Smith, J.R. and Shih-Fu Chang, Aibing Rao, Rohini K. Srihari, Lei Zhu, Aidong Zhang
Введение
Распространение цифровых средств обработки изображений, Internet и локальных вычислительных сетей обусловили накопление информации, представленной в виде изображений, которые, в зависимости от области применения, могут иметь произвольное содержание либо принадлежать к ограниченному классу. С другой стороны, ситуация, сложившаяся на рынке средств вычислительной техники, такова, что объем свободного дискового пространства для пользователей персональных компьютеров перестал быть критичным. Это привело к тому, что многие пользователи пренебрегают чисткой дисков, предпочитая хранить информацию «на всякий случай», получая в результате значительное количество файлов, практически идентичных по своему содержанию. Особенно острой эта проблема становится применительно к файлам, содержащим изображения, из- за их большого объема. Одной из первоочередных задач для таких коллекций является их систематизация по некоторым признакам, облегчающая дальнейший поиск и обработку. Таким образом, весьма полезной была бы программа, выделяющая группы файлов, содержащих визуально сходные между собой изображения. Такая программа должна представлять собой систему принятия решений, которая предоставляет пользователю наборы изображений, а пользователь, в свою очередь, может решать, какие из изображений, объединенных в группу, представляют для него ценность. Наибольший интерес в процессе такой классификации представляет сравнение содержимого изображений (под сравнением в данном случае понимается автоматическая установка соответствия между визуальными характеристиками двух или более изображений).
Рассмотрены существующие подходы к сопоставлению содержимого изображений, метод, основанный на использовании коэффициента корреляции гистограммных признаков, результаты программной реализации рассмотренного метода.
Подходы к сопоставлению содержимого изображений
Наиболее простым и исторически первым способом сравнения содержимого изображений было сопоставление их текстовых описаний. Главным недостатком такого способа является субъективность описания, поскольку оно составляется человеком. Кроме того, «ручное», весьма трудоемкое и длительное составление текстовой аннотации повышает стоимость реализации.
Первой попыткой автоматизации решения этой задачи было предложение сравнивать элементарные составляющие изображения-пиксели. Однако этот подход практически нереализуем из-за значительной пространственно - временной сложности: во - первых, объем коллекций изображений, как правило, очень велик, и, во - вторых, изображения состоят из миллионов пикселей, из-за чего для их попарного сравнения необходимо слишком много времени. Кроме того, при попиксельном сравнении изображений мелкие детали (в частности, отдельные различающиеся пиксели) могут сильно повлиять на результаты сравнения.
Наиболее перспективным является подход к сравнению изображений, предложенный в рамках работ, посвященных контекстному поиску изображений. В области разработки систем поиска изображений по их содержимому наибольший вклад внесли разработчики фирмы IBM (разработка QBIC, используемая, в частности, для поиска в оцифрованной коллекции Государственного Российского Эрмитажа), Колумбийского университета, США (Дж.Смит, Ш.-Ф. Чанг), компании Virage (А.Гупта и др). В соответствии с этим подходом, первоначально создается формальное описание изображения, а впоследствии выполняется анализ и обработка этого описания, а не самого изображения. Таким образом, доступ к изображению осуществляется только в момент его занесения в коллекцию и при визуализации результатов, а сам поиск осуществляется на основе характеристик изображения, вычисленных при его занесении в коллекцию и хранящихся вместе с ним (эти характеристики еще называют метаданными).
В качестве характеристик содержимого изображения используются как точечные (наиболее яркий, преобладающий либо средний цвет пикселей), так и гистограммные признаки (цветовые и текстурные гистограммы, коррелограммы, цветовые векторы). Наиболее часто для представления цветового содержимого используются гистограммные признаки, причем использование нормализованных цветовых гистограмм предпочтительнее за счет возможности обработки изображений произвольного размера.
Архитектуры систем контекстного поиска изображений и сравнение систем контекстного поиска изображений с точки зрения их функциональных возможностей рассматривались ранее. Их классификация приведена на рисунке 1.
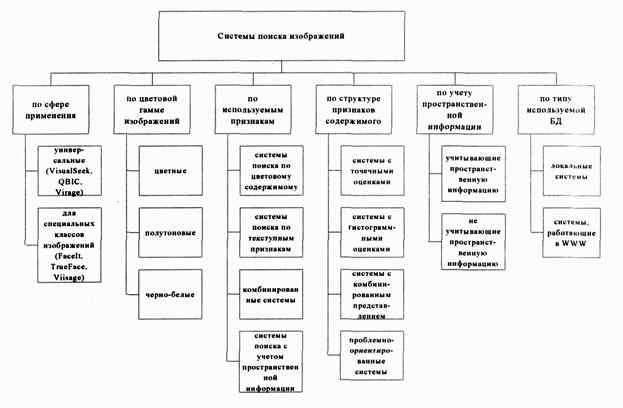
Рис. 1 – Классификация систем поиска изображений
Систематизация коллекции изображений
Систематизация коллекций изображений предполагает выполнение следующих этапов:
1. Анализ дискового пространства (одного или нескольких дисков, папки - по выбору пользователя) и формирование общего списка файлов- изображений.
