necessary for the work of the recommendation system are considered, such as a measure of distances using the example of text tonality analysis. The database provides information for the operation of algorithms. Principles of regression, flat classification and feature selection are studied. Variants of finding and determining opinions in the text and determining their properties were studied. Considered the importance of selecting the object of review when considering comments.
References
- Music Genome Project – Википедия [Электронный ресурс]. – Режим доступа: https://en.wikipedia.org/wiki/Music_Genome_Project
- Pandora (Радио) – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Pandora_(радио)
- Netflix Prize – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Netflix_Prize
- Граф интересов – Википедия [Электронный ресурс]. – Режим доступа:https://ru.wikipedia.org/wiki/Граф_интересов
- Рекомендательная система - Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Рекомендательная_система
- Коллаборативная фильтрация – Википедия [Электронный ресурс]. – https://ru.wikipedia.org/wiki/Коллаборативная_фильтрация
- Выбор языка и средства разработки – Мегаобучалка [Электронный ресурс]. – Режим доступа: http://megaobuchalka.ru/9/25993.html
- Минский М. Вычисления и автоматы / М. Минский. – М.: Мир, 1971. – 364 с.
- Рихтер, Д. CLR via C#. Программирование на платформе Microsoft .NET Framework 2.0 на языке C# / Д. Рихтер, – СПб. : Питер, 2007. – 656c.
- Ito M. Algebraic theory of automata and languages / M. Ito. – World Scientific Publishing, 2004. – 199 pp.
- Нейгел, К. C# 2005 для профессионалов / К. Нейгел – К. : Вильямс, 2006. – 763 c.
- Сравнительная характеристика, назначение и возможности современных языков – Студопедия [Электронный ресурс]. – Режим доступа: http://studopedia.ru/18_43813_sravnitelnaya-harakteristika-naznachenie-i-vozmozhnosti-sovremennih-yazikov.html
- Грофф Р.Д. SQL: полное руководство / Р.Д. Грофф, Н.П. Вайнберг, Д.Э. Оппель – СПб. : Вильямс, 2014. – 961 с.
- Труб, И. Объектно – ориентированное моделирование на С++: Учебный курс/ И. И. Труб. – СПб.: Питер, 2006. – 411 с.
- Объектно-ориентированный анализ и проектирование c примерами приложений / [Гради Буч и др]. [3-е изд.] – М.: Вильямс, 2008. – 720с.
- Грушвицкий Р.И. Проектирование систем на микросхемах программируемой логики / Р.И. Грушвицкий, А.Х. Мурсаев, Е.П. Угрюмов. – СПб.: БХВ-Петербург, 2002. – 608 с.
- Amaral J. Designing genetic algorithms for the state assignment problem / J. Amaral, K. Turner, J. Chosh // IEEE Transactions on Systems, Man, and Cybernetics. – 1995. – vol. 25. – pp. 659-694.
- Pandora (Радио) – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Pandora_(радио)