|
Abstract
"Parallel methods for solving systems of linear algebraic equations
on a computer cluster"
INTRODUCTION
To date,
the performance of computing systems to a large increase is
not so much by increasing the frequency of the devices, but
at the expense of parallel processing [1-3]. This process
involves the establishment of hardware (processors with
multiple ALU, communication equipment for multiprocessor
systems, etc.) and develop efficient algorithms for various
parallel platforms. Today's parallel systems is very
expensive and are used to solve problems that require large
computational resources: the predictions of weather and
climate, construction of semiconductor devices, the study of
the human genome.
Anyway, there is possibility of creation the cheap is enough
and in relation to the effective parallel system on the base
of ordinary computers, united through an of communication
equipment and, thus, formative one calculable resource. Such
systems are named clusters and behave to the class of
the parallel systems with the distributed memory [1,3]. The
bottleneck of clusters is that for co-operation of separate
knots the most widespread and cheap of communication
equipment (Fast Ethernet) which utillizes the general
environment of communication of data and possesses a large
carrying capacity not very much is attracted (by comparison
to speed of processing of data modern processors). Therefore
the circle of tasks, decided on the similar systems, is
limited to the tasks with the small number of exchanges as
compared to the amount of calculations. Undeniable advantage
of the similar systems is their relative cheapness and
actual presence of large computer classes in many
educational establishments. For programming of the similar
systems the systems of passing of messages in which separate
computers co-operate by means of transmission and reception
of information are used.
To date, the most popular standard is MPI (message passing
interface - the interface of communication) [1-3]. Specific
implementations of MPI standard are established producers of
software and supplied with equipment. Most standard
implementations of MPI called MPICH. This standard describes
the names and call the result of the procedures. For each
parallel system with the transfer of communications has its
own optimized MPI implementation, and to write the program
portable between different systems on the MPI source code.
To write MPI programs using modern programming languages
such as C / C + + and Fortran.
Research in the MPI
programming are presented in two directions: the creation of
efficient parallel algorithms and efficient implementations
of MPI standard for cluster systems. Parallel algorithms
developed from the low speed data transmission in connection
with the preferred method with the smallest number of
exchanges. Ongoing implementation of MPI for cluster systems
implemented through exchanges of protocol TCP / IP [4],
which leads to the impossibility of effective use of
broadcast exchanges, which in the current implementation are
carried out through the paired exchange. Today, therefore,
are working on the creation of MPI implementation in a real
broadcast peresylok. Another possibility to increase the
productivity of MPI programs - the combination of exchange
and calculations, but used in the implementation of this
technology does not lead to significant improvements.
This work is dedicated to
the creation of efficient parallel algorithms for the
conjugate gradient method for symmetric positive definite
pyatidiagonalnyh systems of linear algebraic equations.
Systems of this kind occur when konechnoraznostnoy
approximation of partial differential equations. To date,
developed a large number of efficient sequential algorithms
of this type [1]. However, most of them unacceptable for a
parallel implementation. This is due to their recursive
nature, and, hence, a small overlap.
The aim of this work is to study the existing
sequential and parallel algorithms for the conjugate
gradient method, the selection of them, as well as the
creation of efficient algorithms for the conjugate gradient
method, suitable for use in cluster systems.
The work has been studied a large number of conjugate
gradient algorithms. When choosing a method for the study in
preference to the methods with a minimal number of
interprocessor exchanges. As a result of this was allocated
to three classes of techniques: block-diagonal methods,
techniques and methods of polynomial approximation of the
inverse matrix.
The results showed that while the goal for the
clusters of large size appropriate to use methods with a
minimal number of exchanges, and on clusters of small size -
the methods have better convergence.
1.Computing Cluster
Cluster - is associated a set
of full-fledged computers, used as a single computational
resources [1,2].
As a cluster of computational nodes used are available on
the market one, two or four computers. Each node of such a
system is running its copy of the operating system, as has
most often been used standard operating systems: Windows,
Linux, Solaris, etc. The composition and output node cluster
can vary, giving the ability to create non-uniform systems
[1,2].
