
|
 |
 |
 |
 |
Безуглый Евгений Николаевич Факультет вычислительной техники и информатики Специальность: Системное программирование Тема выпускной работы: Повышение эффективности поисковых систем Руководитель: Аноприенко А.Я. |
| Биография Библиотека Отчет о поиске Ссылки Инд. задание |
Реферат по теме выпускной работы
Научный руководитель: Аноприенко Александр Яковлевич
|
1. Введение |
|
В связи с большим ростом объемов информационных носителей становится возможным запоминание все больших объемов данных. Постоянно увеличивающиеся объемы информации облегчают работу человека.
На основе большего количества данных вычислительным машинам становится легче прогнозировать, анализировать и изучать новые факты, связанные с различными сферами деятельности человека. Однако помимо получения новых данных, как и прежде, остается актуальным вопрос поиска адекватной информации. Процесс поиска информации состоит их нескольких этапов[5]:
Анимация 1 Обобщенная схема поисковой системы (17 кадров, бесконечный цикл, размер: 12кб) Основной идей построение поисковых систем было создание индекса, представляющего собой некую базу данных, в которой ставиться соответствие между существующими частями документов (словами, термами) и самими документами, т.е. там, где эти слова встречаются. На основе этих индексов действуют несколько моделей поиска. Классическими моделями являются модели: булевская модель и векторная модель. |
|
2. Теоретико-множественные модели 2.1 Булевская модель |
| Булевская модель является самой простой моделью, основанной на булевской алгебре[2]. Согласно этой модели, выполняется поиск в индексе, представленный как матрица документов и термов (слов), и над множествами результатов поиска выполняются основные логические операции: И, ИЛИ, НЕ. Полученный результат подвергается ранжированию. |
|
2.2 .Векторная модель |
|
Основной идей этой модели является представление
документов и запросов в виде векторов[6].
Каждому терму в документе и запросу ставится в соответствии неотрицательный вес.
Таким образом, каждый запрос и документ может быть представлен в виде к-мерного
вектора. Dj = (w1jw2j,...,wkj), где Dj – j-й документ, wij– вес, i-го терма в j -м документе. Близость запроса к документу может быть вычислена, например, как скалярное произведение соответствующих векторов описаний [2]. Существует множество способов представления весов. Одним из таких может служить нормализирована частота данного терма в документе, - отношение количества повторений терма к общему количеству слов в документе. |
|
3. Вероятностная модель |
|
Каркасом для таких моделей выступает теория вероятностей. В качестве оценки релевантности
документа запросу пользователя используется вероятность того, что пользователь признает
документ истинно релевантным. Вероятностная модель поиска базируется на теоретических подходах байесовских условных вероятностей. Основным подходом вероятностной модели является вероятностная оценка веса термов в документе. С другой стороны, в качестве оценки соответствия документа запросу используется вероятность того, что пользователь признает документ релевантным. При описании вероятностной модели, как и ранее, используется словарь массива, включающий все термы, встречающиеся хотя бы в одном документе из информационного массива. Документу сопоставляется вектор x = (t1,..., tn), компонента i которого равна 1, если терм i входит в данный документ и 0 в противном случае. Здесь, как и ранее, терм задается своим порядковым номером в словаре, а n - общее количество термов в словаре коллекции. В канонической вероятностной модели используется упрощение, заключающееся в предположении (в общем, неточном) независимости вхождения в документ любой пары термов. При ранжировании документов в выборке ключевым являет "принцип ранжирования вероятностей", согласно которому если каждый ответ поисковой системы представляет собой ранжированный по убыванию вероятности полезности для пользователя список документов, то общая эффективность системы для пользователей будет наилучшей. |
|
4. Алгебраическая модель |
| В рамках алгебраических моделей документы и запросы описываются в виде векторов в многомерном пространстве. Каркасом для таких моделей выступают алгебраические методы. |
| 5. Недостатки некоторых моделей |
|
|
|
|
Приведенные классические модели изначально предполагали рассмотрение документов
как множества отдельных слов, не зависящих друг от друга. Такая упрощающая концепция
имеет название «Bag of Words».
