
Реферат по темі випускної роботи
Зміст
- Введення
- 1. Огляд інструментів персоналізації
- 2. Опис роботи рекомендаційних алгоритмів
- 2.1 Класифікація алгоритмів кластеризації
- 2.2 Опис роботи алгоритмів кластеризації 8
- 2.3 Порівняння алгоритмів кластеризації
- Висновок
- Список джерел
Введення
Всемирная сеть зараз містить величезну кількість інформації, знань. Користувачі на різних умовах можуть переглядати різноманітні документи, аудіо та відеофайли. Однак це різноманіття даних приховує в собі проблеми, які можуть виникнути як при аналізі, так і при пошуку необхідної інформації в мережі Інтернет.
Це означає, що люди повинні орієнтуватися серед надзвичайно великої кількості доступних альтернатив, коли хочуть щось знайти. Наприклад, від вибору нового мобільного телефону або плеєра до пошуку кінофільму для вечірнього перегляду. З іншого боку, виступають власники інтернет-магазинів і сервісів: вони зацікавлені в персональній рекламі і рекомендаціях кожному конкретному користувачеві, тому що такий підхід може істотно збільшити прибуток компаній. Як результат, в останні роки інтерес до розробки та вдосконалення існуючих рекомендаційних систем значно виріс.
1. Огляд інструментів персоналізації
Багато компаній пропонують сьогодні послуги з персоналізації. Розглянемо коротку характеристику доступних сьогодні інструментів, які орієнтовані на зручну інтеграцію з веб-сайтом і не вимагають кваліфікованого програмування.
Last.fm і Pandora — рекомендують музику. Вони дотримуються різних стратегій рекомендації: Last.fm використовує, крім власне рейтингів інших користувачів, виключно «зовнішні» дані про музику - автор, стиль, дата, теги і т.п., а Pandora грунтується на «утриманні» музичної композиції, використовуючи дуже цікаву ідею MusicGenomeProject, в якому професійні музиканти аналізують композицію декількома сотнями атрибутів [1-2] . Зараз Pandora недоступна в Росії.
Google, Yahoo !, Яндекс — можна сказати, що вони теж рекомендують користувачам сайти. Пошуковики намагаються передбачити, наскільки даний документ релевантний даному запиту, а рекомендаційні системи - намагаються передбачити, який рейтинг даний користувач поставить даному продукту. У провідних пошукових систем є маса побічних проектів, заснованих на рекомендаційних системах - наприклад, Yahoo! Music.
Сервіс Personyze створений для сегментування відвідувачів сайту в режимі реального часу, а також для надання їм персоналізованого і оптимізованого контенту, заснованого на їх демографічних, поведінкових і історичних характеристиках. Personyze пропонує саму розширену SaaS платформу на ринку персоналізації сайтів і сегментації користувачів в режимі реального часу. Відразу після додавання коду можна в реальному часі бачити звіти про поведінку користувачів на сайті. Всі відвідувачі автоматично розподіляються за сегментами відповідно до їх розташування, джерелом відвідувань (включаючи конкретні ключові запити), демографічними даними, діями на сайті і т.д. - всього близько 50 метрик. Як тільки встановлено відповідність відвідувача і сегмента, Personyze виконує необхідні персоналізують дії, що дозволяють вам змінювати будь-який фрагмент контенту сайту, будь то додавання банера, зміна картинки, зміна тексту, додавання рекомендованих продуктів і багато іншого. Відвідувач буде бачити оптимізовану під нього версію сайту. Сервіс зручний тим, що дозволяє працювати з окремими сегментами та надавати деталізовані звіти по кожному з них.
Творці Monoloop - сконцентровані на контролі за купівельним циклом. Встановлений на сайт, їх сервіс відстежує поведінку кожного відвідувача сайту, дізнається його в момент наступного відвідування і відповідно до цього змінює під нього певні елементи сайту. Monoloop автоматично створює профіль для кожного нового клієнта і дозволяє вибудовувати виразну і послідовну кампанію по роботі з ним. Сервіс запам'ятовує, що саме цікавить покупця, і може запропонувати інші відповідні товари з схожих категорій. Плюс він розуміє, на якому етапі ухвалення рішення про покупку знаходиться покупець, і радить, що можна зробити, щоб підштовхнути покупця до покупки.
