
Thesis on the topic of the graduation work
At the time of writing this thesis, the master's work is not yet completed. Final completion: June 2025. The full text of the work and materials on the topic can be obtained from the author or his supervisor after the specified date.
Contents
- Introduction
- 1. Relevance of the topic
- 2. Purpose and objectives of the research, planned results
- 3. Research of the Deepfake creation algorithm
- 4. Overview of existing neural network architectures
- 4.1 Convolutional Neural Networks
- 4.2 Generative Adversarial Networks
- Conclusions and further research tasks
- List of sources
Introduction
DeepFake technology uses artificial intelligence to create fake videos or audio recordings where faces or voices are replaced with others. This is achieved by training deep learning models on a large amount of data so that they can realistically simulate the desired characteristics. DeepFake can be used for entertainment purposes as well as for abuse, creating potential problems in the field of trust and authenticity of media content.
DeepFake technologies can use various deep learning libraries. Some of them include TensorFlow, PyTorch, Keras, etc. [1] These libraries provide tools for creating and training deep neural networks, which are the basis for DeepFake algorithms. In addition, generative adversarial networks and convolutional neural networks are also at the core.
It is important to note that the use of DeepFake technology is accompanied by a number of ethical and legal issues, as it can be used to create manipulative content.
1. Relevance of the topic
DeepFake technology is a method of creating fake video and audio materials where artificial neural networks and deep models are trained to mimic people's faces and voices with astonishing realism. This technology has become the subject of widespread attention and has sparked various discussions due to its potential negative consequences and challenges in various fields.
DeepFake poses a potential threat to the reliability of information. The ability to create realistic fake videos and audio can be used to spread misinformation, manipulate public opinion, and even participate in cyberattacks.
DeepFake can also be used to create fake videos featuring political leaders or public figures, which can lead to political instability and a loss of trust in authority.
Thus, the social, political, and technological aspects of DeepFake technology make it a relevant topic for research and development in the field of artificial intelligence and cybersecurity.
2. Purpose and objectives of the research, planned results
The purpose of the research is to develop and improve algorithms and methods for detecting and countering DeepFake technology, aimed at increasing the accuracy and efficiency of identifying fake media content, as well as to study the ethical and legal aspects of using this technology.
Main research objectives:
- Analysis of existing methods and algorithms for creating and detecting DeepFake, their advantages and disadvantages.
- Research and development of new algorithms for detecting fake content based on modern neural network architectures (convolutional neural networks, generative adversarial networks).
- Evaluation of the effectiveness of various DeepFake detection methods on different types of fake content (video, audio, images).
- Development of recommendations for the ethical use of DeepFake technology and protection of personal information from abuse.
- Research on the possibility of real-time DeepFake detection and development of tools for operational identification of fake content.
Object of research: DeepFake technology, including methods of creation, detection, and counteraction to fake media content.
Subject of research: algorithms and methods for detecting and countering DeepFake, their effectiveness and applicability in various conditions. .
Within the framework of the master's work, it is planned to obtain relevant scientific results in the following areas:
- Development of a new approach to DeepFake detection based on modern neural network architectures and machine learning methods.
- Creation of tools for automated detection and analysis of fake content
- Development of recommendations for the ethical use of DeepFake technology and protection of personal information.
- Evaluation of the effectiveness of the developed methods on various types of fake content and in various application areas.
These goals and objectives are aimed at solving current problems related to DeepFake technology and developing tools to increase trust in media content in the digital age.
3. Research of the Deepfake creation algorithm
First, large amounts of data are collected, including videos or photographs with target objects (faces) that will be used to train the model. At this stage, a model is created that learns to extract facial features from photographs and videos. This model can be based on deep neural networks, such as convolutional neural networks (CNN) [2]. Training is performed on a large amount of data containing facial photographs. The goal is for the model to learn to extract unique characteristics that describe the face, regardless of lighting, shooting angle, and other factors.
After training is completed, the model can take facial photographs as input and generate vectors (embeddings) representing the characteristics of these faces in an abstract space. The vectors obtained from the encoder should be organized in such a way that visually similar faces have close vector representations.
Next, the quality of the embeddings is checked using facial similarity metrics. Metrics can include cosine distance or Euclidean distance – they allow determining how close the vectors are to each other in space. Similarity measures allow assessing the degree of similarity between embeddings. This helps ensure that the vectors created by the encoder well represent the face and will be useful for subsequent stages, such as creating fake images by the generator.
