|
Шади Абу Рок | |
| Специальность: | "Программное обеcпечение автоматизированных систем" | |
| Тема магистерской работы: | "Исследование свойств поисковых систем" | |
| Научный руководитель: | Костин Валерий Иванович | |
| E-mail: | shadiruck@mail.ru | |
| |
Автореферат выпускной магистерской работы"Исследование свойств поисковых систем"Содержание ВведениеОдним из основных способов найти информацию в Internet являются поисковые машины. Поисковые машины каждый день "ползают" по Сети: они посещают веб-страницы и заносят их в гигантские базы данных. Это позволяет пользователю набрать некоторые ключевые слова, нажать "submit" и увидеть, какие страницы удовлетворяют его запросу. Понимание того как работают поисковые машины просто необходимо вебмастерам. Для них жизненно важна правильная с точки зрения поисковых машин структура документов и всего сервера или сайта. Без этого документы будут недостаточно часто появляться в ответ на запросы пользователей к поисковой машине или даже вовсе могут быть не проиндексированы. Вебмастера желают повысить рейтинг своих страниц и это понятно: ведь на любой запрос к поисковой машине могут быть выданы сотни и тысячи отвечающих ему ссылок на документы. В большинстве случаев только 10 первых ссылок обладают достаточной релевантностью к запросу. Естественно, хочется, чтобы документ оказался в первой десятке, поскольку большинство пользователей редко просматривает следующие за первой десяткой ссылки. Иными словами, если ссылка на документ будет одиннадцатой, то это также плохо, как если бы ее не было вовсе. 1. Алгоритм поиска поисковой системыПять "постулатов" работы поисковой системы [1]:
Заказчику следует знать, что не следует удивляться, когда Разработчик вставляет в сайт слова или выражения, не совсем логичные с точки зрения литературного языка. Разные блюда можно приготовить из одних и тех же продуктов. Поисковые системы получают разные результаты, основываясь на одних и тех же исходных данных. Все зависит от алгоритмов обработки этих данных, заложенных создателями поисковых систем. Одни системы уделяют внимание "индексу цитирования", другие нет, одни системы анализируют мета-теги, другие нет. Если посмотреть рейтинги одного и того же сайта в разных поисковых системах, он везде окажется различным. Оптимизировать сайт (содержание сайта) под все поисковые системы технически невозможно. Поисковые системы отличаются объемом проиндексированных страниц и периодом обновления своего индекса. Объём индексации поисковых систем оценивается по двум основным параметрам: по количеству веб-страниц, которые поисковые системы посетили для создания своей базы данных, и количеству веб-страниц, проиндексированных в базе данных. Чем большее число веб-страниц посетил поисковый робот (программа, отвечающая за просмотр и сбор информации с сайтов), тем большее количество перекрестных ссылок он проиндексировал. Поисковые системы различаются периодом обновления своего индекса, то есть временем, за которое происходит полное обновление базы данных поисковой системы. Чем короче этот период, тем более точными будут результаты, тем меньше будет "мертвых ссылок" по результатам запроса. Именно поэтому рейтинг сайта в одной и той же поисковой системе может изменяться: появляются или исчезают какие-то сайты, вводятся изменения и дополнения в алгоритм работы поисковых систем, меняется структура Вашего сайта, представленная на сайте информация и т.п. Периоды обновления индекса генератора основных русскоязычных поисковых машин - Яndex, Rambler, "Апорт", "Mail.ru" и "Google" различны : от одной недели до месяца. В зависимости от того, к какой тематике относится сайт, период обновления индекса может быть различен. После регистрации (точнее, при предложении для регистрации) своего сайта в этих поисковых машинах ссылка на него появится не одновременно, а только тогда, когда будет обновлена база данных каждой поисковой системы. Обобщённо алгоритм работы поисковой системы и рейтинг, который она выстраивает на основе запроса (ключевое слово), учитывает и анализирует следующее[1]:
Многие поисковые машина алгоритма как такового вообще не имеют. Их работа сводится, в основном, к очистке текста сайта от программного кода и выстраивания слов, встречающихся на сайте по их частоте. Чем сложнее алгоритм работы поисковой машины, тем, с одной стороны, больше вероятность получения наиболее точных и полных результатов, но, с другой стороны, больше вероятность ошибок в работке самого алгоритма. Другими словами, усложняя алгоритм работы поисковой машины можно как достичь более полных и точных результатов, так и, наоборот, получить менее точные и полные результаты. Программный модуль поиска по сайту, обеспечивающий высокое совпадение результатов поиска с ожидаемым человеком результатом и работающий автономно, без вмешательства человека, смело мог бы претендовать на название "искусственный интеллект". К основным проблемам, связанным с внедрением программного модуля поиска по сайту, можно отнести следующие:
Не случайно, одной из наиболее сложных технических задач является создание сайтов, представляющих собой поисковую систему. Алгоритм работы поисковой системы очень сложен. Для его разработки нужны не только специальные технические знания в области программирования, но и знания во многих других областях, например, в области филологии, знания того языка, на котором осуществляется поиск, глубокие знания той тематики, к которой относится конкретный сайт и т.д. Реальная стоимость разработки поисковой системы может повергнуть в изумление даже крупных бизнесменов. Для того чтобы результаты, которые выдаются программным поисковым модулем сайта соответствовали ожиданиям, необходимо обеспечить возможность его настройки администратором сайта [2]. В настройках должна быть обеспечена возможность:
