
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета та завдання дослідження
- 3. Аналіз тональності тексту
- 3.1 Огляд алгоритмів
- 3.1.1 Концепція визначення тональності за допомогою Bag-of-words
- 3.1.2 Концепція визначення тональності за допомогою TF-IDF
- Висновки
- Список використаних джерел
Вступ
В останні роки значні зусилля були присвячені вивченню та класифікації двох із трьох основних компонентів музики: тонів та ритмів. Але є ще й третій компонент, якому приділялося порівняно менше уваги - тест пісень.
Вивчення текстів пісень відрізняється від загального сентиментального аналізу, наприклад, літератури. Тексти пісень можуть мати атрибути, які є недоречними в літературі або формальній прозі, наприклад, повторення, римування та ритмічне виконання. Більш того, можна припустити, що тексти можуть мати більш високу тенденцію бути шаблонними або навіть клішовані, що робить їх більш піддаються аналізу шаблонів, ніж проза в цілому.
1. Актуальність теми
Тексти пісень — це неструктурована інформація, обробляти яку вручну надто важко. Але збирати і обробляти інформацію необхідно хоча б тому, що це дає можливість отримувати нову інформацію з наявних даних, за допомогою якої можна підвищити різноманітність прийнятих рішень. У зв'язку з цим завдання автоматичного аналізу даних є актуальною, і для її вирішення розроблено багато методів та моделей. Одним із методів є Data Mining.
Data Mining - процес автоматичного виявлення у вихідних даних прихованої інформації, яка раніше не була відома, нетривіальна, практично корисна та доступна для інтерпретації людиною [1].
Ця тема є актуальним завданням, тому що на сьогоднішній день багато музичних служб (Apple Music, Яндекс.Музика) проводять аналіз пісень, які слухає користувач і підлаштовує під них плейлисти з тим настроєм пісень, які користувач слухає найбільше.
2. Мета та завдання дослідження
Об'єкт дослідження: визначення тональності тексту пісень.
Предмет дослідження: Ефективність методів визначення тональності тексту, які застосовуються для бібліотеки тестів пісень.
Метою дослідження є вивчення підходів до аналізу тональності тексту, а також розробка інструменту для проведення аналізу тональності, завантаженого текстів пісень та генерації статистики на їх основі.
Основні завдання дослідження:
- вивчення алгоритмів визначення тональності тексту;
- створення власного корпусу текстів найпопулярніших пісень;
- розробка власного алгоритму визначення тональності тексту з прикладу текстів пісень відомих виконавців;
- розробка програмної моделі для визначення тональності завантажених текстів пісень та складання статистичних даних на їх основі.
В рамках магістерської роботи планується отримання актуальних наукових результатів за такими напрямками:
- переваги та недоліки алгоритмів щодо визначення тональності тексту;
- переваги та недоліки визначення тональності тексту за допомогою комп'ютера.
Планується, що дана система матиме:
- інтуїтивно зрозумілий інтерфейс користувача з підказками;
- оптимізований алгоритм для роботи;
- можливість збереження результатів сеансів для подальшої роботи.
3. Аналіз тональності тексту
Розглянемо ключові поняття, які необхідно знати для визначення тональності тексту, також розглянемо два підходи (алгоритми) для визначення тональності тексту та засоби, які використовують дані алгоритми.
Аналіз тональності, також званий інтелектуальним аналізом думок, - це підхід до обробки природної мови, який визначає емоційний тон, прихований за основною частиною тексту. Це популярний спосіб для організацій визначати та категоризувати думки про продукт, послугу або ідею.
Системи аналізу настроїв допомагають збирати інформацію з неорганізованого та неструктурованого тексту, що надходить з онлайн-джерел, таких як електронні листи, повідомлення в блогах, заявки на службу підтримки, веб-чати, канали соціальних мереж, форуми та коментарі. Алгоритми замінюють ручну обробку даних реалізацією, що базуються на правилах, автоматичних або гібридних методів [1]. Системи з урахуванням правил виконують аналіз настроїв з урахуванням зумовлених правил, заснованих на лексиці, тоді як автоматичні системи навчаються даних за допомогою методів машинного навчання. Гібридний аналіз настроїв поєднує у собі обидва підходи.
У загальному випадку, завдання аналізу тональності тексту еквівалентна задачі класифікації тексту, де категоріями текстів може бути тональні оцінки. Приклади тональних оцінок:
- позитивна;
- негативна;
- нейтральна (текст не містить емоційного забарвлення).
