
Реферат по теме выпускной работы
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: июнь 2025 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Исследование алгоритма создания Deepfake
- 4. Обзор существующих архитектур нейронных сетей
- 4.1 Сверточные нейронные сети
- 4.2 Генеративные состязательные сети
- Выводы и дальнейшие задачи исследования
- Список источников
Введение
Технология DeepFake использует искусственный интеллект для создания фальшивых видео или аудиозаписей, где лица или голоса заменяются другими. Это достигается путем обучения моделей глубокого обучения на большом объеме данных, чтобы они могли реалистично симулировать желаемые характеристики. DeepFake может использоваться как в развлекательных целях, так и для злоупотребления, создавая потенциальные проблемы в сфере доверия и подлинности медиаконтента.
DeepFake-технологии могут использовать различные библиотеки глубокого обучения. Некоторые из них включают TensorFlow, PyTorch, Keras и др. [1] Эти библиотеки предоставляют инструменты для создания и обучения глубоких нейронных сетей, которые являются основой для алгоритмов DeepFake. Помимо этого, в основе также лежат генеративные состязательные сети и сверточные нейронные сети. [2]
Важно отметить, что использование DeepFake-технологии сопровождается рядом этических и юридических вопросов, так как она может быть использована для создания манипулятивного контента.
1. Актуальность темы
Технология DeepFake представляет собой метод создания фальшивых видео- и аудиоматериалов, где искусственные нейронные сети и глубокие модели обучаются имитировать лица и голоса людей с удивительной реалистичностью. Эта технология стала предметом широкого внимания и вызвала разнообразные обсуждения из-за своих потенциальных негативных последствий и вызовов в различных областях.
DeepFake представляет потенциальную угрозу для достоверности информации. Способность создавать реалистичные фальшивые видео и аудио может быть использована для распространения дезинформации, манипуляции общественным мнением и даже участия в кибератаках.
Также DeepFake может быть использован для создания фальшивых видео с участием политических лидеров или общественных деятелей, что может повлечь за собой политическую нестабильность и доверие к власти.
Таким образом, общественные, политические и технологические аспекты технологии DeepFake делают ее актуальной темой для исследований и разработок в области искусственного интеллекта и кибербезопасности.
2. Цель и задачи исследования, планируемые результаты
Целью исследования является разработка и усовершенствование алгоритмов и методов для обнаружения и противодействия технологии DeepFake, направленных на повышение точности и эффективности выявления фальшивого медиаконтента, а также исследование этических и юридических аспектов использования данной технологии.
Основные задачи исследования:
- Анализ существующих методов и алгоритмов создания и обнаружения DeepFake, их преимуществ и недостатков.
- Исследование и разработка новых алгоритмов для обнаружения фальшивого контента, основанных на современных архитектурах нейронных сетей (сверточные нейронные сети, генеративные состязательные сети).
- Оценка эффективности различных методов обнаружения DeepFake на различных типах фальшивого контента (видео, аудио, изображения).
- Разработка рекомендаций по этическому использованию технологии DeepFake и защите личной информации от злоупотреблений.
- Исследование возможности обнаружения DeepFake в реальном времени и разработка инструментов для оперативного выявления фальшивого контента.
Объект исследования: технология DeepFake, включая методы создания, обнаружения и противодействия фальшивому медиаконтенту.
Предмет исследования: алгоритмы и методы обнаружения и противодействия DeepFake, их эффективность и применимость в различных условиях. .
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Разработка нового подхода к обнаружению DeepFake, основанного на современных архитектурах нейронных сетей и методах машинного обучения.
- Создание инструментария для автоматизированного обнаружения и анализа фальшивого контента
- Разработка рекомендаций по этическому использованию технологии DeepFake и защите личной информации.
- Оценка эффективности разработанных методов на различных типах фальшивого контента и в различных сферах применения.
Эти цели и задачи направлены на решение актуальных проблем, связанных с технологией DeepFake, и разработку инструментов для повышения доверия к медиаконтенту в цифровую эпоху.