2. Разбиение полученного списка на группы файлов (классы), содержимое которых сходно.
3. Предоставление пользователю результатов классификации, выполненной на предыдущем шаге.
Таким образом, задача классификации коллекции оцифрованных изображений может быть сведена к последовательному выполнению поиска изображений, похожих на заданный образец. При этом на каждой итерации поиска в качестве образца используется очередное изображение из коллекции, не включенное ни в один класс, а собственно поиск осуществляется также среди изображений, не подвергшихся классификации.
Выделение групп визуально сходных изображений
Описываемый подход к поиску предполагает использование для описания цветового содержимого изображения 2D- цветовых гистограмм, позволяющих учитывать не только количество пикселей каждого цвета, а и соотношение цветов пар пикселей.
Построение 2D- цветовой гистограммы предполагает использование базового набора цветов, используемого на этапе квантования, и некоторого шаблона пикселей в окрестности каждой точки изображения. В процессе вычисления элементов 2D- цветовой гистограммы каждая точка изображения, помещаемого в коллекцию, сравнивается с точками шаблона, и в процессе этого сравнения увеличиваются на единицу элементы 2D- цветовой гистограммы, соответствующие цветам сравниваемых точек.
Каждый элемент построенной таким образом гистограммы равен количеству пар пикселей с заданным соотношением цветов в окрестности точки для заданного шаблона. После построения выполняется нормирование элементов, что дает возможность сравнивать 2D- цветовые гистограммы, построенные для изображений различных размеров. Каждый элемент такой гистограммы H[i,j] представляет собой вероятность присутствия в изображении пары точек с цветами c[i] и сЦ], и в случае полноты используемого цветового пространства сумма элементов будет равна единице.
Для сравнения 2D- цветовых гистограмм изображений предлагается вычислять коэффициент их корреляции, так как 2Б-цветовая гистограмма, построенная по алгоритму, описанному выше, является случайным вектором.
Используемые в настоящее время характеристики для сравнения гистограммных признаков. В таблице 1 приведены выражения, определяющие область значений для наиболее популярных величин (конъюнкции цветовых и текстурных гистограмм, евклидова, косинусного и квадратичного расстояний). Легко увидеть, что максимальное значение расстояния между гистограммами определяется числом их элементов. При использовании же ненормализованных гистограмм значения этих величин сверху практически не ограничены. По этой причине расстояния сами по себе не отражают степень сходства изображений, для которых вычислены; они имеют значение только при сравнении с другими аналогичными величинами. Именно этим обусловлена черта, являющаяся общей для всех современных систем контекстного поиска: в качестве результатов поиска пользователю предъявляются все изображения из БД, отсортированные по убыванию сходства с образцом.
Практические предположения
Система принятия решений, реализованная на рассмотренных выше принципах, позволит выделить в составе коллекции ряд классов, объединяющих изображения, сходные с точки зрения цветового содержимого.
Заключение
Была выполнена классификация существующих систем поиска изображений, рассмотрены основные моменты, связанные с
применением коэффициента корреляции гистограммных признаков цветового содержимого изображений, влияние преобразований на результат сравнения. В дальнейшем исследования могут быть направлены на уточнение результатов сравнения путем учета информации о характеристиках отдельных объектов, входящих в изображение.
Литература
1. R. Smith, S.-F. Chang. VisualSeek: a fully automated content-based
image query system. // Proc. ACM Intern. Conf. Multimedia, Boston, MA.-1996.-P. 87-98.
2. Lu G. Techniques and Data Structures for Efficient Multimedia Retrieval
Based on Similarity/ЛЕЕЕ Transactions on Multimedia. -Vol. 4, No.3. -2002.-P. 372-384.
3. Aibing Rao, Rohini K. Srihari, Lei Zhu, Aidong Zhang. A method for
measuring the complexity of image databases.//IEEE Transactions on Multimedia. - Vol. 4, No.2. -2002. - P. 160-173.
9. Гмурман В.Е. Теория вероятностей и математическая статистика,-
М.:Высшая школа, 1972 -479 с. |


