Аннотация
Майданюк К.Д., Грищенко Д.А., Григорьев А.В. Анализ существующих методов обучения по прецедентам. В статье выполнен анализ существующих методов обучения по прецедентам, приведена классификация, достоинства и недостатки, исследованы пути их применимости.
Введение
В современном мире, где информация и знания играют ключевую роль в развитии общества и экономики, обучение по прецедентам становится все более актуальным и востребованным. Этот подход к обучению широко используется в различных областях науки и практики, таких как машинное обучение, искусственный интеллект, бизнес-аналитика и многих других.
Обучение по прецедентам (CBL) — это процесс извлечения знаний из набора данных, который содержит множество примеров или прецедентов. Целью этого процесса является создание модели, которая может обобщать и делать предсказания на основе ранее изученных примеров. Обучение по прецедентам может быть использовано для решения различных задач, таких как классификация, регрессия, кластеризация и другие [1].
Одним из основных преимуществ обучения по прецедентам является возможность работы с большими объемами данных, которые могут быть неструктурированными или слабоструктурированными. Кроме того, этот подход позволяет создавать модели, которые могут адаптироваться к новым данным и улучшать свою точность со временем.
Существует множество методов обучения по прецедентам, таких как метод ближайшего соседа, деревья решений, метод опорных векторов, байесовский метод и многие другие.
Целями статьи являются:
- изучение и критический анализ существующих методов обучения на основе прецедентов;
- обсуждение проблематики модификации и приложения методов обучения по прецедентам в программном синтезе.
1. Критический анализ существующих методов обучения на основе прецедентов
Обучение по прецедентам предполагает использование реальных ситуаций для обучения и решения проблем. Однако, данный метод, как и любой другой, имеет свои сильные и слабые стороны, которые необходимо учитывать. В данной статье проведем критический анализ наиболее популярных методов обучения на основе прецедентов, выделим их преимущества и недостатки, а также сферы применения.
1.1 Метод ближайшего соседа
Метод ближайшего соседа является одним из простейших и наиболее интуитивных методов машинного обучения. Этот метод широко используется в задачах классификации, регрессии и кластеризации, а его основным принципом является нахождение ближайшего объекта в обучающей выборке и присвоение ему соответствующего класса или значения [2].
Основным достоинством метода ближайшего соседа является его простота и эффективность при работе с небольшими наборами данных. Этот метод не требует сложных вычислений и способен быстро обрабатывать большие объемы данных. Кроме того, метод ближайшего соседа легко интерпретировать, поскольку он основан на понятии расстояния между объектами.
Однако, у метода ближайшего соседа есть и недостатки. Во-первых, он может оказаться недостаточно точным при работе с большими наборами данных, так как может не учитывать более сложные зависимости между объектами. Во-вторых, этот метод может быть чувствителен к выбросам в данных, что может привести к неправильным классификациям.
Кроме того, метод ближайшего соседа может потребовать большого количества памяти для хранения обучающей выборки, особенно если данные представлены в многомерном пространстве.
Тем не менее, метод ближайшего соседа остается популярным и широко используемым методом машинного обучения благодаря своей простоте и эффективности.
1.2 Деревья решений
Деревья решений представляют собой иерархическую структуру, состоящую из узлов и ветвей [2]. Каждый узел представляет определенное условие, а ветви – возможные исходы. Деревья решений могут использоваться для классификации и регрессии, а также для определения важности признаков. Основным недостатком этого метода является то, что деревья решений могут быть слишком сложными и трудными для интерпретации.
Метод “деревья решений” является одним из популярных методов машинного обучения. Он используется для решения различных задач, таких как классификация данных, прогнозирование значений и т.д. Этот метод основывается на построении дерева решений, которое состоит из узлов и ветвей.