Gravity стартап покоління Web 3.0 - це версія веба, що передбачає персоналізацію інтернету для кожного користувача. Він позиціонує себе як сервіс, що пропонує унікальний персоналізований досвід, який допомагає користувачам знаходити найцікавіший контент на основі їх індивідуальних потреб. На початковому етапі сервіс був орієнтований на кінцевих споживачів, але в даний час зосереджений тільки на B2B (рекламодавці та видавці). Персоналізація Gravity полягає в застосуванні різних фільтрів в режимі «реального часу» до інформації, доступної користувачам в пошуку і соціальних медіа. Запатентована Gravity технологія створює Interest Graph на базі інтересів, уподобань і звичок користувача, і дозволяє власникам сайтів запропонувати своїм читачам редакторський і рекламний контент, відповідний їх інтересам.
2. Опис роботи рекомендаційних алгоритмів

Рисунок 1 - Робота алгоритму коллаборатівной фільтрації
2.1 Класифікація алгоритмів кластеризації
Виділимо дві основні класифікації алгоритмів кластеризації[5].
- Ієрархічні і плоскі. Ієрархічні алгоритми (також звані алгоритмами таксономії) будують не одне розбиття вибірки на непересічні кластери, а систему вкладених розбиття. Таким чином, на виході ми отримуємо дерево кластерів, коренем якого є вся вибірка, а листям - найбільш дрібні кластера. Плоскі алгоритми будують одне розбиття об'єктів на кластери.
- Чіткі і нечіткі. Чіткі (або непересічні) алгоритми кожному об'єкту вибірки ставлять у відповідність номер кластера, тобто кожен об'єкт належить тільки одному кластеру. Нечіткі (або пересічні) алгоритми кожному об'єкту ставлять у відповідність набір речових значень, що показують ступінь відносини об'єкта до кластерів. Тобто кожен об'єкт відноситься до кожного кластеру з певною ймовірністю.
У разі використання ієрархічних алгоритмів постає питання, як об'єднувати між собою кластера, як обчислювати «відстані» між ними.
Одиночна зв'язок (відстані найближчого сусіда) У цьому методі відстань між двома кластерами визначається відстанню між двома найбільш близькими об'єктами (найближчими сусідами) в різних кластерах. Результуючі кластери мають тенденцію об'єднуватися в ланцюжки.
Повна зв'язок (відстань найбільш віддалених сусідів) У цьому методі відстані між кластерами визначаються найбільшою відстанню між будь-якими двома об'єктами в різних кластерах (тобто найбільш віддаленими сусідами). Цей метод зазвичай працює дуже добре, коли об'єкти походять з окремих груп.
Незважене попарне середнє. У цьому методі відстань між двома різними кластерами обчислюється як середня відстань між усіма парами об'єктів в них.
Метод ефективний, коли об'єкти формують різні групи, проте він працює однаково добре і в випадках протяжних ( «цепочечного» типу) кластерів. Виважена попарне середнє Метод ідентичний методу невиваженого попарного середнього, за винятком того, що при обчисленнях розмір відповідних кластерів (тобто число об'єктів, що містяться в них) використовується в якості вагового коефіцієнта.
Серед алгоритмів ієрархічної кластеризації виділяються два основних типи: висхідні і низхідні алгоритми. Спадні алгоритми працюють за принципом «зверху-вниз»: спочатку всі об'єкти поміщаються в один кластер, який потім розбивається на всі більш дрібні кластери. Більш поширені висхідні алгоритми, які на початку роботи поміщають кожен об'єкт в окремий кластер, а потім об'єднують кластери в усі більші.
Таким чином, будується система вкладених розбиття. Результати таких алгоритмів зазвичай представляють у вигляді дерева.
2.2 Опис роботи алгоритмів кластеризації
Нечітка кластеризація. Найбільш популярним алгоритмом нечіткої кластеризації є алгоритм c-середніх. Він являє собою модифікацію методу k-середніх[6]. Кроки роботи алгоритму:
- Вибрати початкове нечітке розбиття n об'єктів на k кластерів шляхом вибору матриці приналежності U розміру nx k.
- Використовуючи матрицю U, знайти значення критерію нечіткої помилки по формулі
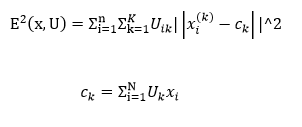
- перегрупуватися об'єкти з метою зменшення цього значення критерію нечіткої помилки.