As a communication protocol in such
systems using standard protocols of LAN characterized by low
cost and low-speed data transmission. The main
characteristics of communication networks: latency - the
time of the initial delay in sending messages and network
bandwidth, which determines the rate of transmission of
information via communication channels [1,2]. The presence
of latency determines that the maximum speed of data
transmission over the network can not be achieved in
communications with a small length. The most commonly used
network Fast Ethernet, the main advantage of which - the low
cost of equipment. However, large overhead to the
transmission of messages in the Fast Ethernet lead to severe
restrictions on the range of tasks that can be effectively
addressed in this cluster. If the cluster is more universal,
then you need to move to more productive communication
networks, for example, SCI, Myrinet, etc.
As a means of parallel programming in clusters, using
different systems of communication through which the
interaction between the cluster nodes. The most common to
date standard software systems for the transfer of messages
is MPI. The specific implementation of MPI is created
parallel systems of manufacturers and comes with hardware.
A cluster of department computers, which have been studied
(Figure 1.1)
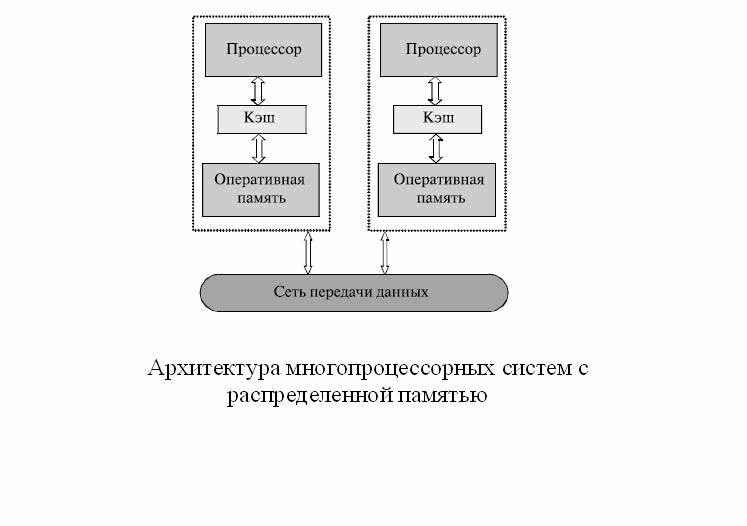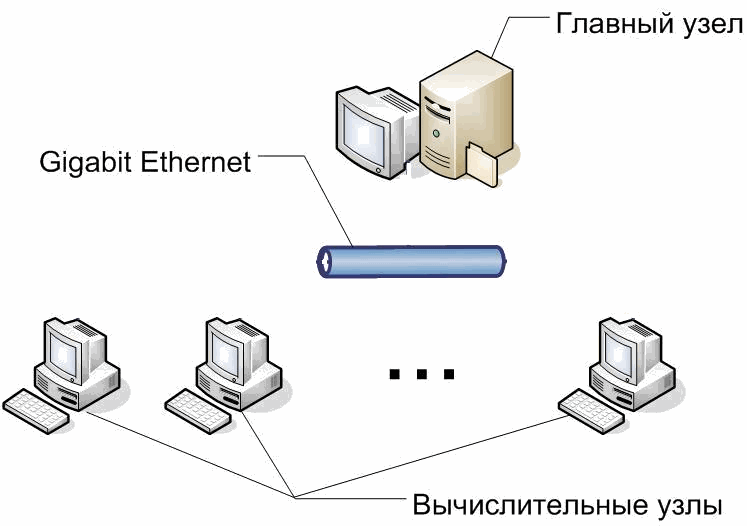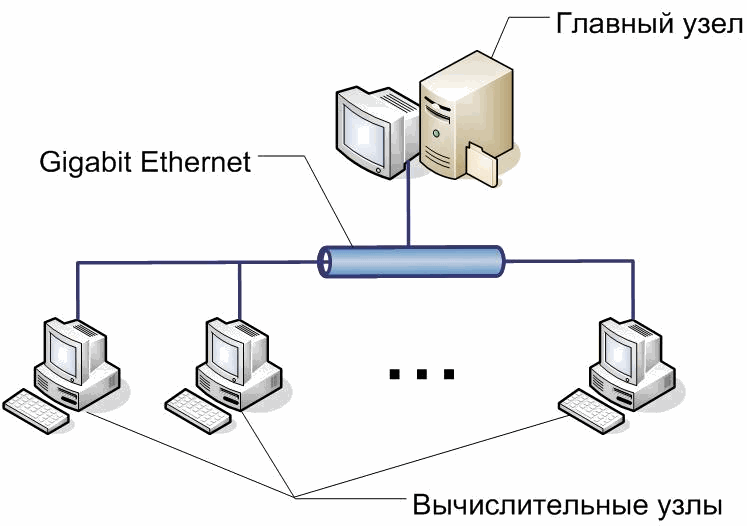
Figure 1. Structure of the
cluster
The structure of the cluster consists of
-
1 head node.
