Реферат
Тема магистерской работы: "Динамическая оптимизация распределения данных по узлам вычислительной сети"
Выполнила: Баранова Светлана Сергеевна
Введение
Распределенные базы данных (РБД) получили широкое применение в условиях оптимизации организации и обработки больших объемов данных. Среди основных преимуществ распределенной базы данных можно выделить следующие:
Применение РБД позволяет отобразить структуру организации. Крупные организации, как правило, имеют множество отделений, которые могут находиться в разных концах страны и даже за ее пределами. Используемая этой компанией база данных должна быть распределена между ее отдельными офисами. В каждом отделении компании может поддерживаться база данных, содержащая сведения о персонале, сдаваемых в аренду объектах недвижимости, которыми занимаются сотрудники данного отделения, а также о клиентах, которые владеют или желают получить в аренду эти объекты. В подобной базе данных персонал отделения сможет выполнять необходимые ему локальные запросы. Руководству компании может потребоваться выполнять глобальные запросы, предусматривающие получение доступа к данным, сохраняемых во всех существующих отделениях.
Повышение доступности данных. В централизованных СУБД отказ центрального компьютера вызывает прекращение функционирования всей СУБД. Отказ одного из узлов СУРБД или линии связи между узлами сделает недоступным только лишь некоторые узлы, тогда как вся система в целом сохранит свою работоспособность. Распределенные СУБД проектируются таким образом, чтобы обеспечивать функционирование системы несмотря на подобные отказы. Если выходит из строя один из узлов, система сможет перенаправить запросы к отказавшему узлу в адрес другого узла. Если организована репликация данных, в результате чего данные и их копии будут размещены на более чем одном узле, отказ отдельного узла или соединительной связи между узлами не приведет к недоступности данных в системе.
Если данные размещены на самом нагруженном узле, то развертывание распределенной СУБД может способствовать повышению скорости доступа к базам данных. Более того, поскольку каждый узел работает только с частью базы данных, уровень использования центрального процессора и служб вво-да/вывода может оказаться ниже, чем в случае централизованной СУБД.
В распределенной среде расширение существующей системы осуществляется намного проще. Добавление в сеть нового узла не оказывает влияние на функционирование уже существующих. Перегрузка из-за увеличения размера базы данных обычно устраняется путем добавления в сеть новых вычислитель-ных мощностей и устройств дисковой памяти. В централизованной СУБД рост размера базы данных может потребовать замены и оборудования и используемого программного обеспечения.
На сегодняшний день технологии систем управления распределенными базами данных достигли того уровня развития, когда на рынке уже имеются достаточно развитые и надежные коммерческие системы. Но в то же время сегодня существует проблема повышения эффективности функционирования распределенных баз данных. Ключевым фактором, снижающим показатели функционирования РБД, является то, что коммуникационные сети, охватывающие большую территорию, пока остаются медленными. Поэтому основная задача распределенных систем состоит в том, чтобы минимизировать использование сетей, то есть минимизировать объем передаваемых данных или время их передачи.
Целью работы является повышение производительности работы РБД путем оптимизации распределения данных по узлам компьютерной сети. Для достижения поставленной цели требуется решить следующие задачи:Научная новизна заключается в следующем:
Изучив все особенности работы базы данных в СУРБД Oracle (распространение обновлений и выполнение запросов), а также, определив параметры РБД, которые можно собрать или получить с помощью существующих программных средств, разработать математическую модель оптимального распре-деления файлов по узлам компьютерной сети с целью минимизации общего времени выполнения запросов и распространения обновлений. Данная модель должна учитывать такие особенности распределенных баз данных, как фрагментацию и репликацию.
Учитывая, что важными при получении решения для базы данных в конкретной СУРБД, являются исходные данные, предполагается разработать инструментальное средство сбора статистической информации о процессах, происходящих при работе РБД (о временных параметрах распространения об-новлений и выполнения запросов).
Обзор источников по теме "Динамическая оптимизация распределения данных по узлам вычислительной сети"
Проблема оптимизации распределения данных получила достаточно широкое развитие. Этому вопросы посвящена диссертация
моего руководителя Телятникова А.О. Он разработал объектную модель динамической оптимизации распределения данных. Идея основана
на совместном использовании аппарата генетических алгоритмов и объектной модели РБД. Схема распределения фрагментов данных по узлам
РБД кодируется в виде набора хромосом. В процессе оптимизации с помощью операторов ГА генерируются хромосомы, то есть схемы
распределения данных. Полученные схемы являются исходной информацией для объектной модели, с помощью которой вычисляются оценки
критерия эффективности РБД. Эти оценки, в свою очередь являются значениями целевой функции ГА для данного варианта решения.
Входными данными для моделирования и оптимизации является статистика использования запросов и распространения обновлений,
а результатом – модифицированная схема распределения данных. В качестве критерия эффективности выбрано минимальное суммарное
среднее время выполнения запросов и распространения обновлений.