Then, the generator and discriminator are trained, which are based on a convolutional neural network. The generator is responsible for creating fake data, and the discriminator is responsible for recognizing real and fake data. The combination of the generator and discriminator represents a generative adversarial network (GAN). The next stage is integration with the original content: synthesized faces are inserted into the original video, creating the impression that the target face is in a new context. Additional steps may include fine-tuning parameters to improve the realism and quality of the generated video recordings.
4. Overview of existing neural network architectures
4.1 Convolutional Neural Networks
Convolutional neural networks are a class of deep neural networks specifically designed for processing visual data, such as images and videos. They are successfully used in tasks of pattern recognition, image classification, object detection, segmentation, and other types of visual information analysis. Figure 1 shows the architecture of a convolutional neural network in general form [3].
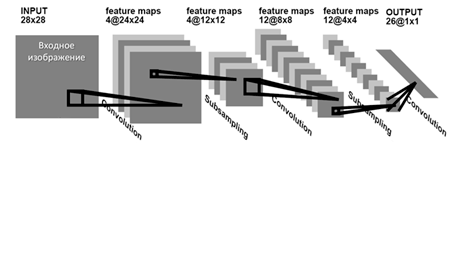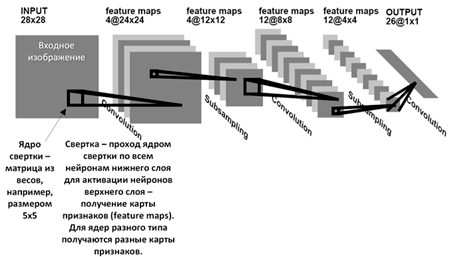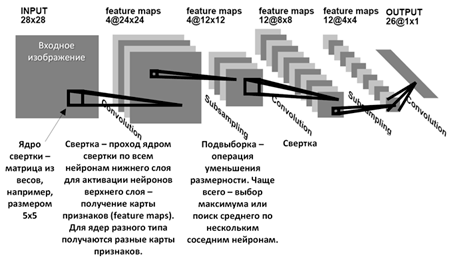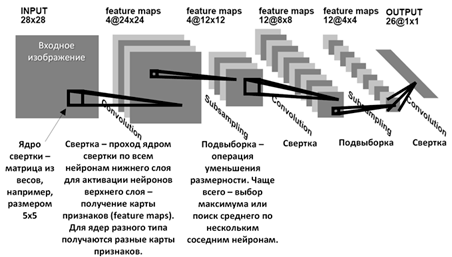
Figure 1 – Architecture of a convolutional neural network
(animation: 7 frames, 10 cycles, 32.8 kilobytes)
The main building block of CNN is the convolutional layer. It applies convolution operations to extract local features from the input data. Convolution is an operation where a kernel (filter) passes over the input data, calculating a weighted sum of values. This allows the neural network to highlight various aspects of images, such as edges, corners, textures. The principle of operation of the convolutional layer is shown in Figure 2 [3].
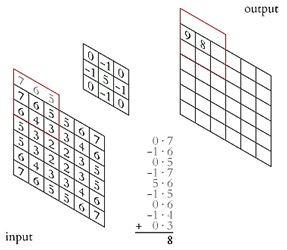
Figure 2 – Principle of operation of the convolutional layer
After convolutional layers, pooling or subsampling layers usually follow. Pooling is used to reduce the spatial resolution of the data, reducing their size but preserving key features. The most common type of pooling is max pooling, where the maximum value is selected from each subgroup of data. After several convolutional and pooling layers, fully connected layers usually follow. These layers connect all activations of the previous layer with each neuron of the current layer, helping to assemble higher-level features.
Activation functions, such as the Rectified Linear Unit (ReLU), are usually used between layers to introduce non-linearity into the model and improve its ability to learn complex dependencies.
Training CNN involves adjusting weights during backpropagation. Optimizers such as stochastic gradient descent or its modifications are used to minimize the loss function.
4.2 Generative Adversarial Networks
Generative adversarial networks (GAN) consist of two main components: a generator and a discriminator.
The generator creates new data (e.g., images) from random noise or another input space. It is usually a neural network that takes random noise or a vector from some space as input and generates an image or data. The generator aims to minimize the difference between the created data and real data from the training set. Figures 3 and 4 show an example of image generation from noise [4].