К достоинствам метода “деревья решений” можно отнести его простоту, наглядность, возможность работы с большим количеством данных и отсутствие необходимости в предварительной обработке данных. Также, этот метод позволяет получить результаты в виде простых правил, которые легко интерпретировать,
Однако, у данного метода есть и недостатки. Например, деревья могут быть сложными и трудными для интерпретации, особенно если они имеют много уровней и ветвей. Также, деревья решений могут быть подвержены переоснащению - когда они начинают давать слишком много мелких деталей, которые могут не иметь отношения к решаемой проблеме.
Кроме того, точность метода может быть не очень высокой, особенно если данные зашумлены или содержат много выбросов. В таких случаях может потребоваться дополнительная обработка данных или применение других методов машинного обучения.
1.3 Метод опорных векторов
Метод опорных векторов использует гиперплоскости для разделения данных на классы.
Метод опорных векторов (Support Vector Machines, SVM) — это мощный инструмент машинного обучения, используемый для решения задач классификации и регрессии. Он основан на идее разделения данных на классы с помощью гиперплоскости, которая проходит через опорные векторы — точки, наиболее удаленные от гиперплоскости.
SVM позволяет создавать модели, способные точно классифицировать новые данные, даже если они не были включены в обучающую выборку. Это достигается за счет использования опорных векторов, которые помогают определить оптимальное расстояние между классами и обеспечивают более точное разделение данных.
Применение SVM может быть эффективным в различных областях, включая распознавание образов, компьютерное зрение, обработку естественного языка и многие другие. Однако стоит отметить, что использование этого метода требует определенных знаний и навыков, а также может быть ресурсоемким в зависимости от размера и сложности данных.
Достоинства:
- точность классификации — SVM обеспечивает высокую точность классификации благодаря использованию гиперплоскости, которая разделяет данные на два класса;
- многообразие решений — SVM позволяет создавать различные виды классификаторов, такие как линейные и нелинейные, что делает его гибким и адаптивным;
- нечувствительность к выбросам — благодаря использованию ядер, SVM является устойчивым к выбросам в данных, что позволяет использовать его в сложных и зашумленных наборах данных.
Недостатки:
- сложность вычислений — SVM может требовать значительных вычислительных ресурсов при работе с большими наборами данных или при использовании сложных моделей;
- выбор гиперпараметров — для эффективной работы SVM необходимо правильно выбрать его гиперпараметры, такие как ядра, коэффициенты регуляризации и т.д. Это может быть сложной задачей и требовать много времени;
- ограничения на форму данных — SVM лучше всего работает с линейно разделимыми данными, т.е. когда данные можно разделить на два четко определенных класса с помощью прямой линии. Если данные не линейно разделимы, то SVM может давать неточные результаты.
В целом, метод опорных векторов является мощным инструментом для решения разнообразных задач машинного обучения. Однако, для его успешного применения необходимо понимать его особенности и ограничения, а также уметь настраивать его гиперпараметры для достижения наилучших результатов [2].
1.4 Байесовский метод
Байесовский метод основан на использовании функций правдоподобия и априорных распределений для оценки параметров модели. Этот метод может быть использован для решения различных задач, включая классификацию, регрессию и оценку параметров моделей.
Байесовский метод является важным инструментом в статистике и вероятностном выводе, который позволяет обновлять наши знания и делать выводы на основе доступных данных [3].
Достоинства:
- интуитивность — байесовский метод основан на теореме Байеса, которая выражает вероятность события через вероятности других событий, связанных с ним, это делает метод интуитивно понятным и облегчает его применение;
- учет неопределенности — байесовский метод позволяет учитывать неопределенность в наших знаниях и обновлять их на основе новых данных, это особенно полезно в ситуациях, когда данные ограничены или имеют высокую степень неопределенности;
- возможность использования различных видов данных — байесовский метод может использоваться с различными типами данных, включая категориальные, порядковые и непрерывные. Это позволяет применять его в широком спектре задач.
