
POSSIBLE DISADVANTAGES AND DIFFICULTIES IN DEVELOPING THE SPEECH RECOGNITION MODULE
Content
- Introduction
- 1. Relevance of the topic
- 2. Major problems with speech recognition
- 2.1 Problems of noise immunity of speech
- 2.2 Disadvantages of the interface
- 2.3 External noise
- 2.4 Semantics problems
- 2.5 Investment and demand
- 3. Planned practical results
- 3.1 Overview of research and development related to the topic
- 4. Development of a voice recognition engine
- 4.1 Review of national sources
- 4.2 The main components of the recognition system
- Conclusions
- List of sources
Introduction
In the era of the Internet, almost everyone has access to its benefits, such as: smartphones, tablets, laptops with some set of applications in them. Software data (software) are created for entertainment, simplification of communication with loved ones, help in work, study, etc. Their main purpose is to simplify or slightly diversify life. The number of such applications is growing exponentially every day, but the real usefulness for the user of each such software on average and in general statistics it is small. The overall high level of their uselessness arises from the prevalence of programs whose main focus is on the entertainment of a certain audience of users, over those that are created for specific tasks, such as controlling electronic or digital devices by voice.
1. Relevance of the topic
ЗAnd in the past decades, quite a few programs for voice recognition have appeared, but the peak of speech recognition accuracy in general occurred in the late nineties - early two thousandths. The efficiency of modern systems to distinguish the parameters and properties of speech is at the level of approximately 80% accuracy, while in humans this indicator reaches 95% [1].
Today, there are many directions for the development of sound processing technologies, such as automatic speech recognition systems (CAPP), which are used to provide a voice dialogue between a person and a computer, or voice keys that provide voice recognition of a person. The considered direction of growth of speech processing systems is very promising, since, in addition to high demand in business and everyday life, it can create a symbiosis with other giant projects in the investment market, they are artificial intelligence systems and the Internet of things. These capabilities will grow exponentially over the next ten years, thanks to large investments and growing demand for speech recognition software [2].
2 Major problems with speech recognition
2.1 Problems of noise immunity of speech
This problem is primarily related to the presence of noise when recording speech. Each person has his own manner of conducting a dialogue, as well as pronunciation and accent, all this can have a bad effect on the quality of the parsing of voice data by the system when recording and recognizing speech. The most noticeable errors are in cases where there will be a need for several speakers, since with one the system is easier to adapt to some vocal, human characteristics [3].
A characteristic feature of a person's dialect is to take into account his continuous speech, or vice versa, separate. The first type complicates the recognition of words, since it is more difficult for the voice application to distinguish the boundaries of the speaker's words with this pronunciation. [4] Thus, it is necessary that the speaker-dependent system be able to accurately and on the first attempt "hear" the entire dialogue. Therefore, for the system, it is necessary to determine the minimum lower time threshold for the pause between words during pronunciation, so that the speech is not continuous.
2.2 Disadvantages of the interface
The developed application for working with sound should be oriented, when forming the interface, both for a professional computer user and for a beginner. The shell of the program must be native, that is, it must be easy to learn and understandable from the first time you use it. It is also worth considering the presence of a responsive layout, so that the application can be opened in any browser on any type of device, without changing the original layout.
2.3 External noise
An important factor of a precisely understood word or whole sentence by the system is the indicator of the surrounding sounds of the broadcaster, i.e. noise. For a person, the noise level is not as important as for a speech recognition device, because a person is able to distinguish words well even at an indicator of 80-90 dB, which is equivalent to noise at a bus stop or a nearby motorcycle. But with the considered "electronics" not everything is so simple, because it is not able to learn to accurately distinguish the semantic features of any of the known languages of the world, we are talking about neural networks (machine learning), due to the inexpediency or impossibility of collecting the necessary, sufficient amount of data for identification in the conversation of the announcer of homophones. If you ignore the above, the probability of incorrect definition of words increases by one and a half times, which can be seen in Diagram 1 [5]. Therefore, in order to reduce the cost of dealing with external noise, it is worth minimizing them when recording the speaker's speech for its recognition by the system.