Figure 3 – Image generation from noise (part 1)

Figure 4 – Image generation from noise (part 2)
The discriminator is also a neural network that takes data (real or created by the generator) as input and outputs the probability that the input data is real [5]. It aims to maximize the difference between the probability of real and fake data. To evaluate the performance of the generator and discriminator, loss functions such as mean squared error or binary cross-entropy are usually used.
Mean Squared Error (MSE) is defined as the average of the squared difference between the actual and predicted values. By squaring the loss value, the function penalizes the model for large errors. Thus, feature values can be excluded from the model, as they may be noise or outliers. Therefore, it is important for the function to minimize outliers if possible; otherwise, the function is not recommended for use [6].
Binary Crossentropy is based on predicting the probability of an object belonging to each of the classes. Ideally, if an object belongs to the first class, the probability of belonging to it should be close to 1, and the probability of belonging to the second class should be close to 0. If the predicted probabilities do not match the ideal distribution, cross-entropy values will be calculated [6, 7]. For classification tasks where the number of classes is greater than 2, cross-entropy is used, but with the addition of logarithms.
The entire training process involves interaction between the generator and discriminator: the generator strives to create data that the discriminator cannot distinguish from real data, while the discriminator tries to improve the recognition of real and fake data. Training is iterative, as depending on the evaluation results, the weights of the generator and discriminator are updated to improve their performance. This process is repeated multiple times until the generator creates data that is difficult for the discriminator to distinguish from real data. Thus, the generative adversarial network achieves a balance between the generator and discriminator, creating fake data that is practically indistinguishable from real data.
Conclusions and further research tasks
The research can be continued in several ways:
- continuation of the study of existing DeepFake detection methods and their limitations.
- development of new algorithms and techniques for detecting fake content;
- evaluation of the effectiveness of various methods on different types of DeepFake;
- research on methods for creating more robust systems:
- analysis of the causes and features of the success of DeepFake.
- development of methods that can make models less vulnerable to detection.
- research on the ethical aspects of using and combating DeepFake.
- development of recommendations for the ethical use of technology and protection of privacy.
Application of methods in real-time:
- research on the possibility of real-time DeepFake detection.
- research on the impact of DeepFake in various fields, such as politics, business, art, etc.;
- improvement of tools for identifying and preventing the use of DeepFake in various areas; creation of open databases and metrics.
In the future, it will be necessary to choose one of the above topics for improvement, identify its shortcomings, and find possible ways to eliminate them. After that, taking into account the shortcomings and advantages of the chosen technology, it will be necessary to formulate requirements for the developed (improved) smoothing technology and proceed to its implementation as a "package" for Unity in order to determine its characteristics and evaluate the effectiveness of the improvements made.
Thus, in the course of the work, the relevance of the chosen topic of the master's thesis has been substantiated. The main technologies and architectures (convolutional neural networks, generative adversarial networks), as well as metrics for evaluating performance, have been studied. Their features, advantages, and disadvantages have been analyzed. The goals and objectives of further research have been determined.
List of sources
- Overview of DeepFake creation technologies and methods for its detection [Electronic resource] – Access mode: https://rdc.grfc.ru/2020/06/ research-DeepFake/
- Convolutional neural networks: what are they and what are they for? [Electronic resource] – Access mode: https://forklog.com/cryptorium/ai/svertochnye-nejroseti-chto-eto-i-dlya-chego-oni-nuzhny
- Convolutional neural network [Electronic resource] – Access mode: https://ru.wikipedia.org/wiki/Свёрточная_нейронная_сеть
- What is GAN – generative adversarial neural networks and how to use them for image generation [Electronic resource] – Access mode: https://evergreens.com.ua/ru/articles/gan.html
- Malakhov Yu.A. Analysis and application of generative adversarial networks for obtaining high-quality images / A. Yu. Malakhov, A.A. Androsov, A.V. Averchenkov // Ergodesign. 2020. №4 (10).
- Loss functions for machine learning algorithms [Electronic resource] – Access mode: https://aipavlov.com/articles/funkcii-poter-mashinnoe-obechenie/
- Klevtsov D.V. Prospects for the use of neural networks in the modern economy // International Journal of Applied Sciences and Technologies "Integral", 2019, №1.