|
Для систем с распределённой памятью время передачи данных зависит от следующих характеристик
коммуникационной подсистемы [1, c.50–51]:
- Латентности (ts) – времени подготовки к выполнению коммуникации, отсчитывающегося
с момента её инициирования;
- Времени передачи одного слова данных (tw) от одного узла другому.
Очевидно, что время передачи данных пропорционально их объёму (справедливо для больших объёмов
передаваемых данных) [1, c.48-69]. Следовательно, при уменьшении объёма передаваемых данных
происходит снижение времени выполнения параллельного алгоритма. Таким образом, параллельный
алгоритм умножения матрицы на вектор в общем случае будет эффективнее умножения матрицы на матрицу.
Как следствие вышесказанного можно утверждать, что:
- Алгоритмы вычисления матрично–векторного произведения в общем случае имеют более низкое
время выполнения, чем алгоритмы вычисления матричного произведения;
- Свойство 1) может нарушаться, если в алгоритме умножения матрицы на вектор будут передаваться
только блоки матрицы;
- Среди алгоритмов вычисления матричного произведения наилучшим в отношении времени
выполнения будет алгоритм, выполняющий наименьшее количество коммуникационных операций;
- Среди алгоритмов вычисления матрично–векторного произведения наилучшим в отношении времени
выполнения будет алгоритм, выполняющий наименьшее количество коммуникационных операций
(в коммуникациях которого будут фигурировать только блоки векторов).
Особенностью алгоритмов Кэннона является смена отображения блоков одной из матриц–операндов (A, B)
или матрицы–результата (C) на узлы вычислительной решётки. Каждый из алгоритмов Кэннона сохраняет
отображение блоков соответствующей матрицы на узлы вычислительной решётки [4, c. 26–55]. Пусть для
указания матрицы, отображение блоков которой не меняется во время выполнения алгоритма, её
обозначение будет упоминаться в названии алгоритма.
Полное время выполнения различных версий алгоритма Кэннона определяется формулами (2.1) – (2.3).
Эти алгоритмы сохраняют отображения матриц C, A и B соответственно.
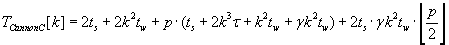 (2.1) (2.1)
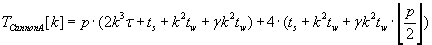 (2.2) (2.2)
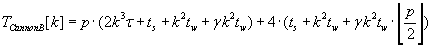 (2.3) (2.3)
Анализируя выражения (2.1), (2.2) и (2.3) можно однозначно сказать о превосходстве алгоритма Кэннона
с сохранением отображения блоков матрицы–сомножителя С. Его преимущество выражается в меньших
коммуникационных затратах по сравнению с другими двумя модификациями.
Алгоритмы семейства Фокса не меняют отображения блоков матриц–операндов и матрицы–результата
на узлы вычислительной решётки. Это значит, что предварительное и окончательное выравнивание блоков
строк/столбцов матриц не требуется.
Своеобразной платой за отсутствие необходимости выравнивания является необходимость осуществлять
широковещание соответствующих блоков одной из матриц по строкам/столбцам на каждом шаге алгоритма.
Как результат, это приводит к большим коммуникационным затратам в сравнении с алгоритмами семейства
Кэннона. Полное время выполнения обеих модификаций алгоритма Фокса определяется формулой (2.4).
Модификации будут обозначаться направлением широковещания блоков одной из матриц (строчное или
столбцовое широковещание).
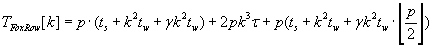 (2.4) (2.4)
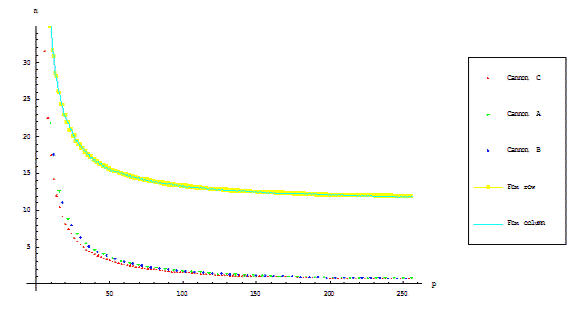
Сравнительный график времени выполнения алгоритмов представлен на рисунке 2.1. Размерность
блоков операндов фиксирована, число процессоров изменяется.
