
Реферат по теме выпускной работы
Содержание
- Введение
- 1 Интерактивные игры на основе искусственного интеллекта: состояние и перспективы
- 2 Архитектура современных генеративных моделей
- 2.1 Преобразование входных данных
- 2.2 Архитектура трансформера
- 3 Обучение генеративных моделей
- 3.1 Алгоритмы постобучения
- 3.2 LoRA
- Заключение
- Список источников
Введение
В последние годы наблюдается значительный прогресс в области искусственного интеллекта, особенно в сфере обработки естественного языка. Одной из ключевых технологий, ускоривших это развитие, стали генеративные нейронные сети[1]. Данная технология открыла новые возможности для применения в самых различных областях, и одной из таких областей является разработка интерактивных игр.
Интерактивные игры всегда стремились создать уникальный и персонализированный игровой опыт для каждого игрока. Традиционные игровые механики и сценарии ограничены возможностями заранее прописанных сценариев, что часто приводит к однообразию игровых ситуаций. С внедрением генеративных нейронных сетей стало возможным создание динамичных и непредсказуемых сюжетных линий, способных адаптироваться под действия игроков в режиме реального времени.
Генеративные модели, такие как GPT[2] или Llama[3], показали отличные результаты в создании реалистичных текстов. Использование таких моделей в играх может позволить разработчикам создавать разнообразные сюжетные линии, которые не просто реагируют на действия игроков, но и генерируют уникальные и персонализированные истории. Это позволяет играм выходить за рамки традиционных сюжетных структур и формировать настоящие «живые» миры.
Целью данной работы является исследование и разработка подходов к использованию генеративных нейронных сетей для создания интерактивных игр. В рамках работы будет рассмотрено, как можно интегрировать генеративные модели в игровые системы, какие подходы можно использовать для тренировки таких моделей, и как они могут взаимодействовать с игроком.
1 Интерактивные игры на основе искусственного интеллекта: состояние и перспективы
Интерактивные игры на основе искусственного интеллекта находятся на пересечении игровых технологий и прогресса в области машинного обучения, создавая новые способы взаимодействия игрока с виртуальными мирами. Современные генеративные нейронные сети значительно расширяют возможности создания сложных сюжетов, динамичных персонажей и нелинейных диалогов. Эти модели могут генерировать уникальные ответы, формировать непредсказуемые события и адаптироваться к поведению пользователя, что делает игровой процесс более захватывающим и персонализированным.
Сегодня искусственный интеллект уже активно используется для создания неигровых персонажей, которые способны вести более естественные диалоги и реагировать на действия игрока. Ключевым элементом здесь является возможность адаптации и обучения на больших объемах данных, что позволяет моделям понимать контекст, предсказывать действия и генерировать новые сценарии в реальном времени. Одним из важных направлений является создание динамических сюжетов, которые могут изменяться в зависимости от действий игрока, создавая тем самым уникальные игровые сессии для каждого пользователя.
Перспективы интерактивных игр заключаются в еще более тесной интеграции генеративных моделей в игровой процесс. Будущие игры смогут предлагать игрокам неограниченное количество сценариев и ответов, основанных на непрерывном обучении моделей. Возможности таких игр включают генерацию не только текстов и диалогов, но и создание целых уровней, игровых миров и персонажей на основе предпочтений и стиля игры пользователя. Это открывает двери для игр с открытым миром, где каждое действие игрока может кардинально изменять игровой ландшафт и сюжет.
Одной из значительных проблем на пути развития таких игр является необходимость больших вычислительных ресурсов для работы с крупными языковыми моделями в реальном времени. Однако с развитием технологий аппаратного ускорения и распределенных вычислений эта проблема постепенно становится менее актуальной. Еще одной задачей является повышение уровня контроля над генерацией историй, чтобы избегать случайных или нелогичных действий со стороны искусственного интеллекта, что требует тонкой настройки моделей и методов дообучения.
В долгосрочной перспективе искусственный интеллект может сыграть ключевую роль в создании игр, которые предлагают более глубокие и персонализированные сюжеты, создавая уникальные игровые миры для каждого игрока.