Пусть рассматриваемая РБД представляет собой множество фрагментов данных Ф={фi,i=1..n}, где n – количество фрагментов
данных в системе, которые при помощи репликации и фрагментации распределены на множестве узлов У={Уi,j=1..m},
соединенных множеством каналов передачи данных C={ck,k=1..Nc}. На узлах функционирует множество приложений
П={пr,r=1..Nп}, которые инициируют выполнение запросов и распространение обновлений. Схема распределения
данных в РБД определяется матрицей А, элементы которой принимают следующие значения:
![]()
В процессе функционирования РБД со схемой распределения, представленной матрицей А, порождается множество запросов
Q={qs,s=1..Nq} и множество обновлений U={ue,e=1..Nu} для элементов которых определенны функции
t’(qs,A) – время выполнения запроса qi (s=1,,Ns) и t’’(ue,A) – время распространения обновления
ue (e=1..Nu).
Задача оптимизации РБД сформулирована следующим образом: необходимо найти схему распределения данных, при которой суммарное среднее время
выполнения запросов и распространения обновлений, порожденных функционированием системы, минимально:
![]()
Времена выполнения запросов и распространения обновлений вычисляются с помощью объектной модели РБД.
Для ее реализации разработаны классы, характеризующие типовые компоненты РБД: узел, канал передачи данных, приложение, запрос.
При вычислении критерия оптимальности необходимо учитывать следующие ограничения:
- В РБД должны присутствовать хотя бы одна копия данных:
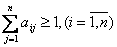
- Суммарный объем данных, хранящихся на узле, не должен превышать общее дисковое пространство данного узла:
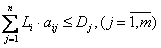
где Li – объем i-гo фрагмента данных, i=1..n; Dj – дисковое пространство j-го узла, j=1..m. - Максимальное время выполнения запросов не должно превышать заданного предельного значения:
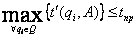
где tпр – предельно допустимое время выполнения запросов.
Данная модель является динамической, учитывает фрагментацию и репликацию данных, то есть соответствует современным требованиям. Но она не учитывает особенности реализации распределенной обработки в конкретной СУБД. Поэтому рассмотрим еще один подход к моделированию РБД – модель, подложенную И.Ахмадом.
При таком подходе проблема модель оптимизации распределения данных рассматриваетя как комплексная проблема. Предполагается, что существует взаимная зависимость между схемой распределения данных (которая показывает расположение каждого фрагмента на различных узлах базы данных) и стратегией оптимизации запросов (которая решает, как запрос может быть оптимально выполнен при данной схеме размещения). В модели вводится понятие графа зависимости фрагментов, который моделирует отношения между фрагментами и количество передаваемых данных, требуемых для выполнения запроса. Кроме графа, рассматриваемый алгоритм имеет следующие входные параметры: затраты на передачу данных между узлами, ограничение на размещение количества фрагментов на узлах, частота выполнения запросов от узлов. Результат – модифицированная схема распределения данных.
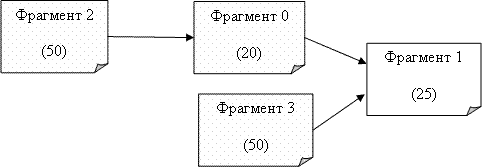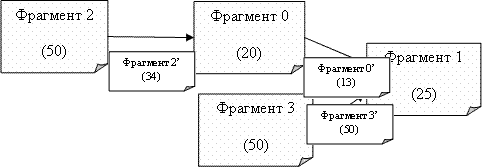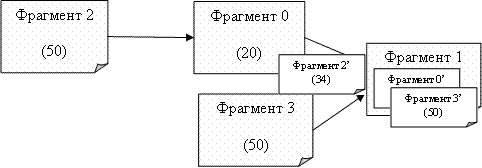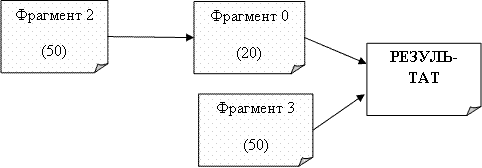
Анимация 1. Граф зависимости фрагментов.
Рассмотрим распределенную базу данных, состоящую из m узлов Si (i = 0..m-1), каждый из узлов имеет свою производительность, объем памяти, и локальную базу данных. Соединение между двумя узлами Si и Si' характеризуется целочисленной положительной переменной cii’ которая ассоциируется с затратами на передачу данных от узла Si к узлу Si'. Пусть существуют q = {q0, q1, … qn-1} – наиболее часто применяемые запросы. aix – частота, с которой запрос qxx выполняется на узле Si. Частота выполнения n запросов с m узлов может быть представлена с помощью матрицы А размером (m*n). В РБД существует k фрагментов данных {O0, O1, .. Ok-1}.