- Повертатися в п. 2 до тих пір, поки зміни матриці U не стануть незначними
Цей алгоритм може не підійти, якщо заздалегідь невідомо число кластерів, або необхідно однозначно віднести кожен об'єкт до одного кластеру.
Суть алгоритмів, заснованих на графах, полягає в тому, що вибірка об'єктів представляється у вигляді графа G = (V, E), вершинам якого відповідають об'єкти, а ребра мають вагу, рівний «відстані» між об'єктами. Перевагою графових алгоритмів кластеризації є наочність, відносна простота реалізації і можливість внесення різних удосконалень, засновані на геометричних міркуваннях.
Основними алгоритмами є алгоритм виділення зв'язкових компонент, алгоритм побудови мінімального покриває (остовного) дерева і алгоритм пошаровим кластеризації. Алгоритм виділення зв'язкових компонент В алгоритмі виділення зв'язкових компонент задається вхідний параметр R і в графі видаляються всі ребра, для яких «відстані» більше R. Сполученими залишаються тільки найбільш близькі пари об'єктів. Сенс алгоритму полягає в тому, щоб підібрати таке значення R, що лежить в діапазон всіх «відстаней», при якому граф «розвалиться» на кілька зв'язкових компонент. Отримані компоненти і є кластери.
Для підбору параметра R зазвичай будується гістограма розподілів попарних відстаней. У завданнях з добре вираженою кластерної структурою даних на гістограмі буде два піки - один відповідає внутрікластерним відстаням, другий - межкластерним відстані. Параметр R підбирається із зони мінімуму між цими піками. При цьому управляти кількістю кластерів за допомогою порога відстані досить важко.
Алгоритм мінімального покриває дерева Алгоритм мінімального покриває дерева спочатку будує на графі мінімальне покриває дерево, а потім послідовно видаляє ребра з найбільшою вагою.
Шляхом видалення зв'язку з позначкою CD, з довжиною рівною 6 одиницям (ребро з максимальною відстанню), отримуємо два кластери: {A, B, C} і {D, E, F, G, H, I}. Другий кластер в подальшому може бути розділений ще на два кластери шляхом видалення ребра EF, яке має довжину, рівну 4,5 одиницям. Пошарова кластеризация Алгоритм пошаровим кластеризації заснований на виділенні зв'язкових компонент графа на деякому рівні відстаней між об'єктами (вершинами).
Рівень відстані задається порогом відстані c. Наприклад, якщо відстань між об'єктами 0 <= p (x, x ') <= 1, то 0 <= c <= 1. Алгоритм пошаровим кластеризації формує послідовність подграфов графа G, які відображають ієрархічні зв'язки між кластерами: За допомогою зміни порогів відстані { с0, ..., сm}, де 0 = с0 <с1 <... <сm = 1, можливо контролювати глибину ієрархії одержуваних кластерів.
2.3 Порівняння алгоритмів кластеризації
Алгоритм кластеризації Обчислювальна складність Ієрархічний O (n2) k-середніх O (nkl), де k - число кластерів, l - число ітерацій c-середніх залежить від алгоритму Виділення зв'язкових компонент залежить від алгоритму Мінімальна покриває дерево O (n2 log n) Пошарова кластеризация O (max (n, m)), де m
Аналіз тональності зазвичай визначають як одну з задач комп'ютерної лінгвістики, тобто мається на увазі, що ми можемо знайти і класифікувати тональність, використовуючи інструменти обробки природної мови (такі як тегер, парсери і ін.). Зробивши велике узагальнення, можна виділити чотири підходи. Підхід, заснований на правилах, на словниках, машинне навчання з учителем і машинне навчання без учителя. Підходи, засновані на словниках, використовують так звані тональні словники (affective lexicons) для аналізу тексту. У простому вигляді тональний словник представляє з себе список слів зі значенням тональності для кожного слова.
Щоб проаналізувати текст, можна скористатися наступним алгоритмом: спочатку кожному слову в тексті привласнити його значенням тональності зі словника (якщо воно присутнє в словнику), а потім обчислити загальну тональність всього тексту. Обчислювати загальну тональність можна різними способами. Найпростіший з них - середнє арифметичне всіх значень.