-
11 computer
nodes.
-
network
interface is Gigabit Ethernet, 1 Gbit / c.
-
Cluster
software - Microsot Windows Compute Cluster Server 2003.
-
Programming
languages - C \ C + +, Fortran.
-
Concurrent
programming - MPI.
Specifications cluster
Characteristics of the principal and computing nodes
1. Processor: Intel Pentium Core2 64bit, 1.86 GHz
2. RAM: 1 GB
3. Hard drive: 80 GB
4. Network Interface: Gigabit
Ethernet, 1 Gb / s
5. Operating System: Microsoft
Windows Server 2003Enterprise x64 Edition SP2
2.Interfeys data transfer (message passing interface - MPI)
To organize the information exchange between
processors in the minimum version to send and receive
operations data (in this case, of course, there must be a
technical possibility of communication between the
processors - channels, or lines). In MPI, there is a whole
lot of data transfer operations. They provide a different
way of sending data. It is this capability are the most
strength of the MPI (this, in particular, shows the title
and MPI).
This method
of parallel computing has received the name of the model of
"one program a lot of processes" (single program multiple
processes or SPMP1)).
The
development of parallel programs using MPI [2-4].
·
MPI allows largely to reduce the
sharpness of problem of bearableness of the parallel
programs between the different computer systems – the
parallel program, developed in algorithmic language of C or
FORTRAN with the use of library of MPI, as a rule, will work
on different calculable platforms;
·
MPI assists the increase of efficiency
of parallel calculations, as presently practically for every
type of the computer systems there is realization of
libraries of MPI, in a maximal degree taking into account
possibilities of computer equipment;
·
MPI diminishes, in a certain plan,
complication of parallel program development, ò. to to.,
from one side, and de autre part, already there is plenty of
libraries of parallel methods, created with the use of MPI.
3.Classification of parallel methods for
solving SLAE.
The method of Gauss-Seidel. Decide the system
is presented in the form [1-2]
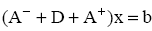
Iterative Gauss-Seidel scheme can
be seen from the submission system:
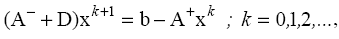
or
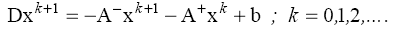
Here is the method of Gauss-Seidel to the standard mean:
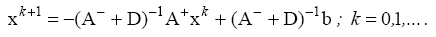
The standard form of the method allows it to deliver an
iterative matrix and hold it over the obvious
transformations:
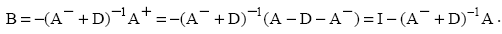
Suppose the Gauss-Seidel method in the form of coordinates
for a system of general form:
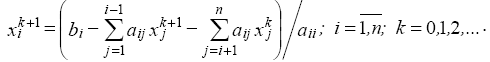
Coordinate form of Gauss-Seidel differs from Jacobi
coordinates form method, only that the first sum on the
right side of the iterative formula contains components
of the vector of solutions is not at k-th, and at (k
+1)-th iteration.
A parallel algorithm for Gauss-Seidel
The difference between the method of Gauss-Seidel method of
simple iteration is that the new vector of values calculated
not only on the basis of the previous iteration, and using
the values already calculated at the current iteration.