Как показывает практика, поисковые модули, внедрённые в состав существующих сайтов, не предоставляют указанных возможностей. Включённые в состав многих существующих сайтов поисковые модули не обеспечивают соответствие полученных результатов c ожидаемыми. Разочарованный посетитель часто покидает сайт, так и не найдя интересующую его информацию. Хотя последняя на сайте имеется. В результате фирма (владеющая сайтом) значительно недополучает прибыль. В некоторых сайтах, в состав которых, по требованию Заказчика, был включён модуль поиска по сайту, в выданных результатах можно найти всё что угодно, кроме нужной информации. Другим распространённым случаем является избыточность выдаваемых результатов. Рассмотрим такой случай. Сайт состоит из 10 отдельных html-страниц, а в выдаваемых поисковым модулем результатах содержатся ссылки, например, на 15 страниц этого же сайта. Что говорить о сайтах, число html-страниц которых, например, 100 и более. Найти нужную информацию на таком сайте становится просто невозможно. Объясняется это тем, что Заказчик не задумывается на тем, насколько эффективно и целесообразно включение в состав его сайта поискового модуля. Руководствуется тем, что раз у некоторых сайтов поисковый модуль есть, то он должен быть и на его сайте. В результате уменьшается прибыль, которую должен и может приносить его собственный сайт. 2. Принципы работы поисковой машины РамблерИнтернет постоянно растет, так же как растет и число пользователей, которые обращаются с запросами к поисковым системам. Увеличение объема информации и количества запросов, в свою очередь, приводит к повышению требований к скорости работы поисковых машин, качеству поиска и наглядности представления результатов. Так, для того чтобы пользователь остался доволен результатом, на сегодняшний день поисковой системе нужно собрать, обработать, обновить, найти и отсортировать в два раза больше документов, чем год назад. А основная задача поиска как раз и состоит в том, чтобы пользователь был доволен его результатами. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось переформулировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Сможет ли он, вернувшись завтра и дав тот же запрос, получить те же результаты? Для того чтобы ответы на эти вопросы оставались удовлетворительными, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции, ускоряют работу системы. В этой статье мы обратимся к механизму работы поисковой машины Рамблер, и на примере ее устройства продемонстрируем, как достигается повышение качества и скорости поиска в условиях постоянного роста объема информации в сети Интернет. 2.1 ПолнотаПолнота - это одна из основных характеристик поисковой системы, которая представляет собой отношение количества найденных по запросу документов к общему числу документов в Интрнете, удовлетворяющих данному запросу. Например, если в сети Интернет имеется 100 страниц, содержащих словосочетание "Красная площадь", а по соответствующему запросу было найдено всего 70 из них, то полнота поиска будет 0,7. Чем полнее поиск, тем меньше вероятность, что пользователь не сможет найти нужный ему документ, при условии, что он вообще существует в Интернет. Полнота поиска в большой мере зависит от работы системы сбора и обработки информации. В связи с постоянным ростом количества документов в сети, эта система в первую очередь должна быть масштабируемой. В Рамблере масштабируемость достигается за счет параллельного исполнения задачи произвольным количеством машин. Сбором информации занимается робот-паук, который обходит страницы с заданными URL и скачивает их в базу данных, а затем архивирует и перекладывает в хранилище суточными порциями. Робот размещается на нескольких машинах, и каждая из них выполняет свое задание. Так, робот на одной машине может качать новые страницы, которые еще не были известны поисковой системе, а на другой - страницы, которые ранее уже были скачаны не менее месяца, но и не более года назад. Хранилище у всех машин едино. При необходимости работу можно распределить другим способом, например, разбив список URL на 10 частей и раздав их 10 машинам. Параллельная работа программы позволяет легко выдерживать дополнительную нагрузку: при увеличении количества страниц, которые нужно обойти роботу, достаточно просто распределить задачу на большее число машин. В хранилище информация в сжатом виде собирается и разбивается на куски по 50 Мб. Эти части постепенно распределяются между 70 машинами, на которых запущена программа-индексатор. Как только индексатор на одной из машин заканчивает обработку очередной части страниц, он обращается за следующей порцией. В результате на первом этапе формируется много маленьких индексных баз, каждая из которых содержит информацию о некоторой части Интернета. Таким образом, вся интеллектуальная обработка данных осуществляется параллельно, поэтому ускорение процесса индексации достигается простым добавлением машин в систему. После того, как все части информации обработаны, начинается объединение (слияние) результатов. Благодаря тому, что частичные индексные базы и основная база, к которой обращается поисковая машина, имеют одинаковый формат, процедура слияния является простой и быстрой операцией, не требующей никаких дополнительных модификаций частичных индексов. Основная база участвует в анализе как одна из частей нового индекса. Так, если объединяются 70 новых частей, то в анализе участвует 71 фрагмент (70 новых + основная база предыдущей редакции). Кроме того, единый формат позволяет проводить тестирование частичных баз еще до объединения их с основной, и обнаруживать ошибки на более раннем этапе. Специальная программа ("сливатор") составляет таблицы перенумерации документов базы. Содержимое всех частей объединяется. Среди страниц с одинаковыми адресами выбирается наиболее свежая версия; если при скачивании URL последней информацией была ошибка 404 (запрашиваемая страница не существует), она временно удаляется из индексной базы. Параллельно осуществляется склейка дублей: страницы, которые имеют одинаковое содержимое, но различные URL, объединяются в один документ. Сборка единой базы из частичных индексных баз представляет собой простой и быстрый процесс. Сопоставление страниц не требует никакой интеллектуальной обработки и происходит со скоростью чтения данных с диска. Если информации, которая генерируется на машинах-индексаторах, получается слишком много, то процедура "сливания" частей проходит в несколько этапов. В начале частичные индексы объединяются в несколько промежуточных баз, а затем промежуточные базы и основная база предыдущей редакции пересекаются. Таких этапов может быть сколько угодно. Промежуточные базы могут сливаться в другие промежуточные базы, а уже потом объединяться окончательно. Поэтапная работа незначительно замедляет формирование единого индекса и не отражается на качестве результатов. 