|
Сеть в одном чипе
разрабатывалась, для того, чтобы решать будущие проблемы
повышения производительности
SoC-систем.
Данные проблемы
преодолеваются за счет того, что обеспечивается
возможность централизованного управления сетью. Эта
возможность позволяет согласовать многочисленные ресурсы
сети и стандартизировать протоколы обменов между этими
ресурсами. Другим существенным преимуществом такой сети
является потенциал использования проектирование сети на
основе используемых многократно IP-блоков (IP-core’s).
Специалисты в
области SoC Бенини и Мичели предлагают использовать так
называемую микропарадигму стека сети для адаптации
сетевого стека протоколов для
NoC. Это
позволит специфицировать электрические, логические и
функциональные схемы взаимодействия в сети. Каждый
уровень в вертикальном стеке сети должен быть
специализирован и оптимизирован на столько, на сколько
того требует его область применения.
1.1
Топология
соединений в NoC-сетях
Физический уровень определяет
топологию соединений проводников. Сигнал должен
передаваться без ошибок.
Затраты энергии на передачу сигнала должны быть по
возможности минимальными, но при этом они должны
обеспечивать удовлетворительную работу всех протоколов
верхних уровней.
Средние сети
общего доступа: данный вид
топологии наиболее часто применяется в
SoC-системах,
характерны самыми простыми структурами организации
каналов обмена информацией. В данной топологии все
сетевые устройства коммутации являются общими с точки
зрения доступа по отношению к другим функциональным
элементам SoC.
Но
только
одно устройство может управлять сетью
в момент
времени. Этот тип топологии –
неэффективный с точки зрения энергетических затрат и не
поддающийся масштабируемости.
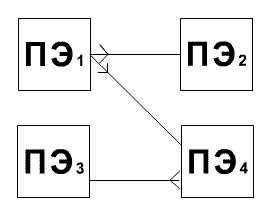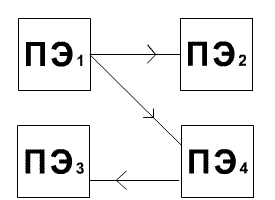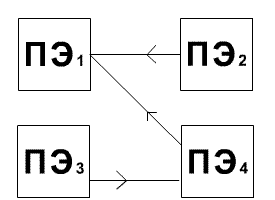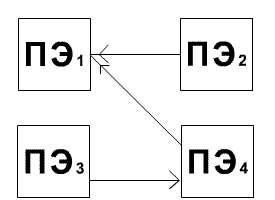
Рисунок 1.1 –
NoC-сеть
прямого доступа.
Сети прямого и косвенного доступа:
в прямой или двухточечной сети каждый узел
непосредственно соединен с конкретным набором соседних
узлов (смотреть рисунок 1.1). Данная архитектура
преодолевает проблему отсутствия масштабируемости
(которая присуща средним сетям общего доступа). В сетях
косвенного доступа (коммутируемых сетях) связь между
узлами осуществляется путем переключения ряда
коммутаторов. Сетевой адаптер, связанный с каждым узлом,
соединяется с портом управления соответствующего
коммутатора (коммутаторов).
Гибридные сети:
реализуются с помощью иерархических шин либо
многоканальных переключателей. Данная архитектура сети
предусматривает большую коммутирующую способность и
малое время обменов информацией между узлами сети.
1.1
Управление
микросетью
Протоколы определяют, как
использовать ресурсы сети во время системных операций.
Динамическое управление сетью распределяет ресурсы сети
вовремя этих операций, стремясь обеспечить необходимуе
вычислительную мощь всей сети.
Уровень передачи
данных: физический уровень,
при передаче информации через который существует
вероятность потери информации. Протоколы канального
уровня увеличивают надежность связи, обеспечивая ее
минимально необходимый уровень, т.к. физический уровень
не является достаточно надежным. Эти протоколы
обеспечивают обнаружение ошибок и исправление их.
Канальный уровень также регулирует размерность и
количество пакетов данных исходя из соотношения
“количество проверочной информации / вероятность
возникновения ошибки”.