Підхід, заснований на правилах, складається з спеціально створеного набору правил, застосовуючи які система робить висновок про тональності тексту. Наприклад, для пропозиції «Я люблю каву», можна застосувати наступне правило: Якщо присудок (наприклад, «люблю») входить в позитивний набір дієслів ( «люблю», «обожнюю», «схвалюю» і т.д.) і в реченні немає заперечень, то класифікувати тональність як «позитивна».
Багато комерційних системи використовують даний підхід, незважаючи на те що він вимагає великих витрат, тому що для хорошої роботи системи необхідно скласти велику кількість правил. Найчастіше правила прив'язані до певного домену (наприклад, «ресторанна тематика») і при зміні домену ( «огляд фотоапаратів») потрібно заново складати правила. Тим не менш, цей підхід є найбільш точним при наявності хорошої бази правил, але зовсім нецікавим для дослідження.
Машинне навчання з учителем є найбільш поширеним методом, використовуваним в дослідженнях. Його суть полягає тому, щоб навчити машинний класифікатор на колекції заздалегідь розмічених текстах, а потім використовувати отриману модель для аналізу нових документів. Машинне навчання без вчителя є, напевно, найбільш цікавий і в той же час найменш точний метод аналізу тональності. Одним із прикладів цього методу може бути автоматична кластеризація документів.
Процес створення системи аналізу тональності дуже схожий на процес створення інших систем із застосуванням машинного навчання: необхідно зібрати колекцію документів для навчання класифікатора. Кожен документ з навчальної колекції потрібно представити у вигляді вектора ознак для кожного документа потрібно вказати «правильну відповідь», тобто тип тональності (наприклад, позитивна чи негативна), за цими відповідями і буде навчатися класифікатор вибір алгоритму класифікації та навчання класифікатора використання отриманої моделі Кількість класів, на які ділять тональність, зазвичай задається з специфікації системи.
Класифікація тональності на більш ніж два класи - це дуже складне завдання. Навіть з трьома класами дуже складно досягти хорошої точності незалежно від застосовуваного підходу. Якщо стоїть завдання класифікації на більш ніж два класи, то тут можливі такі варіанти для навчання класифікатора
Регресія - потрібно навчити класифікатор для отримання чисельного значення тональності, наприклад від 1 до 10, де більше значення означає більш позитивну тональність. Зазвичай ієрархічна класифікація дає кращі результати, ніж плоска, тому що для кожного класифікатора можна знайти набір ознак, який дозволяє поліпшити результати. Однак він вимагає великих часу і зусиль для навчання і тестування. Регресія може показати кращі результати, якщо класів дійсно багато.
Найбільш поширений спосіб представлення документа в задачах комп'ютерної лінгвістики і пошуку - це або у вигляді набору слів (bag-of-words) або у вигляді набору N-грам. Так, наприклад, пропозиція «Я люблю чорну каву» можна представити у вигляді набору уніграмм (Я, люблю, чорний, кава) або биграмм (Я люблю, люблю чорний, чорна кава). Зазвичай уніграмми і біграми дають кращі результати ніж N-грами більш високих порядків (триграми і вище), тому що вибірка навчання в більшості випадків недостатня велика для підрахунку N-грам вищих порядків. Завжди має сенс протестувати результати із застосуванням уніграмм, биграмм і їх комбінації. Залежно від типу даних уніграмми можуть показати кращі результати ніж біграми, а можуть і навпаки. Також іноді комбінація уніграммов і биграмм дозволяє поліпшити результати. Стемінг і лематизації.
Інший спосіб представлення тексту - символьні N-грами. Текст «Я люблю чорну каву» можна представити у вигляді наступних 4-символьних N-грам: «я лю», «люб», «юблю», «блю», і т.д. Незважаючи на те, що такий спосіб може здатися занадто примітивним, тому що на перший погляд набір символів не несе в собі ніякої семантики, тим не менш, цей метод іноді дає результати навіть краще ніж N-грами слів. N-грами символів відповідають в якійсь мірі морфемам слів, а зокрема корінь слова ( «люб») несе в собі його зміст. Символьні N-грами можуть бути корисні у випадках при наявності орфографічних помилок в тексті - набір символів у тексту з помилками і набір символів у тексту без помилок буде практично однаковий на відміну від слів.