3. Исследование алгоритма создания Deepfake
Сначала собираются большие объемы данных, включая видео или фотографии с целевыми объектами (лицами), которые будут использоваться для обучения модели. На этом этапе создается модель, которая учится извлекать характеристики лица из фотографий и видео. Эта модель может быть базирована на глубоких нейронных сетях, таких как сверточные нейронные сети (англ. Convolutional Neural Network, CNN) [2]. Происходит обучение на большом объеме данных, содержащем фотографии лиц. Цель состоит в том, чтобы модель научилась выделять уникальные характеристики, которые описывают лицо, независимо от освещения, угла съемки и других факторов.
После завершения обучения модель может принимать фотографии лиц в качестве входных данных и генерировать векторы (эмбеддинги), представляющие характеристики этих лиц в абстрактном пространстве. Векторы, полученные от кодировщика, должны быть организованы таким образом, чтобы лица, которые визуально схожи между собой, имели близкие векторные представления.
Далее следует проверка качества эмбеддингов с использованием метрик подобия лиц. Метриками могут выступать косинусное расстояние или эвклидово расстояние – они позволят определить, насколько близки векторы друг к другу в пространстве. Меры близости позволяют оценить степень сходства между эмбеддингами. Это помогает гарантировать, что векторы, созданные кодировщиком, хорошо представляют собой лицо и будут полезны для последующих этапов, таких как создание генератором поддельных изображений.
Затем происходит обучение генератора и дискриминатора, в основе которых лежит сверточная нейронная сеть. Генератор отвечает за создание поддельных данных, а дискриминатор – за распознавание реальных и поддельных данных. Совокупность генератора и дискриминатора представляет собой генеративную состязательную сеть (англ. Generative adversarial network, GAN). Следующий этап – объединение с оригинальным контентом: синтезированные лица вставляются в оригинальное видео, создавая впечатление, что целевое лицо находится в новом контексте. Дополнительные шаги могут включать в себя тонкую настройку параметров, чтобы улучшить реализм и качество сгенерированных видеозаписей.
4. Обзор существующих архитектур нейронных сетей
4.1 Сверточные нейронные сети
Сверточные нейронные сети представляют собой класс глубоких нейронных сетей, специально разработанный для обработки визуальных данных, таких как изображения и видео. Они успешно применяются в задачах распознавания образов, классификации изображений, обнаружения объектов, сегментации и других видов анализа визуальной информации. На рисунке 1 изображена архитектура сверточной нейронной сети в общем виде [3].
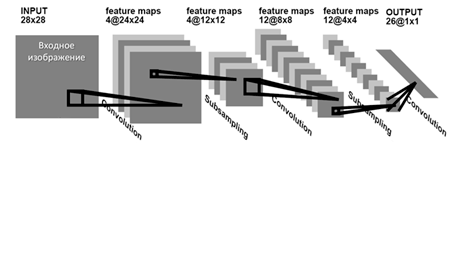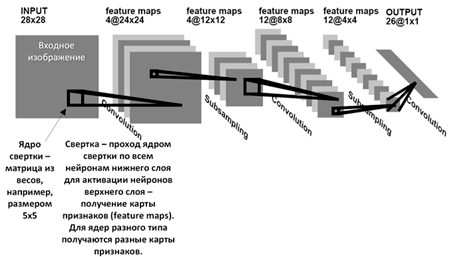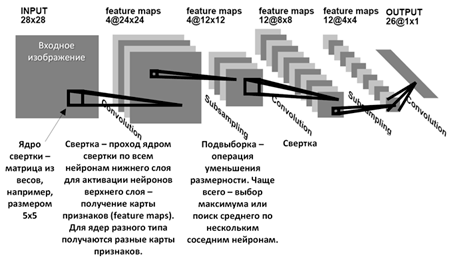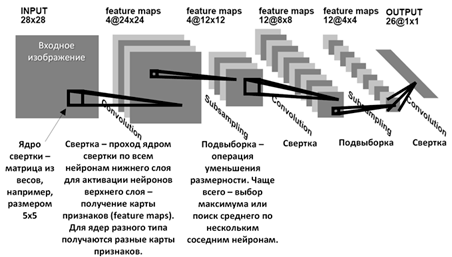
Рисунок 1 – Архитектура сверточной нейронной сети
(анимация: 7 кадров, 10 циклов повторения, 32,8 килобайт)
Основной строительный блок CNN - сверточный слой. В нем применяются операции свертки для извлечения локальных признаков из входных данных. Свёртка — это операция, при которой ядро (фильтр) проходит по входным данным, вычисляя взвешенную сумму значений. Это позволяет нейронной сети выделять различные аспекты изображений, такие как грани, углы, текстуры. Принцип работы сверточного слоя показан на рисунке 2 [3].