2.2 ТочностьТочность - еще одна основная характеристика поисковой машины, которая определяется как степень соответствия найденных документов запросу пользователя. Например, если по запросу "Красная площадь" находится 150 документов, в 70 из них содержится словосочетание "Красная площадь", а в остальных просто присутствуют эти слова ("красная баба кричала на всю площадь"), то точность поиска считается равной 70/150 (~0,5). Чем точнее поиск, тем быстрее пользователь находит нужные ему документы, тем меньше "мусора" среди них встречается, тем реже найденные документы не соответствуют запросу. Повышение точности в поисковой машине Рамблер достигается за счет использования различных технологий на всех этапах обработки и поиска информации. Одним из наиболее интересных процессов является распознавание грамматических омонимов. Омонимы - это слова, которые имеют одинаковое написание, но различный смысл. Различают лексические и грамматические омонимы. Лексические омонимы относятся к одной части речи, как, например, существительное "бор": хвойный лес, стальное сверло и химический элемент. Грамматические омонимы относятся к разным частям речи, поэтому по написанию у них обычно совпадают только отдельные формы. Примерами грамматических омонимов могут служить слова "печь" - существительное русская "печь" и глагол "печь" пирожки; "рядовой" - прилагательное "рядовой" сотрудник и существительное "рядовой" Иванов. Омонимы не только увеличивают размер индексной базы (так как для каждого такого слова приходится хранить все его возможные значения), но и отрицательно сказываются на точности поиска. Если пользователь ищет слово "данные", ему неинтересно получить в найденном все документы, которые содержат слово "дать". Для того, чтобы результаты поиска были точнее, модуль синтаксического анализа проводит разбор окружения слов-омонимов с целью установления их наиболее вероятных значений. Например, если рядом со словом "печь" стоит существительное ("пирожки", "картошка"), то с высокой вероятностью "печь" в данном контексте является глаголом. На сегодняшний день анализатор способен распознавать значения только грамматических омонимов. Синтаксический анализ позволяет также с определенной вероятностью распознавать некоторые имена собственные. Например, если в тексте несколько слов подряд написано с большой буквы, они чаще всего представляют собой имя собственное (Петр Петрович, Московский Государственный Университет). Данные о таких конструкциях учитываются при индексации и обработке запроса. Еще один способ повышения точности поиска - это выделение устойчивых обозначений и поиск их как отдельных лексических единиц. На сегодняшний день в Рамблере реализована система распознавания таких конструкций, например C++, б/у, п/п-к. Если по запросу С++ поднимать все тексты, в которых присутствуют латинская буква С, а также знак +, то получится огромное количество документов, далеко не все из которых соответствуют запросу; кроме того, это большая работа, значительно увеличивающая время поиска. Огромную роль в повышении точности поиска играет ранжирование. Пользователь очень редко просматривает больше трех страниц с результатами поиска. Поэтому субъективно он оценивает точность по "верхним" документам. Даже если нужный документ найден поисковой машиной, но расположен на двухсотой позиции, скорее всего, он никогда не будет найден пользователем. По умолчанию в Рамблере результаты ранжируются по степени соответствия (релевантности) запросу и группируются по сайтам. При ранжировании оцениваются различные характеристики текстов, такие как:
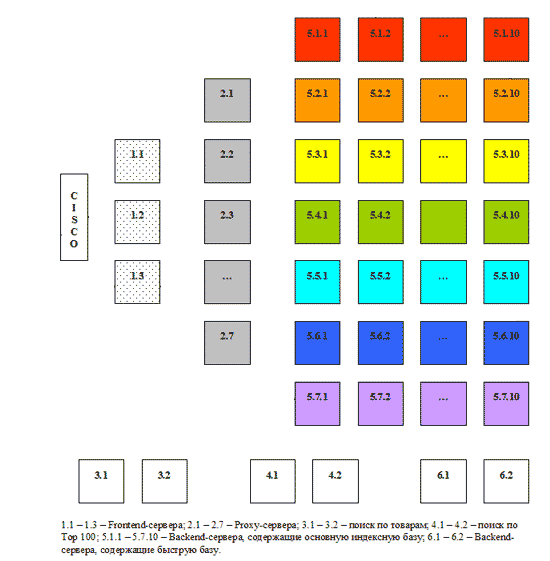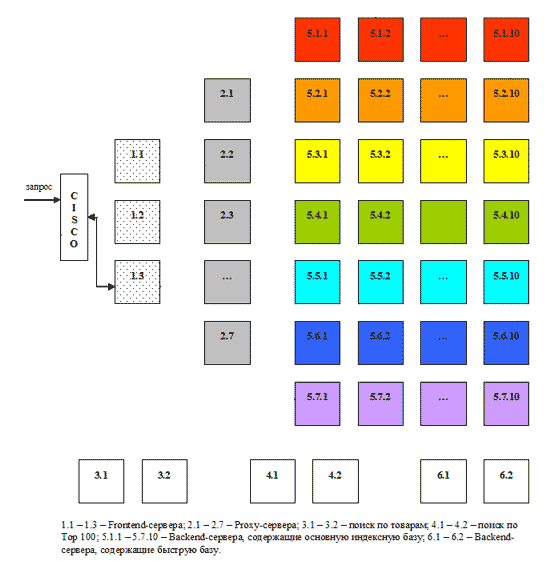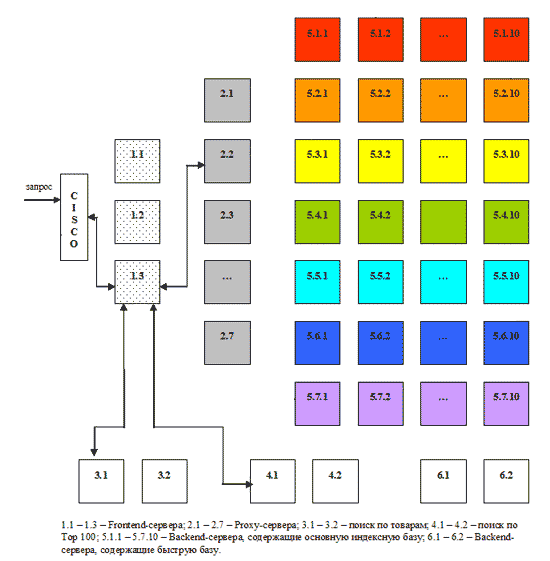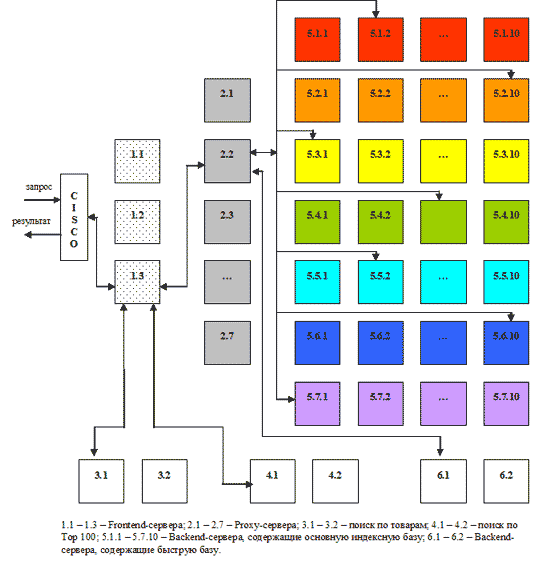
Помимо автоматических способов увеличения точности поиска, существуют различные средства, с помощью которых пользователь сам может уточнить поиск по отдельным запросам. В первую очередь к ним относится специальный язык поискового запроса, используя который можно ограничивать количество найденных документов. Например, запрос или его часть, взятые в кавычки, обрабатываются буквально, с учетом всех стоп-слов, форм, порядка, знаков препинания. Это повышает точность поиска, но уменьшает его полноту: если часть, заключенная в кавычки, неточна, нужный документ найден не будет. Использование логического оператора OR (ИЛИ) позволяет расширить сферу поиска и увеличить его полноту, в то время как оператор NOT (И-НЕ), наоборот, повышает точность поиска за счет нахождения документов, которые содержат одни слова запроса и не содержат другие. Для повышения точности можно также задавать расстояние между словами. Если в искомом словосочетании порядок слов обычно сохраняется (например, Красная площадь), то в запросе для повышения точности имеет смысл ограничить расстояние, указав его в скобках через запятую: (2, Красная площадь). Это позволит отсеять документы, в которых слова красная и площадь не расположены рядом, а разбросаны по тексту. Увеличить точность можно с помощью использования поиска в найденном. Уточняющий поиск, проводится уже не по всей индексной базе, а только по результатам предыдущего поиска. Таким образом, круг найденных документов сужается. Например, если дать запрос Красная площадь, а затем, провести поиск в найденном по запросу Москва, то результат будет содержать только те документы, в которых говорится о Красной площади города Москвы. 2.3 АктуальностьАктуальность - не менее важная характеристика поиска, которая определяется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу. Например, на следующий день после теракта в Тушино огромное количество пользователей обратились к поисковой машине Рамблер с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток. Однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию "быстрой базы", которая обновляется два раза в день, а при необходимости может обновляться быстрее. На сегодняшний день индексная база поисковой системы Рамблер состоит из 8 частей, каждая из которых живет своей независимой жизнью. Весь Интернет условно разделен на 7 секторов и называется своим цветом: красный, оранжевый, желтый, зеленый, голубой, синий, фиолетовый. Сайт компании Рамблер относится к голубому сектору. Информация о web-ресурсах каждого сектора хранится в соответствующей части индексной базы. Восьмая часть - "быстрая база" - включает в себя страницы, на которых размещен счетчик Тор 100 и которые еще не успели попасть в основную индексную базу. Все части индексной базы собираются и обновляются по отдельности. Так, сегодня происходит переиндексация и обновление красного сектора, завтра - оранжевого и желтого, послезавтра - зеленого и т.