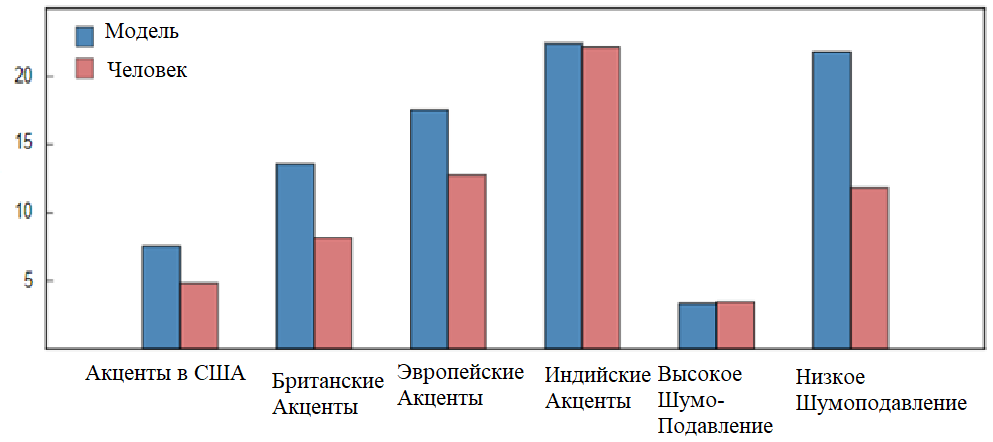
Diagram 1 - The level of erroneous pronunciation of the words of a machine and a person, in different languages.
The presence of more than one speaker also has a negative effect on the quality of the system. People can perceive information from several sources at the same time, in contrast to the corresponding devices. However, it is possible to make an application that would be multi-streaming, that is, it could perceive the speech of several people at the same time. Or, you can program the recognition device so that text is recorded only when the voice of a particular speaker is recognized. Speaker recognition can be divided into speaker identification and verification. Speaker identification is the process of determining which of the registered speakers uttered a phrase. Narrator verification is the process of accepting or rejecting a narrator's stated identity. Most applications that use voice are authenticated by a speaker classified by speaker verification [6]. Therefore, it is necessary to decide in advance what needs to be done by a system that clearly performs tasks at minimal additional costs, or a system that can do the same thing, but in any conditions and at unnecessary costs.
The following sources of external voices or their root causes can be classified into these types:
- Using codecs that are not suitable to eliminate all possible noise
- Disadvantages of software, the essence of which is the lack of balance between the performance of the application and the quality of the work performed by it.
- НThe presence of reverberation due to the peculiarities of the premises in which this speech recognition system can be used, and the inability of the above codecs to solve this problem (Fig. 2)[5].
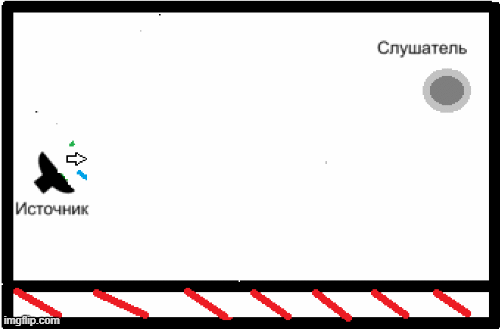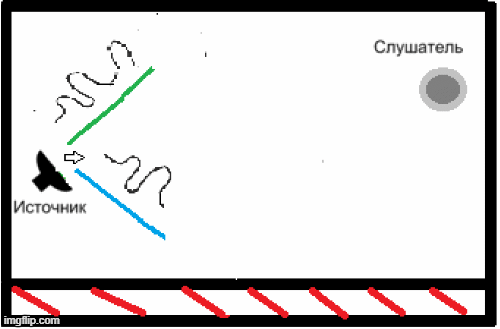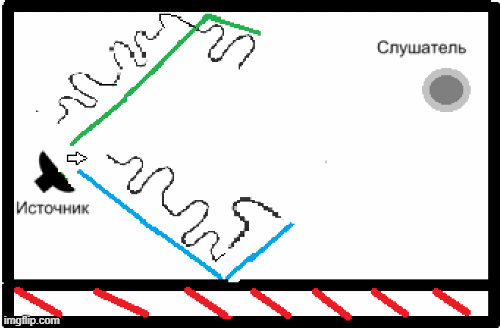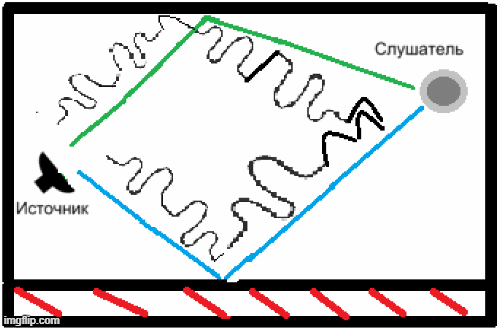
Figure 2 - An example of the appearance of reverberation in a closed room.