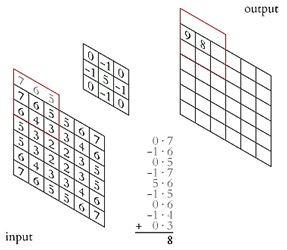
Рисунок 2 – Принцип работы сверточного слоя
После сверточных слоев обычно следуют слои подвыборки или пулинга. Пулинг используется для уменьшения пространственного разрешения данных, уменьшая их размер, но сохраняя ключевые признаки. Самый распространенный вид пулинга - максимальный пулинг, где из каждой подгруппы данных выбирается максимальное значение. После нескольких сверточных и пулинговых слоев обычно следуют полносвязные (с англ. Fully Connected Layers) слои. Эти слои соединяют все активации предыдущего слоя с каждым нейроном текущего слоя, помогая собрать в более высокоуровневые признаки.
Между слоями обычно используются функции активации, такие как усеченная линейная функция (англ. Rectified Linear Unit, ReLU), для внесения нелинейности в модель и улучшения её способности к обучению сложных зависимостей.
Обучение CNN включает в себя подстройку весов в процессе обратного распространения ошибки (англ. backpropagation). Оптимизаторы, такие как стохастический градиентный спуск или его модификации, применяются для минимизации функции потерь.
4.2 Генеративные состязательные сети
Генеративные состязательные сети (GAN) состоят из двух основных компонентов: генератора и дискриминатора.
Генератор создает новые данные (например, изображения) из случайного шума или другого входного пространства. Он обычно представляет собой нейронную сеть, которая принимает на вход случайный шум или вектор из некоторого пространства и генерирует изображение или данные. Генератор стремится минимизировать различие между созданными данными и реальными данными из обучающего набора. На рисунках 3 и 4 изображен пример генерации изображений из шума [4].

Рисунок 3 – Генерация изображения из шума (часть 1)

Рисунок 4 – Генерация изображения из шума (часть 2)
Дискриминатор также представляет собой нейронную сеть, которая принимает на вход данные (реальные или созданные генератором) и выдает вероятность того, что входные данные являются реальными [5]. Он стремится максимизировать различие между вероятностью реальных и поддельных данных. Для оценки работы генератора и дискриминатора обычно используются функции потерь, такие как среднеквадратическая ошибка или бинарная кросс-энтропия.
Среднеквадратическая ошибка (Mean Squared Error, MSE) определяется как среднее квадрата разности между фактическим и прогнозируемым значениями. За счет возведения в квадрат значения потери функция наказывает модель за большие ошибки. Таким образом, значения признака можно исключить из модели, так как это может быть шумом или выбросом. Поэтому для функции важно минимизировать выбросы, если это возможно; в противном случае функция не рекомендуется для применения [6].