д. Благодаря такому ступенчатому алгоритму в поисковой машине регулярно появляется свежая информация. Полный цикл обновления занимает около недели. При этом сбор информации происходит параллельно, а непосредственно на изготовление индекса документов одного сектора уходит всего несколько часов. Поэтому существует принципиальная возможность обновлять индексную базу быстрее. Разделение Интернета на 7 секторов условно. При необходимости он может быть разбит на 10, 20 или 40 секторов, каждый из которых будет обрабатываться автономно. В такой системе заложена возможность значительного увеличения нагрузки. С ростом объема информации в сети Интернет растет и индексная база поисковой машины. Постепенно переиндексация и сборка базы начинает занимать все больше времени, а процесс обновления индекса становится более громоздким. Поступление новых данных затягивается, информация начинает терять свою актуальность. Возможность "передела" Интернета на большее число секторов позволяет удерживать размер каждой части базы в оптимальном диапазоне, контролировать время ее сборки и обновления. "Быстрая база" отличается от остальных частей индекса меньшим объемом и очень оперативным обновлением: время ее построения занимает около двух часов. В базе содержится информация о страницах, на которых был установлен счетчик Тор 100. Участниками рейтинга Тор 100 являются новостные порталы, сайты крупных компаний, Интернет-магазины, форумы, - все наиболее популярные ресурсы в сети. Каждый раз при установке счетчика на новую страницу сайта, зарегистрированного в Тор 100, информация передается в поисковую систему. Страница ищется во всех цветах основной базы и, если она еще не известна поисковой системе, отправляется в очередь на обработку. Перед обработкой страницы дополнительно фильтруются, из них отбираются самые посещаемые. Таким образом, "сливки" с Интернета собираются два раза в день. "Быстрая база" представляет собой разумное решение проблемы актуальности данных в поиске. Информационное агентство может выложить новость через десять минут после ее появления, потому что тратит время только на верстку страницы. Поисковая машина должна сначала заиндексировать текст, а на это требуется гораздо больше времени. "Быстрая база" охватывает все ресурсы Интернет, зарегистрированные в Тор 100, на которых был размещен счетчик, и которые еще не успели попасть в основную базу. При этом индексируются как страницы с новостями, так и другие свежие документы, появившиеся в Тор 100. В результате через сутки после теракта в поиске Рамблера была доступна не только основная информация, опубликованная на сайтах новостных агентств, которую можно найти и прочитать в разделах новостей, но и комментарии, высказывания очевидцев, обсуждения на форумах, все, что было к этому времени опубликовано на наиболее посещаемых страницах Интернета. 2.4 Скорость поискаСкорость поиска тесно связана с его устойчивостью к нагрузкам. На сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих. Схематично обработка поискового запроса изображена на рисунке 2.1 [3]. Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня - frontend (1.1 - 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.1 - 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 - 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 - 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, - backends (5.1.х - 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с "быстрой базой" (6.1 - 6.2, на рис. 6.1).
Рисунок 2.1 - Обработка запроса На текущий момент в поиск включено 77 backend'ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend'ах первой группы (5.1.1 - 5.1.11 на рис), оранжевый сектор - на backend'ах второй группы (5.2.1 - 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend'ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу. После того, как запрос обработан на backend'ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин "быстрой базы". Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend'ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим - с 6.1, четвертым - с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend. Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю. Каждый из этапов обработки запроса многократно продублирован и защищен системой балансировки нагрузки. Благодаря дублированию информации поисковая система Рамблер является устойчивой к сбоям на отдельных участках, авариям, отказам оборудования. Если одна их машин перестала функционировать, нагрузка перераспределяется на другие машины, и выпадения документов из поиска не происходит. Масштабируемость достигается простым добавлением в систему машин соответствующего уровня. До недавнего времени в Рамблере работало 45 backend'а. В связи с тем, что осенью нагрузка на поисковые системы обычно возрастает, число backend'ов было увеличено до 77, что позволило значительно ускорить вычисление запросов. Еще один способ повышения скорости поиска - "кэширование", сохранение информации о запросах и результатах поиска в буфере. Многие люди дают одни и те же поисковые запросы. Вычислять их каждый раз заново, было бы неразумной тратой времени. Поэтому если запрос уже обрабатывался в течение некоторого интервала времени, результаты поиска отдаются пользователю из "кэша". Лингвистический анализ текста документов и запроса также позволяет ускорить обработку информации. Например, определение значения омонимов уменьшает количество нерелевантных запросу документов, которые нужно ранжировать и цитировать. Выделение устойчивых обозначений (С++, б/у) на этапах индексации и обработки запроса приводит одновременно к повышению точности и сокращению временных затрат на обработку каждого отдельного элемента обозначения (раньше запрос С++ обрабатывался как отдельно латинское С, отдельно плюс и еще один плюс. Запрос вычислялся долго, а среди результатов поиска было много нерелевантных документов, например, страницы, содержащие математические формулы и т.п.) С этой же целью используются словари стоп-слов. Стоп-слова - это наиболее частотные слова языка, которые встречаются практически в любом тексте и являются малоинформативными. В основном, это служебные слова - предлоги, частицы, артикли. Если нет специальных указаний, поисковая машина игнорирует стоп-слова, встречающиеся в запросе, чтобы не тратить время на обработку дополнительной информации, снижающей качество поиска. 2.5 НаглядностьНаглядность представления результатов является необходимым компонентом удобного поиска. На плохой витрине легко не заметить хороший товар. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости запросов или неточности поиска, даже первые страницы не всегда содержат только нужную информацию. Это означает, что пользователю часто приходится проводить свой собственный поиск внутри списка найденного. Различные элементы ответной страницы помогают ориентироваться в результатах поиска. Группировка по сайтам предназначена для того, чтобы на странице можно было вывести как можно больше Интернет-ресурсов, релевантных запросу пользователя. Это бывает важным, когда необходимо получить информацию из различных источников. Если более информативной для посетителя является дата обновления или релевантность отдельных документов, в ответной странице Рамблера существует возможность сортировки по этим параметрам. В некоторых случаях полезным бывает знание имени сайта. Если пользователя интересует конкретный Интернет-ресурс, имя может дать ему гораздо больше информации, чем заголовок страницы или цитата. Если запросу соответствует больше одной страницы с сайта, то в качестве результата поиска предъявляется наиболее релевантная из них, а ниже располагается частичный список остальных документов. Это увеличивает количество потенциально полезной информации на ответной странице и часто позволяет уточнить поиск без дополнительного запроса. Цитата помогает определить, насколько полезную информацию содержит найденный документ. Очень часто посетителю не требуется переходить по ссылке, чтобы обнаружить, что текст не соответствует его интересам и потребностям. Иногда ответ на вопрос пользователя содержится непосредственно в цитате документа. Это экономит время и повышает эффективность работы поисковой системы. Восстановить текст - иногда единственный способ получить доступ к содержимому найденного документа. Ресурс бывает недоступен по разным причинам. Документ может быть удален, перенесен, изменен, но его текстовое содержание некоторое время сохраняется в индексной базе. Кроме того, внутри самого документа часто отсутствует навигация, позволяющая быстро найти фрагмент, релевантный запросу. В восстановленном тексте все слова запроса подсвечиваются. Ассоциации представляют собой список запросов, которые часто подаются пользователями в течении одной поисковой сессии. Алгоритм построения ассоциаций устроен так, что они почти всегда связаны между собой по смыслу. В некоторых случаях ассоциации позволяют повысить качество поиска за счет уточнения запроса (запрос "отдых в Польше" - ассоциации "отдых в Польше с детьми", "семейный отдых", "пансионаты в Польше"), исправления распространенных ошибок (запрос "gjujlf" - ассоциация "погода"), возможности сориентироваться в незнакомой тематике (запрос "антибиотик" - ассоциации "сумамед", "цифран", "бисептол" и т.д.) 3. Основные концепции и подходы при создании контекстно-поисковых систем на основе реляционных баз данных3.1 АрхитектураРассмотрим классическую архитектуру, которая чаще всего реализована на корпоративных сайтах и информационных порталах. Такая архитектура изображена на рисунке. 3.1 [3].
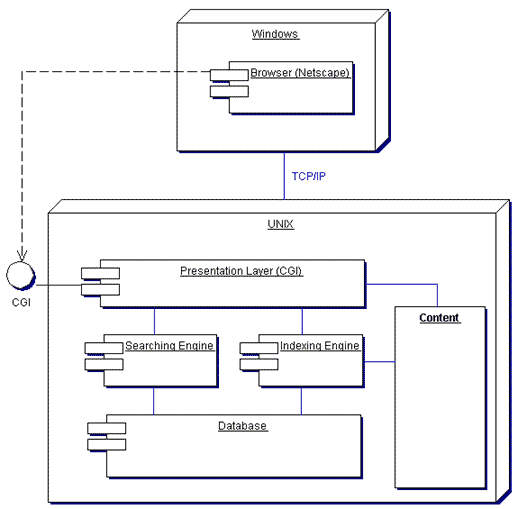
Рисунок 3.1 - Классическая архитектура ПС Разберем по частям то, что изображено на рисунке. Существует клиентская вычислительная машина под управлением ОС Windows и существует Web-сервер под управлением UNIX-подобной ОС. На стороне клиента запущен типичный браузер, такой как Netscape. На стороне сервера запущен web сервер, который обслуживает запросы от браузера, передавая запросы презентационному слою понимающему CGI. Презентационный слой передает запросы к поисковому механизму в случае вызова услуги поиска или отображает наполнение ( content) сайта. При работе администратора презентационный слой также может передавать запросы на инициализацию механизма индексации нового контента, который еще не индексирован. Это необходимо по той причине, что пока текст не индексирован, поиск в нем с помощью поисковой машины невозможен. Идея заключается в следующем. Существуют мегабайты текстовой информации, и скорость поиска документов содержащих заданные ключевые слова отнимает очень много процессорного времени. Предположим, в 10 мегабайтах текстовой информации ключевое слово будет находиться в течение 10 секунд. И вот заходит посетитель на Ваш сайт, задает ключевые слова, вызывает услугу поиска и ждет 10 секунд, пока ваш сервер не выдаст ему результат. Предположим, случилось так, что одновременно запросило поиск 5 человек. Естественно, время ответа увеличится в 5 раз. Получается, что в среднем по 50 секунд пользователь будет ждать ответа от вашего сервера. Это не приемлемо, особенно если у Вас сотни мегабайт текстовой информации и время реакции системы будет катастрофически велико. Необходимо использовать другой подход при поиске ключевых слов в текстовой информации - время ответа сократить до миллисекунд. 3.2 ER-модель поискового механизмаСуществует такая хорошая характеристика реляционных баз данных, как очень маленькое время выборки конкретной записи из миллионов других. Это достигается созданием так называемого индекса к таблице на какое-то из полей этой таблицы. Обычно индексы реализуются с применением алгоритма сбалансированного двоичного дерева. Предположим, у нас есть таблица, в которой всего один столбец и в каждой записи таблицы хранится фамилия человека. Предположим, мы загнали в такую таблицу 1 миллион фамилий. Нам необходимо проверить существует ли в этой таблице фамилия ИГУМНОВ. Предположим, что мы еще никаких индексов на эту таблицу не сделали, так же фамилия ИГУМНОВ стоит посередине таблице. Когда мы пошлем вот такой запрос: select surname from ourtable where surname='ИГУМНОВ' база данных переберет пол миллиона записей пока не дойдет до фамилии ИГУМНОВ и не выдаст результат. Получается слишком медленно. Но как только мы сделаем индекс на поле нашей таблицы, как сразу все наши запросы будут обрабатываться за миллисекунды, чего мы и добиваемся. Естественно, одной таблицы будет мало для решения нашей проблемы. Классическая структура базы данных, которая позволит решить нашу проблему, изображена на рисунке 3.2 [4].
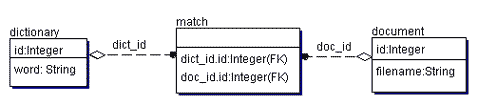
Рисунок 3.2 - Классическая структура базы данных ПС Начнем рассмотрение с таблицы document. В этой таблице хранятся имена файлов или URL'ы страниц и каждой такой записи сопоставлен уникальный ключ id. В таблице dictionary хранятся все слова, которые могут встретиться в наших документах, и каждому слову сопоставлен уникальный id. Естественно, создаются индексы на поле word в таблице dictionary и на поле id в таблице document. В нашем примере существует отношение многие ко многим. Это необходимо, так как в таблице match мы храним соответствие слова и документа. Другими словами, в таблице match хранится информация о том, какие слова есть в каждом документе. На таблицу match создают индекс, на поле dict_id. 3.3 Индексный механизмПрежде чем ваши документы будут доступны для поиска, их необходимо проиндексировать. Объем индексной информации, полученной из текста, может быть в два раза больше чем сам тексте. А может еще больше, в случае если вы будете не оптимально использовать память. Алгоритм выглядит следующим образом.