2.4 Semantics problems
In everyday speech of each person, lexical, stylistic, phraseological and other pronunciation errors occur. It is also worth noting the presence of homographs and homophones in the conversation, which will have a very negative effect on the quality of the recognition system, since it can confuse homophones, but this can be easily corrected by repeating an incorrectly spoken phrase, and a homograph is an error that is embedded in the code or memory of the system and solve a problem of this nature is possible with the help of the developer of this application or technical support.
2.5 Investment and demand
To start creating any serious application, Internet or local, you need monetary funding. Its presence is necessary for staff motivation, various technical purchases, for consumer market research and other types of costs. Research of market demands of potential and actual consumers contributes to the creation of a clear and successful plan for the development and implementation of the project. Without researching existing consumer demand, it is more difficult to predict the future, and as a result, this increases the risks of collapse of almost any "startup", because the creation of a product must satisfy someone's needs. An example is the development of an algorithm program for removing noise from audio when communicating online, which was created for applications that receive speech as an analogue and became ready for use. But there was no buyer for it, since it would not have brought tangible changes to the operation of already proven systems to large manufacturers.
It is worth noting that in the absence of investors, the project manager may have primary capital, which for the project itself will be tantamount to investment. But the investor will save time spent on raising their capital, can help promote the startup, provided that there is already a workable model or prototype of the final product expected in the end. Otherwise, if there is no capital or investment, then the chances of having the necessary recruitment (development team) will decrease, and it will also not be possible to conduct a comprehensive research of the consumer market, which will reduce the chance of success.
3 Planned practical results
As a result of the development of the speech recognition system, an application is planned that should "perceive" the usual continuous dialogue of the speaker. With the available resources, you should achieve the result of a minimum pause between words of an ordinary user of about seven hundred milliseconds. With this level, the minimum time, the quality of word recognition should be good and at the same time accurate (with a minimum amount of error). This application should not interfere with the work of other processes of the devices on which it will be installed, and also should not take up free RAM space, in addition to what will be indicated in the recommended system requirements.
3.1 Overview of research and development related to the topic
Within DonNTU, research was carried out on topics similar to this one, such as: algorithms of sound segmentation, in which it was necessary to mention the search for the boundaries of consonants with division into hissing, voiced and deaf, as well as a pure voice signal. In the above work, a detailed classification of sounds and phonemes was made, which ultimately made it possible to more accurately recognize deaf plosives at the end of the signal, thereby providing an opportunity to distinguish them from the area of silence [7].
It is also worth paying attention to one more work on the integration of visual and speech methods of controlling the process of entering and editing text information by the method of fuzzy matching and fuzzy DTW-matching of speech images. The speech signal is presented in the form of a two-dimensional spectral temporal image, on the basis of which it is possible to compare the methods of recognition of speech commands, which will further help the development of DTW-matching of sound commands [8].
On a global scale, one can single out the development of an audio codec for suppressing external noise by the company "2Hz". The purpose of the development was to achieve the required level of noise removal, when transmitting speech to a sound processing device, in a time that has not reached any other similar time at a minimum cost of the system power of the user's device. The solution to this problem was to be dealt with by a created neural network that works with sounds at frequencies of 8 and 16 kHz for phones and VoIP applications, respectively. As a result, the main tasks were completed, and the codec was named "Krisp" [9].
4 Development of a speech recognition engine
4.1 The main components of the recognition system
The creation of a speech recognition application implies the creation of a system, in the development of which it is necessary to take into account a number of factors that directly affect the quality and performance of the expected product in the end. These factors include the presence of labels - the beginning of a conversation, the use of specialized software, speaker addiction, etc.
Marks by which the device will be able to understand when to start recording speech, i.e. some "start words". When pronouncing this mark, the conversation should be recorded, while the user pre-selects how long the recording will take, for example, five seconds (if the commands reserved by the system are pronounced) or about a minute or more (for speech recognition and converting to text or for similar tasks), if necessary, it is possible to add a "stop word" to stop recording.
The system should also contain programs that convert the audio signal data into speech, called codecs. Their task will be to eliminate the shortcomings of a person's speech: poor diction, rare conversational accents, etc., so these programs will have to remove unnecessary noise in the previously described situations.