2 Архитектура современных генеративных моделей
Современные генеративные нейронные сети основаны на архитектуре трансформер, которая стала революционным подходом в обработке естественного языка. Архитектура трансформер, предложенная в статье "Attention is All You Need"[4], заменила прежние рекуррентные нейросети и сверточные сети благодаря более эффективной обработке данных, особенно в задачах генерации текста.
Трансформеры обладают рядом преимуществ. Во-первых, они эффективно моделируют длинные зависимости, благодаря механизму внимания, который позволяет учитывать связи между словами на любом расстоянии. Во-вторых, трансформеры обеспечивают параллельную обработку последовательностей, что ускоряет обучение и предсказание, в отличие от рекуррентных сетей. Наконец, они масштабируемы — современные крупные языковые модели используют расширенные версии трансформеров, что позволяет им обучаться на огромных наборах данных и работать с миллиардами параметров для точной генерации текста.
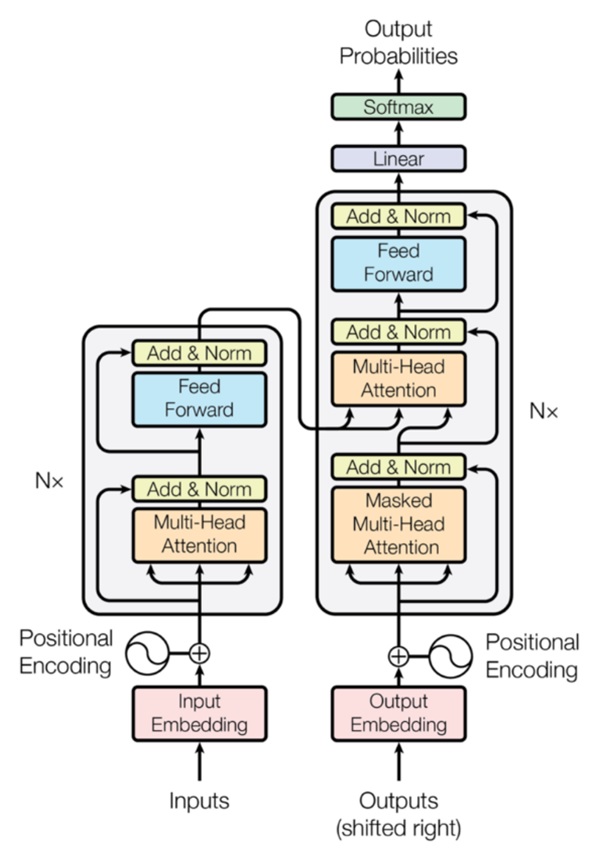
Рисунок 1 – Базовая архитектура трансформер
2.1 Преобразование входных данных
Перед тем как данные поступают в модель, они проходят несколько важных шагов обработки:
- Входной текст разбивается на отдельные элементы — токены. Токены могут представлять собой слова, части слов, символы или байты, в зависимости от выбранного подхода к токенизации. Эти токены — числовые представления элементов текста.
- После токенизации каждый токен преобразуется в вектор фиксированной длины, называемый эмбеддингом. Эмбеддинги — это плотные векторные представления токенов, которые захватывают семантическую информацию о словах. То есть, слова с похожим значением или использованием будут иметь схожие эмбеддинги. Например, слова "кот" и "кошка" будут иметь схожие векторные представления, так как они связаны по смыслу.
Эмбеддинги обучаются на больших объемах данных и содержат информацию, позволяющую модели понимать взаимосвязь слов и контекста. В процессе генерации текста модель использует эмбеддинги, а не непосредственно токены, что позволяет более гибко учитывать семантику и структуру языка.
Механизм внимания – основной блок архитектуры трансформер – не учитывает порядок токенов в последовательности. Для того, чтобы исправить этот недостаток, используются позиционные эмбеддинги. Позиционные эмбеддинги добавляются к эмбеддингам токенов, чтобы зафиксировать информацию о том, на каком месте в последовательности находится каждый токен. Это позволяет модели различать порядок слов.
2.2 Архитектура трансформера
Трансформер состоит из двух основных частей: энкодера и декодера, каждый из которых построен на блоках с механизмом многоголовой внимания и полносвязных слоев. Однако в современных генеративных моделях используется только декодер.