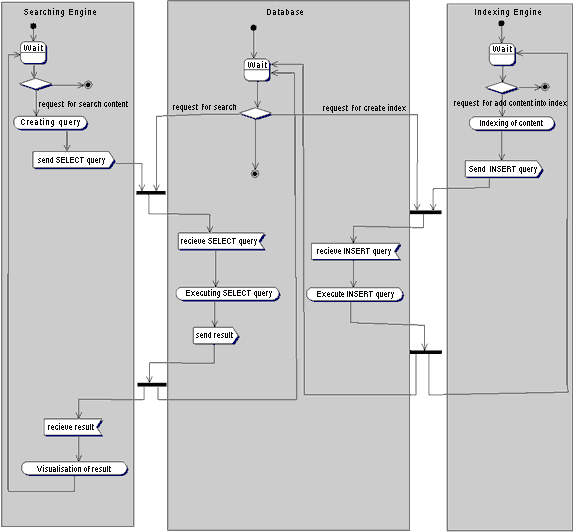
3.4 Поисковый механизмПосле того как документы были проиндексированы, необходимо понять какие запросы посылать в базу, что бы искать эти документы по ключевым словам. Предположим, есть поисковая фраза "река объ". Пользователю необходимо получить все документы содержащие эти два слова. Сначала нужно обратиться к таблице dictionary и узнать уникальные id этих слов, далее будем их называть $dict_id1 и $dict_id2. Потом необходимо послать такой запрос в таблицу match, который выдаст только те номера документов, которые содержат эти два слова. Вот пример этого запроса: SELECT doc_id FROM match where dict_id =$dict_id1 group by doc_id INTERSECT SELECT doc_id FROM match where dict_id=$dict_id2 group by doc_id. В случае если пользователь введет три слова, то вам придется добавить еще раз INTERSECT и третью часть SQL запроса. По полученным в результате запроса doc_id можно извлечь информацию об имени файла документа из таблицы document. 3.5 Комплексное функционированиеОбщее представление механизма взаимодействия с поисковой системой представлено на рисунке 3.3 [5].
Рисунок 3.3 - Механизм взаимодействия с базой данных Как видно из рисунка, существует три потока управления. Первый обслуживает запросы пользователя, второй выполняет поисковые запросы, а третий занимается индексированием новых документов поступающих в систему. Первый поток - это скрипт на Perl, Servlet, ASP или PHP, который из ключевых слов пользователя формирует поисковые SQL запросы. Второй поток - это СУ базой данных, которая поддерживает целостность данных, индексный механизм и обслуживает SQL запросы. Третий поток - это тоже скрипт, который работает с новыми документами, индексирует их и посылает запросы в базу данных на внесения новой индексной информации. 4. Технология оптимизации сайта под поисковые системыДля успешного ведения бизнеса в Интернет значительно выгоднее концентрировать усилия на привлечении к сайту целевых посетителей, тех самых посетителей, на решения проблем которых ориентирован Ваш сервис или продукт, размещенный на сайте. Соответственно встает проблема об отделении целевых пользователей сайта от случайных. Для решения поставленной задачи существуют несколько методов. Один из методов, считать посетителя целевым, если он в результате посещения сайта выполнил переход на специальную целевую страницу. Это может быть страница с заказом продукта, выпиской счета, и т.д. Если посетителя не заинтересовал Ваш сервис он вряд ли зайдет на форму заказа, и такого посетителя следует считать случайным. Другой вариант, целевой посетитель должен загрузить целевой файл. Этот вариант хорошо подходит для сайтов распространяющих программное обеспечение, где целевыми файлами для загрузки являются дистрибутивы программного обеспечения. В программе Download Analyzer для настройки на анализ целевых посетителей следует указать Url целевой страницы или загружаемого файла в поле Downloaded files [6]. Технология анализа и оптимизации поисковых систем, описанная в этой главе курсовой работы первоначально тестировалась на сайтах распространяющих программное обеспечение, где главной целью является увеличение количества закачек дистрибутивов программного обеспечения. Именно об оптимизации целевого трафика сайта пойдет речь далее. Однако эта технология отлично работает для оптимизации посещений целевых страниц сайтов практически любой тематики. Любой вебмастер может применить ее на практике и добиться привлечения целевого трафика с поисковиков. 4.1 Математическая модельЦелью оптимизации сайта под поисковые системы является не столько увеличение количества посетителей на сайт, сколько увеличение количества закачек дистрибутивов программного обеспечения. Поэтому целевой функцией для оптимизации, на пространстве поисковых фраз, является величина трафика закачек t(p) по каждой из фраз в единицу времени. Общий трафик закачек, является интегральной суммой трафика по всем фразам:
Величина трафика закачек по отдельной поисковой фразе зависит от трех функций на пространстве поисковых фраз: t(p)=b(p)*g(p)*w p) b(p) - функция востребованности поисковой фразы, то есть количество запросов фразы в единицу времени пользователями поисковых систем. g(p) - релевантность, величина определяющая насколько точно решение предлагаемое на сайте соответствует проблеме которую посетитель пытался сформулировать поисковой системе в виде запроса по выбранной фразе. В случае с сайтом, где целевой функцией является количество закачек в единицу времени, релевантность можно определить как отношение количества закачек к количеству посетителей с поисковика по выбранной фразе. w(p) - доступность сайта, определяет насколько легко можно найти сайт в результатах поиска по выбранной фразе. Идеальной является ситуация когда для любой поисковой фразы сайт находится на первой позиции результатов поиска. Но в реальной жизни это не всегда так. И тот факт, что наше решение проблемы существует, еще нужно донести до пользователей поисковых систем. Значение функции доступности тем выше, чем более высокую строчку в результатах поиска занимает сайт. Но кроме, номера позиции есть еще и номер страницы в результатах поиска. То есть функция доступности скачкообразно зависит от номера позиции сайта в результатах поиска. Кроме того, на функцию доступности влияет также краткое описание того, что мы видим в результатах поиска. Очевидно, что невозможно сразу по всем фразам достичь полной оптимизации, да и В этом нет особой необходимости. На практике куда важнее поднять функцию доступности до максимума для тех фраз, по которым трафик закачек будет самым большим. Для этого введем понятие функции ценности. Под функцией ценности будем понимать величину трафика закачек a(p) для поисковой фразы при условии, что функция доступности этой фразы достигла максимального значения равного 100%. Тогда трафик закачек определяется как произведение функции ценности на доступность сайта: t(p)=a(p)*w(p) Фактически, ценность фразы это та величина, на которую маркетолог не может повлиять путем оптимизации сайта под поисковые системы: a(p)=b(p)*g(p) Можно сказать, что функция ценности a(p) есть проекция целевого трафика нашего сайта на глобальную функцию востребованности всевозможных поисковых фраз. И чтобы достичь привлечения максимального трафика с поисковиков в кратчайшие сроки, нужно начинать оптимизировать сайт именно для тех фраз, по которым функция ценности имеет наибольшее значение. На практике, сайт наверняка уже имеет частичную оптимизацию и хоть какой-нибудь трафик с поисковиков, даже если вебмастер специально этим не занимался. Возможно даже, что по самым ценным фразам он находиться на первых позициях в результатах поиска. Однако наверняка найдется множество фраз, по которым сайт находиться за пределами доступности пользователей поисковых систем, и по которым можно привлечь ощутимый трафик закачек. Если максимально возможный трафик закачек по выбранной фразе равняется ее функции ценности a(p), а трафик, который имеет сайт в настоящий момент, есть произведение ценности на доступность a(p)*w(p), то недополученный трафик есть разница этих двух величин: d(p)=a(p)* (1 - w(p) ) Суммарный недополученный трафик есть интегральная сумма недополученного трафика по каждой из поисковых фраз:
Таким образом, задачу оптимизации шароварного сайта под поисковые системы можно свести к задаче минимизации суммарного недополученного трафика закачек D. 4.2 Циклы оптимизацииБыло бы замечательно получить отчет, в котором все целевые поисковые фразы отсортированы по функции ценности. А еще лучше отсортировать фразы по величине недополученного трафика закачек. Однако на практике не всегда сразу возможно решить задачу количественного анализа трафика закачек. Одна из причин, отсутствие общедоступной достоверной статистики популярности поисковых фраз. Хотя те сервисы, которые есть в Интернет, вполне пригодны для первоначального анализа:
Однако пожалуй главная причина в том, что функция релевантности уникальна для каждого сайта, и что бы получить вид этой функции необходимо накопить статистику закачек по всем нашим целевым фразам. А для того чтобы накопить статистику, необходима хотя бы частичная оптимизация для целевых фраз. Замкнутый круг? Нет, не совсем. Всегда в логах сайта за продолжительный период найдется информация о редких слабо оптимизированных фразах. Умело, пользуясь этой информацией можно выйти на новый этап оптимизации. Получается, что оптимизация это процесс, который должен развиваться по спирали: анализ -> оптимизация -> ожидание трафика -> накопление статистики -> анализ ->... И на каждом витке должен привлекаться новый трафик и собираться новая статистика. В результате анализа логов сайта, для фраз, по которым накоплена статистика, можно определить функции количества хитов h(p), количества закачек t(p) и релевантности g(p). Не смотря на то, что логи сайта не дают информацию о функциях ценности a(p) и востребованности b(p) фраз, точный вид этих функций не очень то и нужен. На практике достаточно иметь примерную оценку недополученного трафика по каждой из фраз. Согласно статистике, только 23% пользователей поисковых систем доходит до второй страницы результатов поиска, и только 10% до третьей. Следовательно, если сайт находиться за пределами первой страницы результатов поиска по одной из целевых фраз, он однозначно недополучает трафик. И чтобы оценить этот недополученный трафик следует множить на 4 количество закачек для второй страницы результатов поиска, и на 9 для третьей. Таким образом, чтобы получить отчет по фразам, по которым мы недополучаем трафик закачек, в программе Download Analyzer следует выполнить определение позиции в результатах поиска поисковой системы Google, отфильтровать фразы по номеру позиции большей чем 10, и отсортировать отчет по количеству закачек. Если в качестве исходного материала взять лог-файлы сайта за продолжительный период, скажем за пол года, то в отчете может оказаться несколько тысяч фраз с недополученным трафиком. Из всего этого количества фраз необходимо выбрать несколько опорных для первоочередных направления оптимизации. В качестве таких опорных фраз лучше всего подходят фразы, состоящие из двух слов, в редких случаях из одного. Например, фраза address book может встретиться в отчете как составная часть других фраз: simple address book, easy address book, free download address book, phone and address book, electronic address book, address book database, how to use address book ... Чтобы выделить направление оптимизации по опорной фразе address book, и оценить недополученный трафик по всем фразам этой группы, в программе Download Analyzer следует установить фильтр по фразе в состояние: address + book. Если величина недополученного трафика по всем фразам группы (возьмите из строки статуса программы Download Analyzer величину суммарного количества загрузок и умножьте минимум на 5) покажется вам достойной внимания, то для этого направления следует делать специальную рекламную страницу для продвижения ее в поисковиках. Выбрав ряд направлений оптимизации сайта, для каждого из них необходимо создать специальную рекламную страницу напичканную фразами, которые для выбранного направления оптимизации приносят наибольший трафик. Взяв за основу 10-20 самых ценных фраз, следует использовать их как план по написанию будущей статьи. Фактически, наши целевые посетители уже все за нас решили. Нам осталось, только материализовать их желания в содержимом рекламной статьи. Да так, чтобы после прочтения этой статьи у посетителя не возникло сомнений в том, что наше решение его проблемы самое лучшее! Для того чтобы приподнять нашу страницу в результатах поиска следует 5-6 самых ценных фраз поместить в заголовки (h2, h3, ..) между фрагментами текста. Можно использовать жирный шрифт или раскраску ярким цветом для выделения поисковых фраз внутри текста. Можно также запихивать фразы в надписи к картинкам. Еще очень полезно делать ссылки на другие рекламные страницы, включая в текст этих ссылок наиболее ценные фразы той страницы на которую ведет ссылка. Однако, пожалуй самое ценное поле, на которое следует ловить посетителей это Title страницы. Если по какой-то из фраз Вы недополучаете трафик, и до сих пор этой фразы не было ни в одном из Title-ов, то поместив ее в Title вновь созданной страницы Вы будете в первых позициях результатов поиска Google и ряда других поисковиков. Title страницы должен быть предложением, корректным с точки зрения грамматики английского языка, но при этом он должен быть составлен из нескольких самых ценных поисковых фраз. Что делать, если по результатам оптимизации Вы не смогли попасть на первые позиции по очень ценным фразам, по которым слишком велика конкуренция? В этом случае помогает вкрапления этих фраз в другие специальные страницы. Необходимо убедить поисковую систему в том, что не только одна единственная страница, но и в целом весь сайт имеет к тематике этих фраз прямое отношение. 