Основні етапи аналізу тональності показані на малюнку 1 [8].

Малюнок 1 — Основні етапи аналізу тональності
(анімація: 10 кадров, 3 циклів повторення, 57 кілобайт)
Основна ідея аналізу - перетворити неструктурований текст на значну інформацію.
3.1 Огляд алгоритмів
Аналіз тональності використовує різні методи та алгоритми обробки природної мови, які ми розглянемо докладніше у цьому розділі.
Основні типи алгоритмів аналізу тональності, що використовуються, включають:
- урахування правил: ці системи виконують аналіз настроїв з урахуванням набору правил, створених вручну;
- автоматично: системи покладаються на методи машинного навчання, щоб вчитися на даних;
- гібридні системи поєднують у собі підходи, засновані на правилах та автоматичні.
Розглянемо підходи, що ґрунтуються на правилах. Зазвичай система, яка базується на правилах, використовує набір правил, створених людиною, щоб допомогти ідентифікувати суб'єктивність, полярність або предмет думки.
3.1.1 Концепція визначення тональності за допомогою Bag-of-words
Модель набору слів Bag-of-words, або скорочено BoW, - це спосіб отримання функцій з тексту для використання в моделюванні, наприклад, з алгоритмами машинного навчання [9]. Підхід дуже простий і гнучкий, і його можна використовувати безліччю способів для отримання функцій з документів.
Пакет слів - це уявлення тексту, яке визначає поява слів у документі. Це включає дві речі:
- Словник відомих слів.
- Захід відомих слів.
Це називається «мішком» слів, тому що будь-яка інформація про порядок чи структуру слів у документі відкидається. Модель дбає лише про те, чи зустрічаються відомі слова в документі, а не десь у документі.
Інтуїція нагадує, що документи схожі, якщо вони мають схожий зміст. Крім того, тільки за змістом ми можемо дізнатися про значення документа.
Пакет слів може бути таким простим чи складним, як вам подобається. Складність полягає як у прийнятті рішення у тому, як скласти словник відомих слів (чи знаків), і у тому, як оцінити наявність відомих слів.
Розглянемо корпус (набір текстів) документів D {d1, d2…..dD}, і N унікальних токенів, витягнутих з корпусу C. N токенів (слів) сформують список, а розмір матриці M мішка слів буде заданий DX N. Кожний рядок в матриці M містить частоту токенів у документі D(i).
Наприклад, якщо у вас є 2 рядки з пісні:
- D1: All my loving I will send to you.
- D2: All my loving, darling I will be true.
Він створює словник, використовуючи унікальні слова з усіх документів („my"“, „loving“, „I“, „send“, „you“, „true“, „darling“). Як видно з наведеного вище списку, ми не розглядаємо „all“, „will“, „be“ у цьому наборі, тому що вони не передають необхідної інформації, необхідної для моделі.
Матриця M розміру 2x6(D = 2 – кількість документів, N = 6 – кількість слів у словнику) представлена в таблиці 1.
Таблиця 1 — Матриця M розміру 2x6
| My | loving | I | Send | You | True | Darling | |
| D1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| D1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
У наведеній таблиці показані функції навчання, що містять частоту термінів кожного слова в кожному документі. Це називається підходом „мішка слів“, оскільки в цьому підході має значення кількість входжень, а не послідовність чи порядок слів.
3.1.2 Концепція визначення тональності за допомогою TF-IDF
TF-IDF (термін «частота-зворотна частота документів») - це статистична міра, яка оцінює, наскільки слово релевантне документу в колекції документів [10].
TF-IDF був винайдений для пошуку документів та отримання інформації. Він працює, збільшуючись пропорційно до кількості разів, коли слово з'являється в документі, але компенсується кількістю документів, що містять це слово. Таким чином, слова, які є спільними в кожному документі, такі як this, what та if, мають низький рейтинг, навіть якщо вони можуть зустрічатися багато разів, оскільки вони не мають великого значення для цього документа зокрема.
Однак, якщо слово „помилка“ зустрічається багато разів у документі і не часто зустрічається в інших, це, ймовірно, означає, що воно є дуже актуальним [5]. Наприклад, якщо те, що ми робимо, намагається з'ясувати, до яких тем відносяться деякі відповіді NPS, слово „помилка“, ймовірно, буде пов'язане з темою „Надійність“, оскільки більшість відповідей, що містять це слово, стосуватимуться цієї теми.