Рисунок 2.1 – Коммуникационная сложность алгоритмов (с учётом окончательного
выравнивания для алгоритмов Кэннона)
Как было отмечено ранее, отличия алгоритмов выражаются в различных коммуникационных затратах на
выполнение и конечным отображением блоков матриц на вычислительные узлы решётки после выполнения
расчётов. Представленные варианты алгоритма Фокса будут наихудшими в отношении времени выполнения,
чем алгоритмы семейства Кэннона. Данное утверждение подтверждается формулами (2.1)–(2.4).
Матричное произведение можно рассматривать как набор одновременно вычисляемых произведений исходной
матрицы на различные вектора (столбцы другой матрицы–операнда). Расчёт элементов различных столбцов
матрицы–результата может осуществляться одновременно.
В матрично–векторном произведении необходимо осуществить замену вектор–сомножителя на матрицу с
одинаковыми столбцами. В этом случае для расчёта вектора–результата умножения матрицы на вектор можно
использовать блочные алгоритмы вычисления матричного произведения. В этом случае результатом будет
выступать матрица с одинаковыми столбцами. Каждый столбец такой матрицы будет представлять элементы
результирующего вектора.
Полное время выполнения различных версий алгоритма Кэннона для вычисления матрично–векторного
произведения определяется формулами (2.5) – (2.7). Эти алгоритмы сохраняют отображения матриц C, A и
B соответственно.
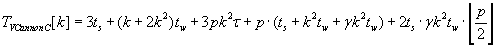 (2.5) (2.5)
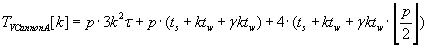 (2.6) (2.6)
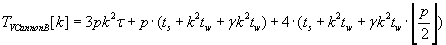 (2.7) (2.7)
Исходя из соотношений (2.5), (2.6) и (2.7), лучшие результаты в отношении времени выполнения будет
показывать алгоритм Кэннона с сохранением отображения блоков матрицы A на узлы вычислительной
решётки. Этот результат достигается за счёт обмена только блоками векторов в процессе выполнения
алгоритма.
Анализируя выражения (2.5) и (2.7) можно сделать однозначный вывод о превосходстве алгоритма Кэннона
с неизменным отображением блоков вектора C над алгоритмом Кэннона с неизменным отображением
блоков вектора B. Разница во времени выполнения алгоритмов определяется различием времён начального
и окончательного выравнивания блоков соответствующих векторов и матрицы A.
Полное время выполнения строчной и столбцовой версий алгоритма Фокса определяется формулами (2.8) и (2.9).
Сравнивая эти формулы можно сделать вывод о превосходстве столбцовой версии параллельного алгоритма
Фокса вычисления матрично–векторного произведения над строчной в отношении времени выполнения. Меньшие
показатели времени выполнения столбцовой версии алгоритма обеспечиваются за счёт уменьшения передаваемых
данных по сравнению со строчной версией.
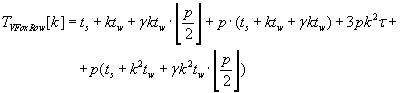 (2.8) (2.8)
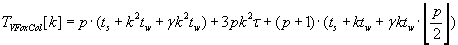 (2.9) (2.9)
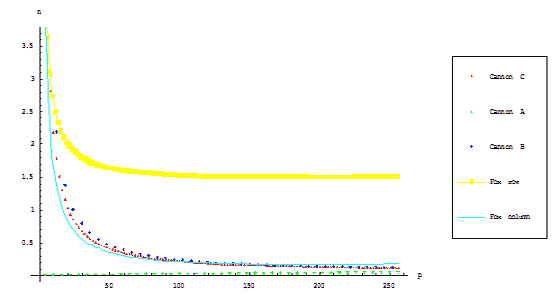
Рисунок 2.2 показывает графически показывает соотношение времён выполнения различных параллельных
алгоритмов умножения матрицы на вектор с фиксированной размерностью блоков операндов для различного
числа процессоров.
Рисунок 2.2 – Коммуникационная сложность алгоритмов (c учётом окончательного выравнивания для
алгоритмов Кэннона)
|