Бинарная кросс-энтропия (Binary Crossentropy) основывается на предсказании вероятности принадлежности объекта к каждому из классов. В идеале, если объект принадлежит к первому классу, то вероятность принадлежности к нему должна быть близка к 1, а вероятность принадлежности ко второму классу — близка к 0. В случае, если предсказанные вероятности не соответствуют идеальному распределению, будут вычислены значения кросс-энтропии [6, 7]. Для работы с классификацией, где количество классов больше 2, используется кросс-энтропия, но с добавлением логарифмов. [8]
Весь процесс обучения включает в себя взаимодействие между генератором и дискриминатором: генератор стремится создавать данные, которые дискриминатор не может отличить от реальных, в то время как дискриминатор старается улучшить распознавание реальных и поддельных данных. Обучение является итеративным, поскольку в зависимости от результатов оценки веса генератора и дискриминатора обновляются, чтобы улучшить их производительность. Этот процесс повторяется многократно до тех пор, пока генератор не станет создавать данные, которые трудно отличить от реальных дискриминатору. Таким образом, генеративная состязательная сеть достигает равновесия между генератором и дискриминатором, создавая поддельные данные, которые практически неотличимы от реальных.
Выводы и дальнейшие задачи исследования
Исследование можно продолжить в нескольких вариантах:
- продолжение изучения существующих методов обнаружения DeepFake и их ограничений.
- разработка новых алгоритмов и техник для обнаружения фальшивого контента;
- оценка эффективности различных методов на различных типах DeepFake;
- исследование методов создания более устойчивых систем:
- анализ причин и особенностей успешности DeepFake.
- разработка методов, способных сделать модели менее уязвимыми к обнаружению.
- исследование этических аспектов использования и борьбы с DeepFake.
- разработка рекомендаций для этического использования технологии и защиты личной жизни.
Применение методов в реальном времени:
- исследование возможности обнаружения DeepFake в реальном времени.
- исследование влияния DeepFake в различных областях, таких как политика, бизнес, искусство и т.д.;
- совершенствование инструментов для выявления и предотвращения использования DeepFake в различных сферах; создание открытых баз данных и метрик.
В дальнейшем предстоит выбрать одну из тем выше для совершенствования, определить её недостатки и найти возможные способы их устранения. После чего, с учётом недостатков и достоинств выбранной технологии, необходимо будет составить требования к разрабатываемой (совершенствуемой) технологии сглаживания и приступать к её реализации в качестве «пакета» для Unity с целью определения её характеристик и оценки эффективности выполненных усовершенствований.
Таким образом, в процессе работы обоснована актуальность выбранной темы магистерской диссертации. Были изучены основные технологии и архитектуры (сверточные нейронные сети, генеративные соревновательные сети), а также метрики для оценки работы. Проанализированы их особенности, преимущества и недостатки. Определены цели и задачи дальнейших исследований.
Список источников
- Обзор технологий создания DeepFake и методов его выявления [Электронный ресурс] – Режим доступа: https://rdc.grfc.ru/2020/06/ research-DeepFake/
- Сверточные нейросети: что это и для чего они нужны? [Электронный ресурс] – Режим доступа: https://forklog.com/cryptorium/ai/svertochnye-nejroseti-chto-eto-i-dlya-chego-oni-nuzhny
- Сверточная нейронная сеть [Электронный ресурс] – Режим доступа: https://ru.wikipedia.org/wiki/Свёрточная_нейронная_сеть
- Что такое GAN – генеративно-состязательные нейронные сети и как их применять для генерации изображений [Электронный ресурс] – Режим доступа: https://evergreens.com.ua/ru/articles/gan.html
- Малахов Ю.А. Анализ и применение генеративно-состязательных сетей для получения изображений высокого качества / А. Ю. Малахов, А.А. Андросов, А.В. Аверченков // Эргодизайн. 2020. №4 (10).
- Функции потерь (Loss Function) для алгоритмов машинного обучения [Электронный ресурс] – Режим доступа: https://aipavlov.com/articles/funkcii-poter-mashinnoe-obechenie/
- Клевцов Д.В. Перспективы использования нейронных сетей в современной экономике // Международный журнал прикладных наук и технологий «Integral», 2019, №1.
- Поляков С. Глубокое обучение. Погружение в мир нейронных сетей. – М.: Питер, 2021.