Основные блоки декодера:
- Multi-head self-attention(или grouped-query attention [5]) — это ключевой механизм, который позволяет модели концентрироваться на разных частях входной последовательности при генерации текста. Каждая "голова" внимания вычисляет весовые коэффициенты, которые помогают определять важные части входных данных. Для генеративных моделей используется механизм самовнимания, где модель анализирует свои собственные предыдущие выходные данные, чтобы предсказать следующее слово. Важно, что в генеративных моделях используется маскированное внимание, то есть при каждом шаге внимание ограничено только предыдущими токенами, чтобы модель не могла "видеть" будущее во время генерации.
- Layer Normalization[6] – это техника нормализации входных данных для каждого отдельного слоя нейронной сети. Она улучшает стабильность обучения, нормализуя значения активаций внутри слоя с использованием их среднего значения и стандартного отклонения, рассчитанных по всем нейронам слоя.
- Feed-Forward – слой, отвечающий за обработку информации и усиление способности модели к запоминанию и извлечению информации[7]. Он состоит из двух линейных слоев и нелинейной функцией активации между ними.
- Residual Connections[8] – это архитектурный элемент в нейронных сетях, который позволяет пропускать информацию через слои без изменений. Он создаёт "путь" для градиента во время обратного распространения, что помогает избежать проблемы затухающего градиента.
Входные данные в генеративной модели — это последовательность токенов. В начале генерации текстов входным токеном часто является специальный символ <BOS> (начало последовательности), а далее модель получает собственные предсказания как вход для генерации следующего слова.
Выход декодера — это предсказанная вероятность для каждого возможного следующего токена. На каждом шаге модель использует механизм выбора на основе вероятностей, чтобы выбрать наиболее подходящий токен и продолжить генерацию текста. Для завершения последовательности генерируется специальный токен <EOS> (конец последовательности).
Основная функция потерь для генеративных моделей — это кросс-энтропия. Она измеряет расхождение между предсказанными вероятностями и реальной последовательностью слов в обучающих данных. Если модель предсказала высокую вероятность правильного следующего слова, значение функции потерь будет низким, и наоборот. Таким образом, кросс-энтропия наказывает модель за неправильные предсказания и награждает за правильные.
3 Обучение генеративных моделей
Современные большие языковые модели обучаются в два этапа: предобучение (pre-training) и постобучение (post-training). Эти этапы критически важны для формирования модели, которая способна решать широкий спектр задач.
На этапе предобучения модель обучается на большом наборе данных, содержащем тексты из разных источников (например, книги, статьи, форумы). Этот этап служит для того, чтобы модель "познакомилась" с общим языковым контекстом и приобрела способность генерировать текст, анализировать смысловые связи и понимать грамматические правила.
Этот процесс требует значительных вычислительных ресурсов и длительного времени, так как модель должна обработать гигантские объемы данных. На этапе предобучения большой языковой модели формируется базовая способность к генерации текста, но её знания остаются общими и недостаточно специализированными для конкретных задач.
После завершения этапа предобучения, на котором модель обучается на большом количестве данных из различных источников, проводится этап постобучения. Этот процесс помогает адаптировать модель к более специфическим задачам, улучшая её способность к выполнению конкретных сценариев использования.
3.1 Алгоритмы постобучения
Среди популярных алгоритмов дообучения выделяются SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback) и DPO (Direct Preference Optimization)[9].
SFT – это этап, на котором модель обучается на размеченных данных, предоставленных аннотаторами. В рамках этого подхода модели предоставляется набор входных данных и соответствующих ожидаемых ответов. SFT задаёт направление для дальнейшего дообучения, формируя первоначальное представление модели о том, как она должна отвечать на запросы.
RLHF – это один из наиболее распространённых методов дообучения. Этот процесс помогает модели улучшать свои ответы, ориентируясь на предпочтения людей. Однако у RLHF есть важный недостаток – сложность настройки алгоритмов обучения с подкреплением.
DPO – это более новый подход к дообучению языковых моделей. Основное отличие DPO заключается в том, что вместо использования сложных алгоритмов обучения с подкреплением, модель напрямую обучается оптимизировать предпочтения на основе пар сравнения различных текстов. Аннотаторы предоставляют данные в виде пар ответов, где один предпочтительнее другого, и модель обучается отдавать предпочтение лучшему ответу.
Основное преимущества DPO по сравнению с RLHF – простота в реализации. DPO проще в использовании, так как исключает сложные этапы обучения с подкреплением и напрямую работает с предпочтениями, предоставленными аннотаторами.