В модели рассмотрены два вида затрат на передачу данных. Первый тип затрат основан на перемещении данных из узла размещения на узел, инициирующий запрос. В этом случае размер фрагмента данных, запрощиваемых с каждого узла, не изменяется с расположением фрагментов данных и нет зависимости между доступными запросу фрагментами данных. rxj - размер фрагмента данных Oj которые нужно передать на узел, где запрос qx инициирован, в результате получим матрицу R размером (n*k). Запрос qx инициируется на сайте Si aix раз за определенный временной интервал. ТОгда U – матрица размером (m*k), где uij – количество данных, которые нужно передать с узла, где расположен фрагмент данных Oj на узел Si где запрос был инициирован:
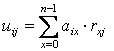
Второй тип затрат появляется когда данные с узла, где расположен один из фрагментов, передаются туда, где расположен второй фрагмент. Данные передаются в порядке выполнения бинарных операций, объединяющих два или более фрагментов данных. В данном случае количество данных фрагмента, запрошщиваемых с каждого сайта, зависит от расположения остальных фрагментов данных. Пусть djj' определяется как размер данных из фрагмента Oj который нужно передать на узел, где расположен фрагмент Oj', чтобы выполнить определенную бинарную операцию, получим матрицу передачи D размером (k*k). Она зависит от запроса, который должен быть обработан, то есть для каждого запроса мы должны знать информацию о том, какое количество данных нужно передать от узла, где расположен один фрагмент, на узел с другим фрагментом, при этом оба фрагмента данных должны быть доступны для выполнения запроса. Пусть zjj’x – размер данных узла Ojj, которые нужно передать на узел Oj’ для выполнения запроса qx, получим матрицу Zx. Количество данных, которые нужно передать с узла Oj на узел Oj' равно:
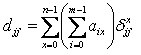
Пусть site(Oj) – это узел где расположен фрагмент данных Oj. Тогда, общие затраты на передачу равны:
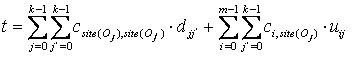
В этой формуле первое слагаемое означает затраты на передачу данных чтобы обработать бинарные операции между фрагментами данных, расположенными на различных узлах. Второе слагаемое представляет собой затраты на передачу данных чтобы передать результаты бинарных операций фрагментов данных на узел, где запрос был инициирован. Задача распределения данных состоит в минимизации t, изменяя значение site(Oj).
Итак, в модели учитываются два вида затрат на передачу данных. Это связано с применением в СУБД разных стратегий оптимизации распределенных запросов. Таким образом, в зависимости от особенностей конкретной СУБД можно учитывать тот или иной вид затрат. Но модель имеет и недостатки: она не учитывает наличие механизма обновлений. Однако то, что она рассматривает особенности функционирования конкретной СУРБД, позволит получить схему распределения данных, более точно соответствующую реальной среде. Таким образом, для исследвоания была выбрана модель, предложенную И.Ахматом. Применение этой модели, учитывающей особенности функционирования конкретной СУБД, позволит получить оптимальную схему распределения. В качестве среды выбираем СУБД Oracle. Для адаптации исходной модели к выбранной СУБД требуется изучить особенности реализации распределенных запросов и распространения обновлений в СУРБД Oracle.
Выводы
- Модели обладают рядом допущений и ограничений, которые делают невозможным их применение при анализе и оптимизации работы реальной РБД.
- Ранее применявшиеся методы оптимизации РБД – метод ветвей и границ, метод последовательных и пороговых улучшений и др., также не могут дать положительных результатов при оптимизации, так как их использование ограничено в связи с большой размерностью задачи распределения множества фрагментов данных по узлам компьютерной сети.
- Целесообразно применение эволюционных методов для решения задачи оптимизации распределения данных.
- Для решения задачи в модели оптимизации нужно учесть наличие механизма обновлений и фрагментации в РБД, а также особенности реализации распределенных запросов в конкретной СУБД.
Таким образом, несмотря на проведенные ранее исследования вопросы моделирования и оптимизации РБД компьютерных
информационных систем не получили окончательного решения, используемые модели и методы имеют ряд недостатков, что обусловило необходимость
их дальнейшего совершенствования.
В результате выполнения магистерской работы сделан обзор исследований по вопросу оптимизации распределения данных
по узлам вычислительной сети. Планируется получить такие результаты:
- Изучить особенности реализации РБД с использованием СУБД Oracle.
- Модифицировать модели распределенной базы данных.
- Модифицировать генетический алгоритм для решения задачи оптимизации
- Провести эксперименатальные исследования
Литература
- Цегелик Г.Г. Системы распределенных баз данных. – Львов: Свит, 1990. – 168 с.
- Т.Коннолли, К.Бегг. Базы данных: проектирование, реализация и сопровождение. Теория и практика. – М., 2000. – 1120 с.
- Телятников А.О. Разработка объектной модели распределенной базы данных// Наукові праці ДонНТУ. Випуск 74. – Донецьк, ДонНТУ, 2004. – с. 192 – 200.
- I. Ahmad, K. Karlapaem. Evolutionary Algorithms for Allocating Data in Distributed Database Systems//
http://ranger.uta.edu/~iahmad/journal-papers/[J39]%20Evolutionary%20algorithms%20for%20allocating%20data.pdf - Распределенные и параллельные системы баз данных. Системы управления базами данных, #04/1996 - http://www.osp.ru/dbms/1996/04/4.htm