The next important component of the speech system is speaker dependence, the application can be speaker dependent or speaker independent. The proposed system will be focused on speaker independence for the user to minimize the risks of unsuccessful recording of his voice. This can happen due to the physiological properties of the body, such as: adolescent voice mutation, changes in tone in respiratory and similar diseases of the human nasopharynx, etc. It will also speed up the operation of the application, because the number of voice and speech recognition processes will be reduced, and, consequently, the operating time of the device itself. Such systems do not need to be trained and adjusted for a specific speaker, which will reduce the size of the entire application in the end. In this case, a vulnerability may appear in the form of an opportunity for an outsider to use the device by means of voice control, but this can be avoided, for example, by blocking access to it.
4.2 Speech recognition method
To simplify and speed up the process of processing the data of the speaker's voice, it is necessary to divide speech into elementary components - phonemes. This is the simplest unit of the language, which carries the minimum required amount of semantic information sufficient to determine the spoken word by the user of the application. Thus, it turns out to build a model according to which the system can perceive the above-described data, it is built from the smallest unit - a phoneme, which goes to a word, and sentences are already obtained from words, etc.
Such a model is well suited for using neural networks based on a self-organizing feature map. According to these signs, the data should be averaged by a statistical method, which will solve the problem of speech variability[10]. But genetic neural algorithms are more suitable, they surpass the previous ones in flexibility of changes in their architecture. Its simplicity lies in the use of selection rules that determine the level of performance of neural networks in one selection and specify settings and changes for subsequent selections[10].
CONCLUSIONS
In the course of the work, the main problems and difficulties were considered that must be foreseen and prevented when developing a speech recognition module. The main difficulty in creating such a system is the impossibility of adjusting its operation to the peculiarities of the speech of each person, due to the large range of speech characteristics of the users of this application, since each has its own accent, its own manner of pronunciation or dialect. Therefore, the development of such algorithms, systems and other software software aimed at improving the quality level and improving the existing developments in speech recognition will be relevant for a very long time.
LIST OF SOURCES
- Создание систем распознавания речи. [Электронная библиотека студента] // Библиофонд. — Режим доступа: href="https://www.bibliofond.ru/view.aspx?id=871454 (дата обращения: 17.09.2021).
- Системы автоматического распознавания речи. [Электронный ресурс] // КомпьютерПресс. — Режим доступа: https://compress.ru/article.aspx?id=11331 (дата обращения: 25.09.2021).
- Хеин Мин Зо. Современное состояние проблемы обработки, анализа и синтеза речевых сигналов. [Электронный ресурс] // Сyberleninka. — Режим доступа:https://cyberleninka.ru/article/n/sovremennoe-sostoyanie-problemy-obrabotki-analiza-i-sinteza-rechevyh-signalov/viewer (дата обращения: 07.10.2021).
- Федосин С.А., Еремин А. Ю. Классификация систем распознавания речи. // Мордовский государственный университет им. Н. П. Огарева. — Режим доступа: http://fetmag.mrsu.ru/2010-2/pdf/SpeechRecognition.pdf (дата обращения: 10.10.2021).
- Проблемы распознавания речи: что еще предстоит решить. [Электронный ресурс] // AppTractor. — Режим доступа: https://apptractor.ru/info/articles/problemyi-raspoznavaniya-rechi-chto-eshhe-predstoit-reshit.html (дата обращения: (10.10.2021).
- Кулибаба О.В. Распознавание диктора. // Донецкий Национальный Технический Университет. — Режим доступа:http://masters.donntu.ru/2010/fknt/kulibaba/library/article8.htm (дата обращения: 12.10.2021).
- Костенко А.В. Новые подходы к проблемам конца речевого сигнала . // Донецкий Национальный Технический Университет. — Режим доступа:http://masters.donntu.ru/2012/iii/kostenko/diss/index.htm#p6 (дата обращения: 12.10.2021).
- Бондаренко И.Ю. Интеграция визуального и речевого способов управления процессом ввода и редактирования текстовой информации. // Донецкий Национальный Технический Университет. — Режим доступа: http://masters.donntu.ru/2006/fvti/bondarenko/diss/index.htm#Chapter41 (дата обращения: 12.10.2021).
- Математики из Армении создали сервис, который убирает посторонние звуки во время звонков. [Электронный ресурс] // VC. — Режим доступа:https://vc.ru/services/56580-matematiki-iz-armenii-sozdali-servis-kotoryy-ubiraet-postoronnie-zvuki-vo-vremya-zvonkov (дата обращения: 17.10.2021).
- Харченко В. А. Разработка модели голосового управления автомобилем на основе субполосного анализа. // Белгородский Государственный Национальный исследовательский университет. — Режим доступа:http://dspace.bsu.edu.ru/bitstream/123456789/28033/1/Kharchenko_Razrabotka_17%20%281%29.pdf (дата обращения: 27.10.2021).