Сетевой уровень:
этот уровень осуществляет контроль соединений между
конечными узлами. Здесь коммутация близко связана с
маршрутизацией. Направляющие алгоритмы отвечают за
создание канала для передачи сообщения конечному
адресату. Детерминированные алгоритмы отвечают за
создание того же самого канала обмена, но с поправкой на
то, что между точкой отправления сообщения и точкой
получения существует периодичность обмена сообщениями
(достаточно постоянный трафик). Для данного рода
алгоритмов построения информационного канала актуальным
является не только адресат, но и отправитель (в отличие
направляющих алгоритмов). Адаптивные алгоритмы
анализируют трафик сети в целом с целью
“устранения
узких мест”.
Данный подход
предпочтительнее для сетей с непостоянным трафиком и
ненадежными информационными узлами.
Транспортный
уровень: отвечает за анализ и
сбор пакетов сетевого уровня в единое целое. Степень
детализации при пакетировании является важным фактором
при проектировании всей системы, потому что большинство
алгоритмов управления – очень чувствительны к размеру
пакета. Однако ограничения обусловленные размерами
пакетов в NoC менее критичны, чем в классических сетях.
2
РЕШЕНИЕ
ОБЫКНОВЕННЫХ ДИФФЕРЕНЦИАЛЬНЫХ УРАВНЕНИЙ
Несмотря на постоянное повышение производительности
процессоров, большое количество задач (в частности,
сложные системы обыкновенных дифференциальных уравнений)
является невыполнимым для однопроцессорных машин, так
как время их решения неприемлемо велико. Для их
выполнения применяют многопроцессорные машины, при этом
задача разделяется на подзадачи, решаемые отдельно на
каждом процессоре системы, после чего результаты решения
подзадач обрабатываются для получения общего результата
всей решаемой задачи. Область задач, требующих
распараллеливание процесса вычислений, очень велико и
распространяется практически на все сферы научных
исследований и растет с каждым годом
[3].
Целью
работы магистра является разработка
программного-аппаратного средства для параллельного
расчета систем обыкновенных дифференциальных уравнений,
представленных в виде задачи Коши. Для исследования
процесса параллельных вычислений системы обыкновенных
дифференциальных уравнений воспользуемся схемой Эйлера
для численного интегрирования систем ОДУ. Каждое из
уравнений можно рассматривать как отдельный процесс
расчета на одном шаге интегрирования. Предполагается
схема расчета:
• Оптимизация правой части
уравнения путем преобразования инфиксной формы записи в
постфиксную (ПОЛИЗ).
• Расчет многоитерационного
процесса путем распараллеливания на каждом шаге
интегрирования.
Требования для этой
системы:
• решение
системы ОДУ за время меньшее, чем при последовательном
расчете;
• самостоятельное
разбиение исходной системы уравнений на параллельные
блоки, обеспечивающие минимальное время расчета;
• проведение
анализ примерного времени параллельного расчета и
времени последовательного расчета;
• разбивка
системы уравнений на параллельные блоки;
• анализ
времени параллельного расчета.
Актуальность применения параллельного расчета систем ОДУ
в форме Коши состоит в том, чтобы время расчета системы
было меньше, чем при последовательном расчете.
ВЫВОДЫ
Планируемая работа магистра нацелена на то, чтобы
реализовать с помощью многопроцессорной сети NoC
(network-on-chip) параллельный решатель дифференциальных
уравнений.
NoC
содержит в себе большой потенциал, как следующая ветвь
развития СБИС. Также теория организации SoC на данный
момент имеет целый ряд белых
пятен – одно из них организация NoC, обладающей
топологией, специализированной для решения обыкновенных
дифференциальных уравнений.
Решение поставленной задачи
организации подобной NoC может привести к получению
аппаратного решателя ОДУ, который будет иметь прозрачную
масштабируемую структуру - удобную для последующих
модификаций и обладающую высокой вычислительной
производительностью.
СПИСОК ИСПОЛЬЗОВАННЫХ
ИСТОЧНИКОВ
1. Web-Site of Program Construction and Optimization
Laboratory Institute of Informatics Systems SD RAS.
http://pco.iis.nsk.su/grapp2/html/ReqtypetNamevremenna^_slojnost8.htm
2. Maria Elisabete, Marques Duarte. Networks on Chip (NOC):
Design Challenges. Departamento de Informática,
Universidade do Minho.
http://gec.di.uminho.pt/discip/minf/ac0203/ICCA03/41720_NOC.pdf.
3. Белых А. А. Проблемы последовательно-параллельного
анализа задачи Коши. Електронный сборник работ студентов
кафедры АСУ.
http://asu.cs.nstu.ru/doklads.html.
|