The text of a coherent program for calculating the new
values of vector components is presented below.
void GaussZeidel (double * A, double * X, int size)
/ * Set matrix A, the initial approximation of the vector X
dimension of the matrix size, calculate the new value of the
vector X * /
double Sum;
for (i = 0;
i < size; ++i) {
Sum = 0;
for (j = 0;
j < i; ++j)
Sum +=
A[ind(i,j,size)] * X[j];
for (j =
i+1; j < size; ++j)
Sum +=
A[ind(i,j,size)] * X[j];
X[i]=(A[ind(i,size,size)]
– Sum) / A[ind(i,i,size)];
}
}
Fig. 2. The
procedure for calculating the values of the vector using
the Gauss-Seidel
The following system of equations describes the method
of Gauss-Seidel.

Calculations of each depend on the coordinates of a vector
of values calculated at the previous iteration, and a vector
of values calculated at this iteration. It therefore can not
be implemented parallel algorithm, similar to the method of
simple iteration: each process can not begin until the
computation is not finished calculating the previous
process.
It is possible to propose the
following modified method of Gauss-Seidel iteration for
parallel implementation. Divide calculating coordinates of a
vector of processes similar to the method of simple
iteration. We will be in each process to calculate a number
of vector coordinates using Gauss Seidel, using only the
calculated values of the vector of the process. The
difference in the parallel implementation compared with the
method of simple iteration is only in the procedure for
calculating the values of the vector (instead of procedure
Iter_Jacoby use the procedure
Gauss-Seidel).
void
GaussZeidel(int size, int MATR_SIZE, int first)
/ * Set matrix A, the dimension of the
matrix MATR_SIZE, the number of
computed elements of the vector in the process size,
calculate the new
values of the vector X with the number first, using the
vector X * /
{ int i, j;
double Sum;
for (i = 0;
i < size; ++i) {
Sum = 0;
for (j = 0;
j < i+first; ++j)
Sum +=
A[ind(i,j,MATR_SIZE)] * X[j];
for (j =
i+1+first; j < MATR_SIZE; ++j)
Sum +=
A[ind(i,j,MATR_SIZE)] * X[j];
X[i+first]=(A[ind(i,MATR_SIZE,MATR_SIZE)]
– Sum) /
A[ind(i,i+first, MATR_SIZE)];
}
}
Fig. 1. The procedure for
calculating the values of the vector using the Gauss-Seidel
(parallel version)
4.Napravleniya further research
• Develop a software system for
parallel solutions to the cluster
SLAE.
• Compare the effectiveness of
various parallel methods for solving the cluster
SLAE.
Literature
1. Programming for multiprocessor systems in
the standard MPI: Benefit / GI Shpakovsky, NV Serikova. - Mn.:
BSU, 2002. - 323s.
2.
Theory and practice of parallel computing: a manual / VP
Гергель .- M.: Internet-University of Information
Technology; Bin. Laboratory knowledge, 2007.-423s.
3. Computer networks. The principles, technology, protocols
/ VG Olifer, NA Olifer. - St. Petersburg: Piter, 2001. -
672s.
4. Concurrent programming using Open MP.-M.:
Bin. Laboratory knowledge Inta., 2008 .- 118s.
5. Group W, Lusk E, Skjellum A. Using MPI. Portable
Parallel Programming with the Message-Passing Interface.
- MIT Press, 1994. (http://www.mcs.anl.gov/mpi/index.html)
6. Parallel
information technology: a manual / AB Barsky-M.:
Internet-University of Information Technology; Bin.
Laboratory knowledge, 2007.-504s.
7. VD Korneev
Concurrent programming in MPI. Moscow - Izhevsk:
Institute of Computer Science, 2003. - 304 pp.
8. Miller, R., Boxer LA
Serial and parallel algorithms: A general approach. -
M.: Bin. Laboratory of Knowledge, 2006. - 406 pp.
9. on the international
conference on high performance computing (http://www.supercomp.de)
10. Antonov AS Parallel programming
using MPI: A manual (http://parallel.ru/tech/tech_dev/MPI/)
| 

{kind=link}