Недостатки:
- необходимость априорных распределений — байесовский метод требует наличия априорного распределения, которое отражает наши знания до получения данных, выбор правильного априорного распределения может быть сложным и субъективным процессом;
- вычислительные сложности — байесовские методы могут быть сложными для реализации и требуют значительных вычислительных мощностей для обработки больших объемов данных;
- ограничения на модели — байесовский метод ограничен определенными типами моделей, такими как скрытые марковские модели и байесовские сети. Это может ограничивать его применимость в некоторых задачах.
Байесовский метод представляет собой мощный инструмент для анализа данных и принятия решений в условиях неопределенности, но его использование требует тщательного понимания его преимуществ и недостатков, а также навыков в выборе априорных распределений и обработке данных.
2. Проблематика модификации и применения методов обучения по прецедентам в программном синтезе
В данном разделе рассмотрим проблематику модификации и применения обучения по прецедентам в программном синтезе. В частности, обсудим различные аспекты модификации данного метода для повышения его эффективности и качества решений, а также проанализируем ограничения и потенциальные проблемы, связанные с использованием CBL в программных системах.
2.1 Сложности при автоматической генерации кода программ с помощью методов обучения по прецедентам
Применение обучения по прецедентам в программном синтезе имеет свою специфику. Во-первых, необходимо определить набор прецедентов-примеров успешно реализованных проектов, которые могут быть использованы для создания нового ПО. Во-вторых, необходимо провести анализ этих прецедентов для выявления общих закономерностей и принципов, которые могут быть применены в новом проекте. В-третьих, необходимо разработать алгоритмы и инструменты, которые позволят автоматизировать процесс обучения на прецедентах и использовать полученные знания для создания нового программного продукта.
Обучение по прецедентам применяется в различных сферах:
- в медицине — обучение по прецедентам используется для диагностики заболеваний и прогнозирования их развития, примером может служить исследование, проведенное в 2017 году, в котором CBL использовался для диагностики рака груди на основе анализа медицинских изображений;
- в экономике — CBL применяется для прогнозирования рынка и анализа финансовых трендов, в частности, данный метод используется в моделях финансового прогнозирования, основанных на анализе исторических данных о ценах на активы;
- в сфере образования — CBL помогает создавать адаптивные обучающие системы, которые подбирают индивидуальный подход к каждому учащемуся на основе его прошлых результатов.
Генерация кода программы является одной из ключевых задач в процессе разработки программного обеспечения. Традиционные методы генерации кода предполагают написание кода вручную или использование специализированных инструментов для автоматического создания кода. С появлением машинного обучения и искусственного интеллекта, стали разрабатываться новые подходы к генерации кода, которые позволяют автоматизировать этот процесс и повысить его эффективность. Однако, не все САПР имеют достаточный уровень автоматизации генерации программ [4].
Одним из методов автоматической генерации кода является обучение по прецедентам. В работе [5] предлагается обучать базу знаний с помощью САПР, которая может предоставить совокупность апробированных решений, представленных в виде текстов. Этот метод заключается в анализе набора данных и выявлении закономерностей, которые можно использовать для предсказания результатов в новых ситуациях; система анализирует уже существующие решения и на основе этого анализа создает новый код.
Существует несколько способов модификации обучения по прецедентам. Один из способов — использование дополнительных источников информации. Это может быть генетическая информация для медицинской диагностики, внешние факторы для финансового прогнозирования или индивидуальные предпочтения учеников для обучения. Также можно использовать метод обучения по прецедентам для оптимизации результатов, полученных после применения данного метода. Алгоритмы машинного обучения позволяют извлекать дополнительные знания и повышать точность результатов. Кроме того, можно создавать более гибкие и адаптивные системы на основе CBL. Это может включать в себя адаптивное обучение, которое подстраивается под индивидуальные потребности и предпочтения учащихся.