В реальных системах это упрощение преодолевается, например, расширенная булева модель учитывает контекстную близость (операторы near, adj во многих известных системах ). Системы базирующиеся на вероятностной модели учитывают вхождение словосочетаний и связи отдельных терминов, хотя большинство из известных систем борьбы со СПАМом, построенные на вероятностной модели все-таки базируются на упрощенном подходе независимости отдельных слов. |
|
6. Латентно-семантический анализ |
|
Латентно-семантический анализ (LSA) -- это теория и метод для извлечения контекстно-зависимых значений слов при помощи статистической обработки больших наборов текстовых данных[4]. В течение нескольких последних лет этот метод не раз использовался как в области поиска информации, так и в задачах фильтрации и классификации. Латентно-семантический анализ основывается на идее, что совокупность всех контекстов, в которых встречается и не встречается данное слово, задает множество обоюдных ограничений, которые в значительной степени позволяют определить похожесть смысловых значений слов и множеств слов между собой. Мощным инструментом в латентно-семантическом анализе выступает WordNet. Этот механихм представляет из себя особый тип словаря, в котором все слова упорядочены в дерево, в котором родителями выступают более общие понятия, а листьями выступают более конкретные понятия. Кажды лист в таком дереве содержит множество синонимов (если имеет). Все синонимы связаны между собой так, что зная один, можно легко определить все остальные. Эта идея является основополагающей в "интелектуальном" поиске. Кроме мощного механизма SynSet'ов (множество синонимов), WordNet имеет также зависимости типа меронимии (подкласс), гиперонимии (надкласс), гипонимии (часть), холонимии (целое), а также антонимии (противоположность). Оперируя такими данными на основе всего лишь одного слова, можно получить большее количество релевантных документов, при чем не точным совпадением слова, а смысловым. WordNet содержит также случаи использования рассматриваемого слова. При чем, может также содержать устойчивые выражения (совокупность или комбинация слов может иметь иной смысл, чем слова по отдельности). Этот факт приводит к идее индексирвания не отдельных слов, целых понятий, что дает огромные надежды на повышение эффективности поисковых систем. Механизм WordNet целесообразно применять даже в векторной модели поиска. При чем, индекс будет содержать не частоту того или иного слова в документе, а величину, характеризирующую проекцию слова на определенный уровень дерева (WordNet). Затем, как обычно в векторной модели, вычисляется степень похожести векторов (расстояние или косинус угла). Результатом будет служить величина, характеризующая смысловое подобие запроса к документу. Наибольшую эффективность механизм достигается при использовании его в алгоритме LSA. В качестве исходной информации LSA использует матрицу термы-на-документы, описывающую используемый для обучения системы набор данных. Элементы этой матрицы содержат частоты использования каждого терма в каждом документе. Наиболее распространенный вариант LSA основан на использовании разложения матрицы по сингулярным значениям (SVD) . Используя SVD, огромная исходная матрица разлагается во множество из К, обычно от 70 до 200, ортогональных матриц, линейная комбинация которых является неплохим приближением исходной матрицы. Более формально, согласно теореме о сингулярном разложении, любая вещественная прямоугольная матрица X может быть разложена в произведение трех матриц: |
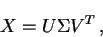 [4]
[4] |
|
Такое разложение обладает замечательной особенностью: если в
Основная идея латентно-семантического анализа состоит в том, что если в качестве X использовалась матрица термы-на-документы, то матрица X', содержащая только K первых линейно независимых компонент X, отражает основную структуру ассоциативных зависимостей, присутствующих в исходной матрице, и в то же время не содержит шума. Таким образом, каждый терм и документ представляются при помощи векторов в общем пространстве размерности K (так называемом пространстве гипотез). Близость между любой комбинацией термов и/или документов может быть легко вычислена при помощи скалярного произведения векторов. Выбор наилучшей размерности K для LSA -- открытая исследовательская проблема. В идеале, K должно быть достаточно велико для отображения всей реально существующей структуры данных, но в то же время достаточно мало, чтобы не захватить случайные и маловажные зависимости. Если выбранное K слишком велико, то метод теряет свою мощь и приближается по характеристикам к стандартным векторным методам. Слишком маленькое K не позволяет улавливать различия между похожими словами или документами. Исследования показывают, что с ростом K качество сначала возрастает, а потом начинает падать. |
|
7. Итоги |
|
В рамках каждого из классов было предложено множество альтернативных моделей. Несмотря
на ряд недостатков, на практике классические теоретико-множественные модели довольно
популярны в силу своей простоты. Хотя вероятностные модели предлагают наиболее естественный способ формально описать проблему информационного поиска, их популярность относительно невелика. Наиболее популярными являются алгебраические модели, поскольку их практическая эффективность обычно оказывается выше. Вообще говоря, предлагаемые в последнее время новые реализации проектов информационного поиска зачастую являются гибридными моделями и обладают свойствами моделей разных классов, что дает им гибкость и высокую эффективность. |
|
Библиография |
|