Рисунок 2 – Алгоритмы дообучения
3.2 LoRA
Крупные языковые модели требуют значительных ресурсов для дообучения. Одним из решений для снижения затрат на обучение является метод LoRA(Low-Rank Adaptation)[10], который позволяет эффективно адаптировать большие модели к новым задачам или предпочтениям, избегая необходимости полного переобучения.
LoRA — это метод дообучения нейронных сетей, который направлен на снижение количества параметров, необходимых для адаптации моделей к новой информации. В отличие от традиционных подходов, которые требуют обновления всех параметров модели, LoRA использует матрицы низкого ранга для того, чтобы вносить изменения только в определённые слои модели. Это достигается через добавление параметров низкой размерности, которые модифицируют уже обученные веса модели, не изменяя их напрямую.
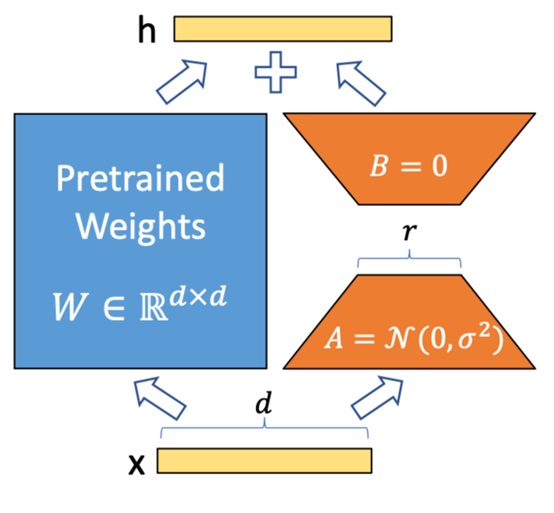
Рисунок 3 – Принцип действия LoRA
LoRA значительно снижает вычислительные затраты, так как изменяет лишь небольшое количество параметров, что ускоряет процесс обучения и делает его менее ресурсоёмким. Кроме того, этот метод требует меньше видеопамяти, что позволяет использовать его на устройствах с ограниченными ресурсами. LoRA также даёт возможность гибко адаптировать одну и ту же базовую модель под различные задачи без полного переобучения. Метод легко интегрируется с крупными моделями, такими как Llama[11].
Заключение
Прогресс в области искусственного интеллекта и генеративных нейронных сетей открыл перед разработчиками интерактивных игр новые горизонты. Эти технологии позволяют создавать динамичные и персонализированные сюжетные линии, которые адаптируются к действиям игроков, выходя за рамки традиционных игровых сценариев.
В будущем генеративные нейронные сети могут стать неотъемлемой частью игровой индустрии, предлагая игрокам уникальный опыт, где каждое действие влияет на сюжет и мир игры. Это откроет новую эпоху в создании интерактивных развлечений, где искусственный интеллект станет ключевым элементом не только в создании сюжетов.
Список источников
- Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, Ji-Rong Wen. A Survey of Large Language Models. Режим доступа: https://arxiv.org/abs/2303.18223
- OpenAI. GPT-4 Technical Report. Режим доступа: https://arxiv.org/abs/2303.08774
- Llama Team. The Llama 3 Herd of Models. Режим доступа: https://arxiv.org/abs/2407.21783
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. Режим доступа: https://arxiv.org/abs/1706.03762
- Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, Sumit Sanghai. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. Режим доступа: https://arxiv.org/abs/2305.13245
- Jimmy Lei Ba, Jamie Ryan Kiros, Geoffrey E. Hinton. Layer Normalization. Режим доступа: https://arxiv.org/abs/1607.06450
- Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy. Transformer Feed-Forward Layers Are Key-Value Memories. Режим доступа: https://arxiv.org/abs/2012.14913
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. Режим доступа: https://arxiv.org/abs/1512.03385
- Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. Режим доступа: https://arxiv.org/abs/2305.18290
- Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. Режим доступа: https://arxiv.org/abs/2106.09685
- Yuren Mao, Yuhang Ge, Yijiang Fan, Wenyi Xu, Yu Mi, Zhonghao Hu, Yunjun Gao. A Survey on LoRA of Large Language Models. Режим доступа: https://arxiv.org/pdf/2407.11046