Аппроксимация методом наименьших квадратов плюс модель разложения Фурье
Для нашей первой модели мы использовали линейную аппроксимацию методом наименьших квадратов (LSA) и ряд Фурье третьего порядка, однако, если количество дней, полученных из автокорреляции, составляет 50 или меньше, мы использовали ряд Фурье второго порядка. Есть две версии этой модели. Первая версия работает с необработанными данными о ценах закрытия и пытается приблизительно определить будущую цену. Вторая версия использует скользящие средние для сглаживания необработанных данных о ценах, а затем работает с новыми данными, чтобы попытаться спрогнозировать цену акций. Таким образом, мы назвали первую версию несглаженной, а вторую – сглаженной. Шаги составляют:
- После выбора акции мы посмотрели на цены закрытия и построили простые графики исходных данных.
- На следующем этапе мы решили построить график автокорреляции данных о ценах закрытия. Это дало нам диапазон дат для соответствующих данных. Эти соответствующие данные будут использоваться в инструментах аппроксимации. Этот метод коррелирует ценовые данные с самими собой в обратном времени. Таким образом, 0 – это последний день предоставленных данных о ценах (12 сентября), а 50 (например) – значение автокорреляции для цены пятьдесят дней назад. Если автокорреляция положительная, над осью x, это означает, что данные о ценах для этого временного диапазона актуальны. Мы принимаем во внимание только начальную область до того, как график автокорреляции погрузится под ось x и впервые станет отрицательным. Любой последующий случай положительной автокорреляции рассматривается как шум и не учитывается.
- Мы используем линейный LSA, используя количество соответствующих дней, полученных в предыдущем методе, и строим его график на соответствующих данных. Мы не использовали квадратичный, кубический или метод наименьших квадратов более высокого порядка. Даже при том, что LSA более высокого порядка может точно соответствовать данным цены закрытия, в будущем она будет значительно отличаться от фактической цены. Очень сложно удерживать высокую степень числа под контролем и в области приближения. Но одно только линейное приближение наименьших квадратов все еще имеет проблемы с представлением фактических данных.
- Чтобы найти хорошее приближение для данных, расходящихся с линейным LSA, мы теперь вычтем и построим линейные данные аппроксимации методом наименьших квадратов из фактических данных о ценах закрытия, чтобы получить разницу в цене. Разница в цене будет использована в будущих расчетах для получения ряда Фурье и шума.
- Используя данные разницы, мы создаем ряд Фурье второго, третьего или четвертого порядка для акции. Это зависит от количества соответствующих дней для цены закрытия акции. Ряд Фурье поддерживает линейный LSA, пытаясь свести на нет его недостатки. Подгоняя ряд Фурье к расходящейся цене закрытия, мы создали точную функцию для представления необработанных данных. Мы будем использовать эту функцию для получения графика прогноза. Мы построим эту функцию на следующие 30 рабочих дней после 12 сентября. Модель, однако, не завершена.
- Теперь функция ряда Фурье вычитается из разницы в цене. Это даст нам шум. Шум представляет собой данные, которые случайным образом изменяют цену акции. Мы будем использовать шум, чтобы создать область приближения для нашей модели, чтобы дать нам точное представление о том, куда будет двигаться фактическая цена. Мы берем среднее значение абсолютного значения шума. Если мы сложим и вычтем среднее значение из графика прогноза цен (линейный LSA плюс ряд Фурье), мы получим верхнюю и нижнюю границы области аппроксимации.
- TФункция ряда Фурье и LSA суммируются для получения функции прогноза цен. Затем мы берем среднее значение абсолютного значения шума. Мы добавляем и вычитаем средний шум из функции прогноза, чтобы получить верхнюю и нижнюю границы области прогнозирования. Мы наносим точные данные о ценах, прогноз цен, область приближения и фактическую цену после 12 сентября, чтобы определить, была ли модель точной.
- Мы рассчитали отклонение прогнозируемой линии от реальной цены в процентах. Получены максимальный, минимальный и средний процент неточности линии прогноза. Мы вычислили, насколько далеко максимальная и минимальная погрешности от области аппроксимации в долларовом эквиваленте и от того, насколько они соответствуют области аппроксимации.
- Используя предыдущие расчеты, мы решили, что средняя допустимая погрешность будет в пределах 95% доверительного интервала (ДИ). Мы вывели логарифмические изменения цен и использовали их, чтобы найти стандартное отклонение различных акций. Мы взяли два стандартных отклонения, чтобы определить 95% доверительный интервал и сравнить его со средней погрешностью в процентах для акций.
- Волатильность была рассчитана, чтобы увидеть ее связь с эффективностью модели. Мы изучили историческую волатильность ценовых данных, чтобы понять, насколько волатильными были графики и повлияли ли они на модель.
Блок-схема прогноза цен на акции представлена на рисунке 2.
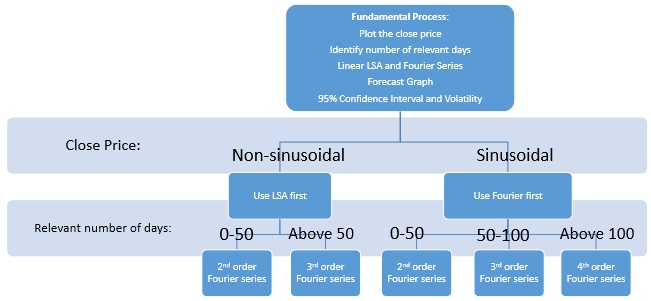
Рисунок 2 – Блок-схема для прогнозирования цен на акции
Мы смоделировали несглаженные и сглаженные версии для каждой из десяти выбранных акций, причем каждая акция имела сводку результатов и анализа. Наконец, мы сравнили две версии, сделали выводы относительно максимально допустимой неточности, полученные с помощью 95% доверительного интервала, и решили, какая версия модели лучше.
Поскольку представленные здесь акции выбраны из NASDAQ(американская биржа, специализирующаяся на акциях высокотехнологичных компаний), мы решили включить в модель индекс NASDAQ и выяснили, какое влияние он оказывает на прогнозирование акций. Мы модифицировали улучшенную версию модели, включив NASDAQ в процесс прогнозирования цен на акции. Мы сопоставили данные NASDAQ с данными о ценах закрытия данной акции за соответствующее количество дней для данной цены акции. Однако индекс имеет огромные числа, поэтому мы решили нормализовать его между 0 и 1. Мы использовали комбинацию корреляции и нормализованного NASDAQ для получения нового графика прогноза.
Список источников
- Maedche A., Staab S. The Text-To-Onto Ontology Learning Environment. Software Demonstration at the Eighth International Conference on Conceptual Structures, Berlin: Springer-Verlag; 2000.
- Ziemba P., Wątróbski J., Zioło M., Karczmarczyk A. Using the PROSA Method in Offshore Wind Farm Location Problems Energies, 10 (2017), p. 1755
- Adrian B. Incorporating ontological background knowledge into Information Extraction. Doctoral Consortium. ISWC 2009, 2009.
- Faizi S., Sałabun W., Rashid T., Wątróbski J., Zafar S. Group Decision-Making for Hesitant Fuzzy Sets Based on Characteristic Objects Method Symmetry, 9 (2017), p. 136
- Noy N., McGuiness D. Ontology Development 101: A Guide to Creating Your First Ontology, Stanford Knowledge Systems Laboratory, Stanford, CA, USA (2001)