Зазвичай вага TF-IDF складається з двох членів:
- частота терміна (TF);
- зворотня частота документів (IDF).
Перший обчислює нормалізовану частоту терміна (TF).
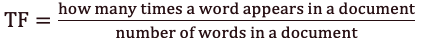
Малюнок 2 — Формула частоти терміна (TF)
Розглянемо текст пісні The Way You Make Me Feel Майкла Джексона, що містить 493 слова, в якому слово Baby зустрічається 10 разів. Тоді термін частоти (TF) для слова Baby дорівнює 49,3.
Другий член – це зворотня частота документів (IDF).
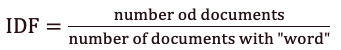
Малюнок 3 — зворотної частоти документів (IDF)
Припустимо, у нас є текст 190 пісень Майкла Джексона, і слово Baby зустрічається в 85 з них. Тоді зворотня частота документів (IDF) дорівнюватиме 0.35.
Формула для визначення ваги TF-IDF:
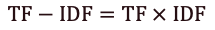
Малюнок 4 — Формула для визначення ваги TF-IDF
У наведених вище прикладах частота терміна дорівнює 493, а частота зворотного документа - 035.
Таким чином, вага TF-IDF є добутком цих величин: 49,3 * 0,35 = 17,2.
Висновки
У ході виконання даної роботи проаналізовано алгоритми та класифікації для ідентифікації інформації. Після детального вивчення були виявлені недоліки та плюси розглянутих підходів. Як результат проведеного огляду можна назвати такі напрями досліджень:
- Докладне дослідження методів Bag-of-words та TF-IDF.
- Розробка комбінованих методів.
Зокрема, інтерес представляють методи Bag-of-words і TF-IDF, оскільки вони досить прості у розумінні та реалізації. Перспективами дослідження є розробка власного алгоритму з їхньої основі.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: июнь 2022 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список використаних джерел
- Пескова О. В. Алгоритмы классификации полнотекстовых документов // Автоматическая обработка текстов на естественном языке и компьютерная лингвистика. – М.: МИЭМ (Московский государственный институт электроники и математики), 2011. – С. 170 – 212.
- Rachel Harsley. Hit Songs’ Sentiments Harness Public Mood & Predict Stock Market / Rachel Harsley, Bhavesh Gupta, Barbara Di Eugenio, and Huayi Li // WASSA 16 - 2016 - pp. 17–25 — [Ссылка].
- Yunqing Xia. Lyric-based Song Sentiment Classification with Sentiment Vector Space Model / Yunqing Xia, Linlin Wang, Kam-Fai Wong, Mingxing Xu // ACL-08 - 2008 - pp. 133–136 — [Ссылка].
- Сперцян К.М. Сравнительный анализ методов определения эмоциональной окраски сообщений в социальных сетях с применением обучения с учителем / Н.Ю. Рязанова, К.М. Сперцян. // Новые информационные технологии в автоматизированных системах. Компьютерные и информационные науки. — 2018 — [Ссылка].
- Семина Т.А. Анализ тональности текста: современные подходы и существующие проблемы / Т.А. Семина // Социальные и гуманитарные науки. Отечественная и зарубежная литература. Сер. 6, Языкознание: Реферативный журнал. — 2020 — С. 47-64 [Ссылка].
- Пилипенко А.С., Исследование методов и алгоритмов определения тональности естественно-языкового текста, Донецкий национальный технический университет, 2018 Режим доступа: [Ссылка].
- Ландэ Д. В. Интернетика Навигация в сложных сетях Модели и алгоритмы. — М.: Книжный дом „ЛИБРОКОМ“, 2009. — с. 87-88.
- Классификация текстов и анализа тональности [Электронный ресурс] — [Ссылка].
- Wisam A. Qader. An Overview of Bag of Words; Importance, Implementation, Applications, and Challenges / Wisam A. Qader, Musa M.Ameen, Bilal I. Ahmed //Fifth International Engineering Conference on Developments in Civil & Computer Engineering Applications 2019 - (IEC2019) - Erbil - IRAQ — [Ссылка].
- Bijoyan Das. An Improved Text Sentiment Classification Model Using TF-IDF and Next Word Negation / Bijoyan Das, Sarit Chakraborty // IEEE, Kolkata, India - 2018 — [Ссылка].