Для мов з багатою морфологією (наприклад, для російського) - в текстах можуть зустрічатися однакові слова, але в різних варіаціях (різні рід або число), але при цьому корінь слів не змінюється, а, отже, і загальний набір символів. Символьні N-грами застосовуються набагато рідше, ніж N-грами слів, але іноді вони можуть поліпшити результати. Також можна використовувати додаткові ознаки, такі як: частини мови, пунктуація (наявність в тексті смайлів, знаків оклику), наявність в тексті заперечень ( «не», «ні», «ніколи»), вигуків і т.д. Наступним кроком в складанні вектора ознак є присвоювання кожному ознакою його вага. Для деяких класифікаторів це є необов'язковим, наприклад, для байєсівського класифікатора, тому що він сам вираховує ймовірність для ознак. Але якщо використовується метод опорних векторів, то завдання вагів може помітно поліпшити результати.
Висновок
В ході роботи, була досліджена робота алгоритмів рекомендаційних систем, були проаналізовані популярні алгоритми їх класифікація, їх базова структура.
Були вивчені алгоритми кластеризації. Розглянуто алгоритми нечіткої кластеризації, а також вивчені різні алгоритми, засновані на графах. Розглянуто підходи роботи з натуральними мовами, обробки тексту і процесу роботи з тональністю. Були розглянуті сучасні алгоритми використовуються в рекомендаційних системах, а також допоміжні засоби і програми, необхідні для їх роботи.
Розглянуто основні дані, необхідні для роботи рекомендаційної системи, такі як міра відстаней на прикладі аналізу тональності тексту. Вивчено бази даних надають інформацію для роботи алгоритмів. Вивчено принципи регресії, плоскою класифікації і вибору ознак. Були вивчені варіанти знаходження і визначення думок в тексті і визначення їх властивостей. Розглянуто важливість виділення об'єкта рецензії при розгляді коментарів.
Перелік посилань
- Music Genome Project – Википедия [Электронный ресурс]. – Режим доступа: https://en.wikipedia.org/wiki/Music_Genome_Project
- Pandora (Радио) – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Pandora_(радио)
- Netflix Prize – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Netflix_Prize
- Граф интересов – Википедия [Электронный ресурс]. – Режим доступа:https://ru.wikipedia.org/wiki/Граф_интересов
- Рекомендательная система - Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Рекомендательная_система
- Коллаборативная фильтрация – Википедия [Электронный ресурс]. – https://ru.wikipedia.org/wiki/Коллаборативная_фильтрация
- Выбор языка и средства разработки – Мегаобучалка [Электронный ресурс]. – Режим доступа: http://megaobuchalka.ru/9/25993.html
- Минский М. Вычисления и автоматы / М. Минский. – М.: Мир, 1971. – 364 с.
- Рихтер, Д. CLR via C#. Программирование на платформе Microsoft .NET Framework 2.0 на языке C# / Д. Рихтер, – СПб. : Питер, 2007. – 656c.
- Ito M. Algebraic theory of automata and languages / M. Ito. – World Scientific Publishing, 2004. – 199 pp.
- Нейгел, К. C# 2005 для профессионалов / К. Нейгел – К. : Вильямс, 2006. – 763 c.
- Сравнительная характеристика, назначение и возможности современных языков – Студопедия [Электронный ресурс]. – Режим доступа: http://studopedia.ru/18_43813_sravnitelnaya-harakteristika-naznachenie-i-vozmozhnosti-sovremennih-yazikov.html
- Грофф Р.Д. SQL: полное руководство / Р.Д. Грофф, Н.П. Вайнберг, Д.Э. Оппель – СПб. : Вильямс, 2014. – 961 с.
- Труб, И. Объектно – ориентированное моделирование на С++: Учебный курс/ И. И. Труб. – СПб.: Питер, 2006. – 411 с.
- Объектно-ориентированный анализ и проектирование c примерами приложений / [Гради Буч и др]. [3-е изд.] – М.: Вильямс, 2008. – 720с.
- Грушвицкий Р.И. Проектирование систем на микросхемах программируемой логики / Р.И. Грушвицкий, А.Х. Мурсаев, Е.П. Угрюмов. – СПб.: БХВ-Петербург, 2002. – 608 с.
- Amaral J. Designing genetic algorithms for the state assignment problem / J. Amaral, K. Turner, J. Chosh // IEEE Transactions on Systems, Man, and Cybernetics. – 1995. – vol. 25. – pp. 659-694.
- Pandora (Радио) – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Pandora_(радио)