4.3 Генерация отчета по недополученному трафикуОптимизации процесс поэтапный, ей следует заниматься регулярно, лучше, если раз в месяц. Рассмотрим пример оптимизационного процесса, используя программу Download Analyzer. В программе Download Analyzer загружаем лог-файлы за полгода. Итак, за полгода в отчете по фразам наблюдаются 10583 фразы, 43450 хитов и 14989 закачек. Для того, чтобы понять по каким фразам был недополучен трафик, необходимо определить позицию сайта в результатах поиска Google, самой популярной поисковой системы. Запускаем коммуникационный модуль и ждем. Этот процесс естественно требует времени. Но польза очевидна и следует дать возможность загрузить позиции для большинства фраз. В данном примере рассматриваем все фразы, по которым имела место хотя бы одна закачка. Устанавливаем фильтр по минимальному количеству закачек на 1. И всего уже не 10 тысяч фраз, а всего 3849. Случайные фразы отсекли, теперь пусть работает коммуникационный модуль. Итак, есть отчет, в пятом столбце которого позиция сайта по фразе в Google, то сохраняем отчет. Теперь следует приступать к поиску фраз, по которым дальнейшая оптимизация сайта наиболее привлекательна. Для фраз, по которым сайт итак на первой странице результатов поиска особого смысла оптимизироваться нет. А вот фразы, по которым сайт на второй и третьей странице, и при этом есть не равное нулю количество закачек, как раз и есть те самые фразы, по которым недополучается трафик. Выставляем фильтр по позиции сайта в Google в значение 11, и отсекаем таким образом те фразы, по которым и так положение достаточно хорошее. Получилось 1307 фраз. Это тоже много. Но именно эти фразы нужны для дальнейшего анализа. Согласно статистике только пятая часть пользователей посещает вторую страницу результатов поиска, и только десятая часть третью. Таким образом, получаем как минимум 80 закачек в день недополученного трафика. И это учитывая то, что по одной из программ еще практически не имеется статистики, и оптимизация закачек этой программы в настоящий момент находиться на самом первом витке процесса оптимизации. На следующем этапе необходимо определиться с набором слов. Например, когда в поле фильтра по фразе вводится слово read, то внизу в строке статуса наблюдается: Hits: 771, Downloads: 461 и 184 фразы с этим словом, не попавшие на первую страницу результатов поиска. При этом, если снять фильтр по позиции и установить фильтр по фразе в состояние: reading, видно множество фраз со словом reading, которые сделали мне тысячу закачек. И в большинстве случаев, фразы со словом reading, находятся не только на первой странице результатов поиска, но и на первой позиции. Ясное дело, слово reading входит в Title специальной страницы и несколько раз встречается в содержимом страниц, а вот слова read в Title нет, и большинство фраз с этим словом на второй и третьей странице результатов поиска. Получается, если взять одну из специальных страниц, заменить везде слово reading на read, и выложить на сайт как новую страницу, это добавит еще 12,5 закачек в день! Естественно, лучше создать другую страницу с корректным английским и протестировать на ней еще несколько слов. Было найдено 14 слов, по которым имеется значительный недополученный трафик. Теперь необходимо составить несколько комбинаций этих слов, и оценить какие комбинации дают наибольший недополученный трафик. Например, введя в поле фильтра: read + file (конъюнкция), видно 106 фраз и 296 закачек, то есть, порядка 8 недополученных закачек в день... Оценив трафик по различным словам и их комбинациям, можно составить предложение на английском языке, которое содержит внутри себя самые ценные комбинации слов. В Title страницы много слов не впихнешь, и возможно придется сделать еще один Title и еще одну страницу, дабы обыграть фразы, которые могут принести дополнительный трафик. Но пока можно оставшиеся комбинации слов разместить внутри текста страницы. Итак, страница готова, она уже на сайте, и на нее ведут ссылки с других страниц. Прошло всего два дня и Google проиндексировал страницу. Раньше нужно было ждать два месяца. В результате на 60 закачек в день больше. Это конечно не все 80 недополученных закачек, которые хотелось бы иметь сразу и сейчас, но результатом вполне приемлем. 4.4 Оптимизация содержимого страницDownload Analyzer очень ценный инструмент для анализа не только поисковых фраз, но и содержимого страниц сайта. Однажды, сделав очередную специальную страницу для фраз, по которым был недополучен трафик, и, дождавшись переиндексации Google, мною была обнаружена интересная вещь. Релевантность новоиспеченной страницы была почти вдвое больше чем в целом по сайту, 57% против 33%. Можно было подумать, что были найдены очень целевые фразы и за счет этого в отчете по страницам наблюдалась такая аномалия. Однако нет. Новая страница пересекалась по фразам и конкурировала в Google с другой страницей. По ряду фраз можно было наблюдать в детальном отчете как старую, так и новую специальные страницы. Так вот, их релевантность по целому набору фраз также отличалась почти в два раза. Секрет этой аномалии был в содержимом страниц. Более структурированный текст, текст раскрашенный и дополненный рисунками, как выяснилось лучше убеждал посетителя воспользоваться решением, которое предлагалось на сайте. Из чего следует очень простой вывод: оптимизацию сайта следует делать не для поисковых систем, ее следует делать для посетителей этих систем. Если Вам удалось прорваться в топ результатов поиска, используя хитрые спамерские методы, у Вас есть только один шанс не затеряться среди лидеров и остаться в топе, - поднять релевантность страницы до максимума. А значит, сделать привлекательный дизайн, наполнить содержимое страницы правильным востребованным материалом. Современные техники ранжирования стали учитывать мнение пользователей. А значит, шансы прорваться на первые позиции результатов поиска, а главное остаться там, значительно выше для страницы, содержащей ясную четкую статью, максимально соответствующую тематике запроса. Кроме того, такая страница имеет больше шансов быть упомянута в новостях, тематических сайтах, рекомендована подписчикам списка рассылки. Если у людей есть проблема, а у Вас ее решение, Ваша рекламная страница должна стать тем самым мостиком, который свяжет проблему и ее решение. ЗаключениеСуществуют простые, дешёвые, эффективные и хорошо зарекомендовавшие себя альтернативные технические решения по замене системы поиска по сайту, не требующие вмешательства человека и не предъявляющие жестких требований по программно-аппаратной совместимости с сервером. Использование простых способов позволяет посетителю быстро найти нужную ему информацию и, как следствие, увеличить прибыль, приносимую сайтом. В тех случаях, когда включение в состав сайта поискового модуля уж очень хочется Заказчику, то целесообразным будет воспользоваться бесплатными поисковыми модулями, предлагаемыми, уже существующими поисковыми системами. В магистерской работе будет предпринята попытка рассмотреть более подробно механизм работы одной из поисковых систем, и возможные пути оптимизации работы. Литература
|
| [Автобиография] [Диссертация] [Библиотека] [Список ссылок] [Отчет о поиске] [Индивидуальное задание] [ДонНТУ] |