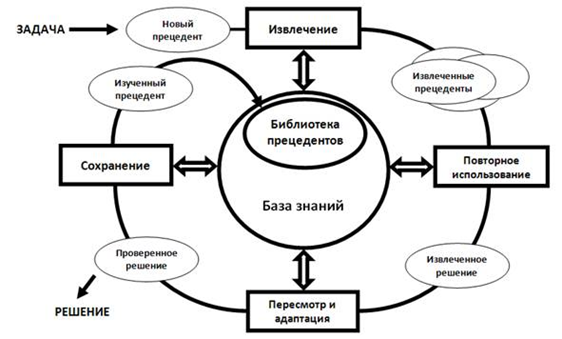
Рисунок 1 – Алгоритм работы обучения по прецедентам
Использование автоматической генерации кода имеет ряд преимуществ. Это позволяет ускорить процесс разработки программного обеспечения, так как не требуется писать код вручную; автоматический генератор кода может создавать более качественный код, так как он может учитывать множество факторов, которые могут быть не учтены человеком; автоматический генератор кода позволяет создавать более гибкие и адаптивные системы, которые могут изменять свой код в зависимости от изменений в требованиях или условиях работы.
Однако при использовании обучения по прецедентам для генерации кода могут возникнуть некоторые проблемы: необходимость большого количества данных для обучения модели, сложность интерпретации результатов обучения, так как они могут быть неоднозначными, также обучение по прецедентам может не учитывать все возможные варианты кода, что может привести к неправильным результатам. Одной из главных проблем является сложность описания алгоритма на естественном языке, которое может быть неоднозначным или трудным для понимания искусственным интеллектом.
Чтобы решить эти проблемы, можно использовать различные методы, такие как улучшение качества данных для обучения, использование различных моделей машинного обучения и анализ результатов обучения. Также можно использовать дополнительные методы, такие как анализ кода на основе правил или использование нейронных сетей для генерации кода.
Заключение
В данной статье были рассмотрены основные методы машинного обучения, включая метод ближайшего соседа, деревья решений, метод опорных векторов и байесовский метод. Каждый из этих методов имеет свои преимущества и недостатки, и выбор конкретного метода зависит от конкретной задачи и доступных данных.
Рассмотрены сложности при автоматической генерации кода программ с помощью методов обучения по прецедентам, предложены способы их преодоления.
Стоит отметить, что обучение по прецедентам имеет потенциал для развития. Например, данный метод может использоваться совместно с другими технологиями искусственного интеллекта, что позволит улучшить производительность и точность решений, принимаемых на основе прошлого опыта. CBL может использоваться в новых сферах, таких как автономные системы и робототехника. Это открывает новые возможности для применения данного метода.
Список использованной литературы
1. Реализация прецедентного модуля для интеллектуальных систем [электронный ресурс]. – Режим доступа: https://cyberleninka.ru/article/n/realizatsiya-pretsedentnogo-modulya-dlya-intellektualnyh-sistem
2. Воронцов, К.В. Вычислительные методы обучения по прецедентам [электронный ресурс] / К.В. Воронцов. – Режим доступа: http://www.ccas.ru/voron/download/Introduction.pdf
3. Ветров, Д.П. Байесовские методы машинного обучения: учебное пособие / Д.П. Ветров, Д.А. Кропотов. – Москва: [б. и.], 2007. – 67 с.
4. Григорьев А.В., Грищенко Д.А. Классификация источников знаний о методиках проектирования VHDL-программ в инструментальной оболочке по созданию интеллектуальных САПР в режиме «глупого» эксперта // Моделирование и компьютерная графика: Материалы 4-й международной научно-технической конференции, г. Донецк, 5-8 октября 2011 г. — Донецк, ДонНТУ, Министерство науки и образования, молодёжи и спорта, 2011. – С. 67-73.
5. Григорьев А.В., Кошелева Д.А. Интеллектуализация процесса проектирования аппаратуры средствами языка VHDL /Научные труды национального технического университета. Серия: Информатика, кибернетика и вычислительная техника (ИКВТ-2005), выпуск 93: – Донецк: ДонНТУ, 2005. – С. 182-188.